
爬蟲入門到放棄系列01:什麼是爬蟲
阿新 • • 發佈:2021-02-01

## 序章
18年初,還在實習期的我因為工作需求開始接觸Java爬蟲,從一個網站爬取了163W條poi資料,這是我人生中寫的第一個爬蟲,也是唯一的一個Java爬蟲。後來這些poi資料也成了我畢業設計中的一部分。後來開始學習Python爬蟲以及爬蟲框架Scrapy,尤其是Scrapy,前前後後研究了一個多月,並利用Scrapy構建了千萬級資料的ICA(網際網路內容識別)資源庫。
寫爬蟲系列的目的主要是想記錄一下自己學習爬蟲的經歷,以及遇到的一些問題,也希望能夠給爬蟲初學者帶來一些啟示。之前給同事普及爬蟲的時候,自己動手做了人生中的第一個PPT,所以爬蟲系列文章將圍繞著這個PPT來開展。
## 系列結構

如圖,將從四個方面來介紹爬蟲。
1. 爬蟲入門:主要包括爬蟲的基本概念、技術棧、爬蟲程式的開發等。
2. 反爬技術:主要是講述常見的反爬蟲技術以及應對方法。
3. Scrapy框架:目前最好的爬蟲框架,也是本系列文章的重點內容。
4. 風險規避:講述如何編寫規範的爬蟲,如何避免資料風險。
## 前言
很多人包括我在內,剛開始聽到爬蟲的時候都會有一種朦朦朧朧、遙不可及的感覺。很多人覺得只有程式設計師才需要使用爬蟲,其實並不是。至少,Python處理文件和爬蟲的能力是面向日常工作的。
舉個栗子:有人需要每天從各個網站上貼上成百上千條資料到excel中,如果使用爬蟲,一個requests、pandas或xlwt就搞定了,幾十行程式碼而已。日常上線需求需要根據模板來寫三個文件進行上傳,前前後後貼上需要四五分鐘,後來我為了偷懶用Python寫了個程式打包成exe,點選一下幾秒就完成了。所以,Python讓日常工作工作更高效,值得更多的人學習。
本篇文章主要從第一章爬蟲入門開始講起。

## 爬蟲概念

*什麼是爬蟲?*
這是當初我學習開發爬蟲的時候,腦海裡浮現的第一個問題。不論網上怎麼介紹爬蟲,是spider、crawler也好,是robots也罷。我的理解就是:**模擬人的行為從網頁上獲取的資料的程式**。更具象一些:在Java中爬蟲是Jsoup.jar,在Python中爬蟲是requests模組,甚至Shell中的curl命令也可以看做是爬蟲。
爬蟲庫可以分為兩個部分。一是請求部分,主要負責請求資料,例如Python的requests;二是解析部分,負責解析html獲取資料,例如Python的BS4。
*爬蟲做了什麼工作?*
模仿人的行為從網頁獲取資料。一個人,需要先開啟瀏覽器、輸入網址,從網站後臺獲取網頁並載入到瀏覽器展示,最後才能獲取資料。爬蟲的請求部分,就相當於瀏覽器的角色,會根據你輸入的url從網站後臺獲取html,而解析部分就會根據預先設定的規則,從html中獲取資料。
而開發者的工作,一是裝飾請求部分,例如在請求頭中新增User-Agent、Cookie等,讓網站覺得是一個人通過瀏覽器來訪問的,而不是一個程式。二是通過選擇器來編寫規則,從頁面獲取資料。
這是瀏覽器的請求頭內容。

