
分析 BAT 網際網路巨頭在大資料方向佈局及大資料未來發展趨勢
阿新 • • 發佈:2021-02-03
> 風起雲湧的大資料戰場上,早已迎百花齊放繁榮盛景,各大企業加速跑向“大資料時代”。而我們作為大資料的踐行者,在這個“多智時代”如何才能跟上大資料的潮流,把握住大資料的發展方向。
### 前言
大資料起源於2000年左右,也就是網際網路高速發展階段。經過幾年的發展,到2008年 Hadoop 成為 Apache 頂級專案,迎來了大資料體系化的快速發展期,到如今 Hadoop 已不單單指一個軟體,而成為了大資料生態體系的代名詞。
自2014年以來,國內大資料企業層出不窮,可以用“亂花漸欲迷人眼”形容現狀,也是在這一年,我國《政府工作報告》首次提出“大資料”,大資料作為一種新興產業正式登陸中國舞臺。之後,又上升至國家戰略。自此“大資料”這三個字頻繁出現在各大媒體上。
在大資料的發展歷程中,網際網路企業是佈局較早且融合較深的行業之一。因其網際網路屬性的優勢在大資料領域佈局較早。
而提到國內網際網路大資料企業,就不得不提國內網際網路三巨頭(百度、阿里、騰訊),三巨頭的大資料業務圍繞其自身業務發展而成:**百度重演算法、阿里重電商、騰訊重社交**,出於自身戰略,三巨頭在大資料領域的佈局方面各有重心,反映出其企業發展方向的戰略和思路。

### BAT的大資料產業
BAT 是我國網際網路企業中大資料佈局較早也是較具有競爭優勢的公司。其中,**阿里佈局大資料產業最早,騰訊次之,百度則最晚**。
#### 阿里
阿里大資料發展戰略在 2008 年提出,隨後圍繞電商業務,阿里在資料叢集、資料倉庫等方面做出了部署。
如今,提到阿里大資料,可以從兩方面來作觀察:一是以阿里電商業務基礎建立起來的阿里資料;二是阿里雲。
阿里資料以淘寶、天貓、阿里媽媽等平臺為業務線,通過資料採集、資料計算、資料服務、資料應用等環節,形成從資料採集到資料應用的閉環系統
阿里雲則主要以線上公共服務的方式,為使用者提供雲伺服器、雲資料庫、雲安全等雲端計算服以及大資料、人工智慧服務、精準定製等基於場景的行業解決方案。創立於 2009年,如今,阿里雲已成為全球前三大公共雲服務提供商。
另一方面阿里也是十分有遠見的,早在15、16年開始做Flink,深耕佈局、落地雙11、孵化Blink,據稱搞了上百人的團隊,在國內外的技術會議上不斷宣傳推廣,在2019年開年,阿里以9000萬歐元收購了Apache Flink母公司Data Artisans,將Flink收入囊中,目前,Flink 可以稱之為 Apache 基金會中最為活躍的專案之一,在 GitHub 上其訪問量在 Apache 專案中位居前三。同時,在全球範圍內,優步、網飛、微軟和亞馬遜等國際網際網路公司也逐漸開始使用 Apache Flink。