## 技術棧

做爬蟲需要什麼具備什麼樣的技術?是不是隻有大佬才可以?其實並不是。這裡主要分為兩個層次要求。
### 基本要求
程式語言:只需要有Java或者Python基礎即可,有基本的Html閱讀能力以及CSS選擇器、Xpath選擇器、正則表示式的使用能力。
資料儲存:爬取的資料要只有儲存下來才有意義。資料可以儲存在檔案或資料庫中,這就要求開發者有檔案讀寫或資料庫操作的能力。對於資料庫,掌握基本的表結構設計、增刪改查的能力即可。
開發者工具:爬蟲開發者使用最多的工具,各種瀏覽器按下F12都會彈出。通常用來攔截請求,定位元素,檢視JS原始檔。
### 進階要求
在爬蟲的開發中,會遇到各種各樣的問題,就需要有獨立思考和解決問題的能力。目前,很多網站都採用了非同步載入資料或JS加密,所以需要具備Ajax和JS方面的知識。
網路知識。基本的狀態碼:20x成功,30x轉發重定向,40x請求不存在、50x服務端問題。有時候還需要TCP的知識,例如established、time_waited等TCP連線狀態代表著什麼。
## 爬蟲開發
基礎概念我們已經講完,怎麼來開發個爬蟲呢?舉個栗子:

如圖,是星斗蒼涼、月色照亮的動漫斗羅大陸的播放頁面。我們以此為例,開發爬蟲來獲取頁面資料。
### Java爬蟲
Java爬蟲的開發主要使用Jsoup。
引入Jsoup依賴:
```java
```
程式開發:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class JavaCrawler {
public static void main(String[] args) throws IOException {
String url = "https://v.qq.com/detail/m/m441e3rjq9kwpsc.html";
// 發起請求,獲取頁面
Document document = Jsoup.connect(url).get();
// 解析html,獲取資料
Element body = document.body();
Element common = body.getElementsByClass("video_title_cn").get(0);
String name = common.getElementsByAttribute("_stat").text();
String category = common.getElementsByClass("type").text();
Elements type_txt = body.getElementsByClass("type_txt");
String alias = type_txt.get(0).text();
String area = type_txt.get(1).text();
String parts = type_txt.get(2).text();
String date = type_txt.get(3).text();
String update = type_txt.get(4).text();
String tag = body.getElementsByClass("tag").text();
String describe = body.getElementsByClass("_desc_txt_lineHight").text();
System.out.println(name + "\n" + category + "\n" + alias + "\n" + area + "\n" + parts + "\n" + date + "\n" + update + "\n" + tag + "\n" + describe);
}
}
```
### Python爬蟲
對於Python爬蟲的開發,使用的是requests和bs4。
安裝模組:
```
pip install requests bs4
```
程式開發:
```python
import requests
from bs4 import BeautifulSoup
url = 'https://v.qq.com/detail/m/m441e3rjq9kwpsc.html'
# 發起請求,獲取頁面
response = requests.get(url)
# 解析html,獲取資料
soup = BeautifulSoup(response.text, 'html.parser')
name = soup.select(".video_title_cn a")[0].string
category = soup.select("span.type")[0].string
alias = soup.select("span.type_txt")[0].string
area = soup.select("span.type_txt")[1].string
parts =soup.select("span.type_txt")[2].string
date = soup.select("span.type_txt")[3].string
update = soup.select("span.type_txt")[4].string
tag = soup.select("a.tag")[0].string
describe = soup.select("span._desc_txt_lineHight")[0].string
print(name, category, alias, parts, date, update, tag, describe, sep='\n')
```
上面兩個程式輸出相同的結果:

至此,斗羅大陸的爬蟲開發工作就完成了。從程式碼也能看出來,請求部分也就一行,大部分都是解析部分的,這裡使用css選擇器來完成資料的解析。
我們再來看看請求部分獲取的網頁內容:
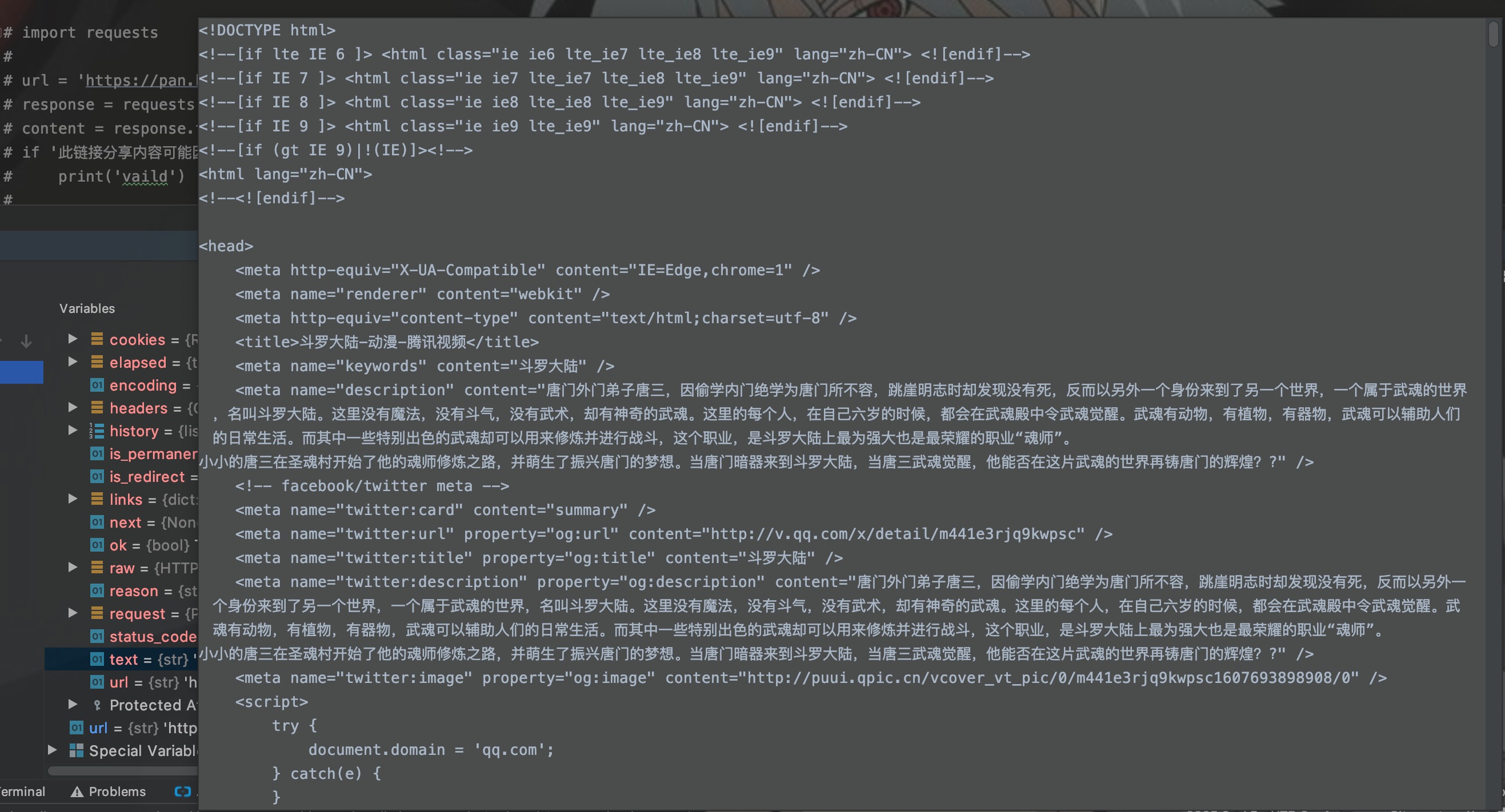
當然,一個完整的爬蟲程式除了以上模組,還需要有儲存模組,必要的時候還需要代理池模組。其次,對於整個大型網站資料的爬取還需要對網站進行深度/廣度遍歷來完成,還需要考慮到如果爬蟲中斷,如何從斷點開始繼續爬取等方面的設計。這一部分的內容後面會寫。
對於Jsoup資料、requests、scrapy視訊教程,公眾號後臺回覆 **爬蟲資料** 即可獲取。
## 結語
這一篇文章不對程式的開發做過多的深入探討,只講述爬蟲的概念以及程式演示。而下一篇文章會根據上面的程式,著重對Jsoup和requests、bs4模組以及css選擇器的使用深入探究。期待下一次相遇。
--- 寫的都是日常工作中的親身實踐,處於自己的角度從0寫到1,保證能夠真正讓大家看懂。 文章會在公眾號 [**入門到放棄之路**] 首發,期待你的關注。 
--- 寫的都是日常工作中的親身實踐,處於自己的角度從0寫到1,保證能夠真正讓大家看懂。 文章會在公眾號 [**入門到放棄之路**] 首發,期待你的關注。 