#### 騰訊
2009 年 1 月,騰訊搭建第一個 Hadoop 叢集,標誌著騰訊大資料之路正式開啟。
與阿里不同,騰訊大資料主要圍繞其社交、遊戲業務展開。坐擁著海量的使用者資料。
基於微信、QQ 等社交工具,通過對移動使用者的資料分析,建立使用者個人畫像(如使用者的社會關係、性格稟賦、興趣愛好等)提供相應的營銷服務。
工具,工具主要有騰訊移動推送資訊“信鴿”,同樣也是圍繞騰訊的社交使用者資料開發而成,提供向用戶推送訊息的服務。
騰訊雲,起步比阿里雲晚幾年,目前暫時落後於阿里雲,但是雲端計算市場是一個馬拉松賽,起步早是一方面,但最終還是要看誰能堅持到最後。
之前看過一篇資訊,中國IT領袖峰會在深圳舉行,在一個對話環節。
李彥巨集說:“雲端計算這個東西不客氣一點講它是新瓶裝舊酒,沒有新東西。”
馬化騰說:"雲端計算讓計算能力、處理能力甚至邏輯元件都能夠像水和電一樣使用,的確是有想象空間的,但可能你過幾百年、一千年後才可能實現,現在還是確實過早了。"
馬雲大概意思:“雲端計算這個東西應該好好做,今天就應該做,如果阿里巴巴不做雲端計算,騰訊、百度會把阿里巴巴趕出電子商務門口。“
從對話中能看出馬雲的眼光很好。李彥巨集和馬化騰雖都是技術出身,但沒有一個教師出身的馬雲眼光長遠。
另一點,騰訊相比其他巨頭在技術方面要低調不少。技術大牛很少出來做報告,更不會向百度、阿里那樣主動包裝宣傳技術大牛。其技術雖然低調,但執行力很強。據騰訊的程式設計師朋友說封閉開發、集體加班是常有的事情。但配套的重金激勵也能跟上。重金之下必有勇夫!

#### 百度
BAT 中,百度大資料戰略提出時間最晚,但舉措頻頻。
2013 年,百度成立深度學習實驗室(IDL),發力人工智慧。
2014 年,百度對外宣佈開放“大資料引擎”,以開放雲、資料工廠和百度大腦三個為核心元件,
通過平臺化和介面化的方式,對外開放其大資料儲存、分析和智慧化處理等核心能力。作為全球首個開放大資料引擎,百度“大資料引擎”已與政府、非政府組織、製造、醫療、金融、零售和教育等傳統領域展開合作。
同年 8 月,百度與聯合國宣佈啟動戰略合作,共建大資料聯合實驗室 (bdl),探索利用大資料解決全球
性問題的創新模式。
2017 年 3 月 2 日,百度揭牌深度學習技術及應用國家工程實驗室,“國字號”AI實驗室落戶百度。
可以看出,百度不同於阿里和騰訊基本以自身業務佈局大資料,其大資料佈局側重於新方向,在人工智慧上尤其突出。不過,梳理百度大資料的資料產品可以發現,其大資料產品涉及資料分析、資料風控、資料營銷等,佈局較廣。

### 大資料領域分析
大資料技術發展到如今,已經形成了完備的體系結構及應用方向,技術迭代速度非常快,新框架層出不窮,大資料應用方向不斷細化,從業人員越來越多。
大資料時代,資料量大,資料來源異構多樣,資料時效性等特徵催生了大量的新技術需求。在這樣的需求下,誕生了**規模化並行處理(MPP)** 的分散式計算框架;面向海量的非結構化資料,出現了 Hadoop、Spark等生態體系的**分散式批處理框架**;面對時效性及實時處理的需求,出現了Flink、Spark Streaming等**分散式流處理框架**。
下圖為 Apache 生態下的大資料框架:

未來在 Apache 中孵化成功的大資料框架會越來越多,大資料生態體系會越來越完善,也意味著大資料的門檻會越來越低,入行的人越來越多。所以為了我們不被時代所淘汰,需要不斷學習,前期學習廣度,後期專注深度。**潛心一技,練到極致**!
**應用層面**
大資料在應用層面劃分了以下幾個大類:**金融大資料、營銷大資料、交通物流大資料、醫療大資料、教育大資料、文娛大資料**等。
我們接下來以大資料科研及大資料企業兩方面進行分析:
#### 1. 大資料科研
自 2012 年大資料廣泛實際應用以來,產業界和學術界在大資料技術與應用方面的研究創新不斷取得突破,大資料領域的論文發表數量快速增長。
以下為 2012-2020年全球大資料論文發表數量及各國佔比:
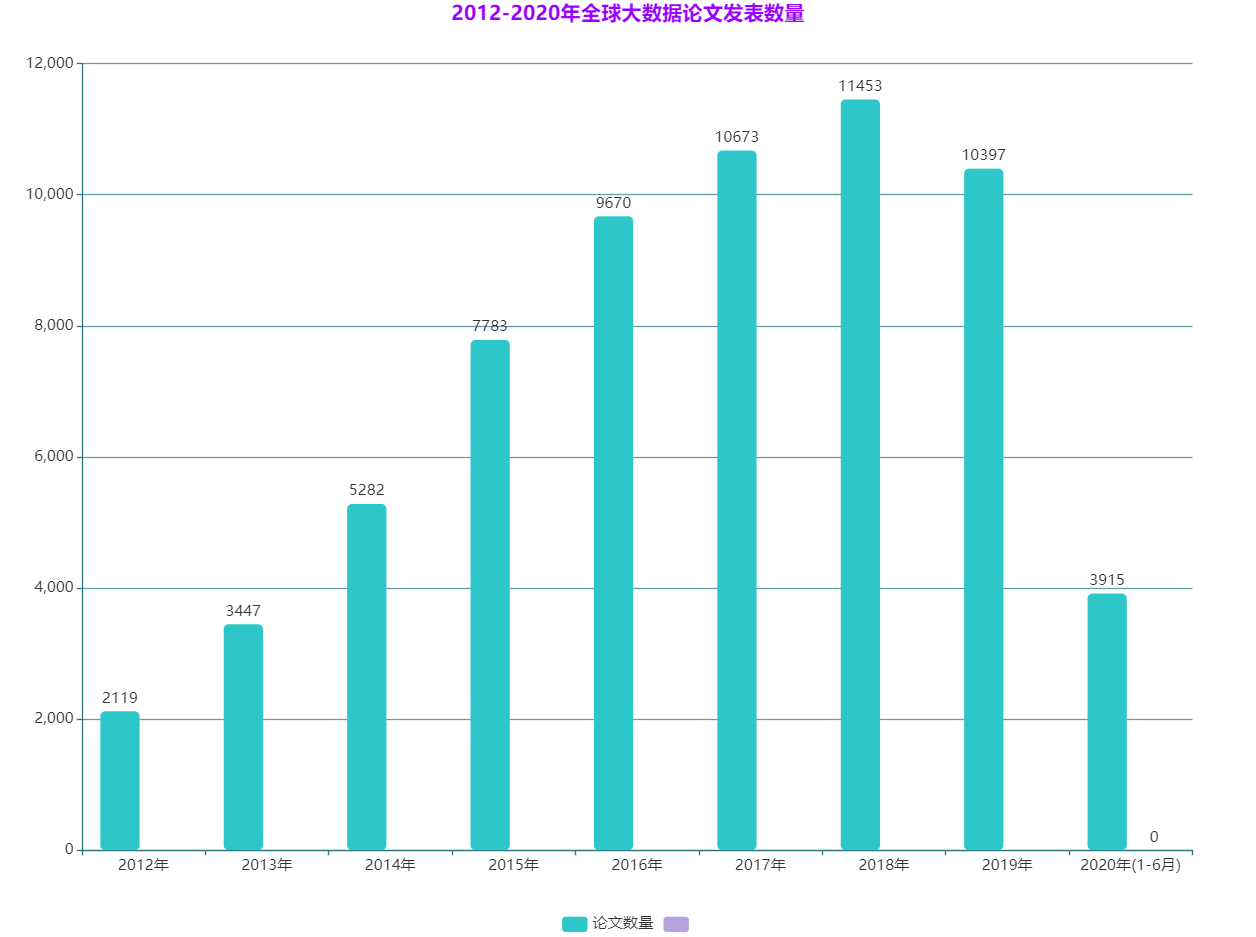
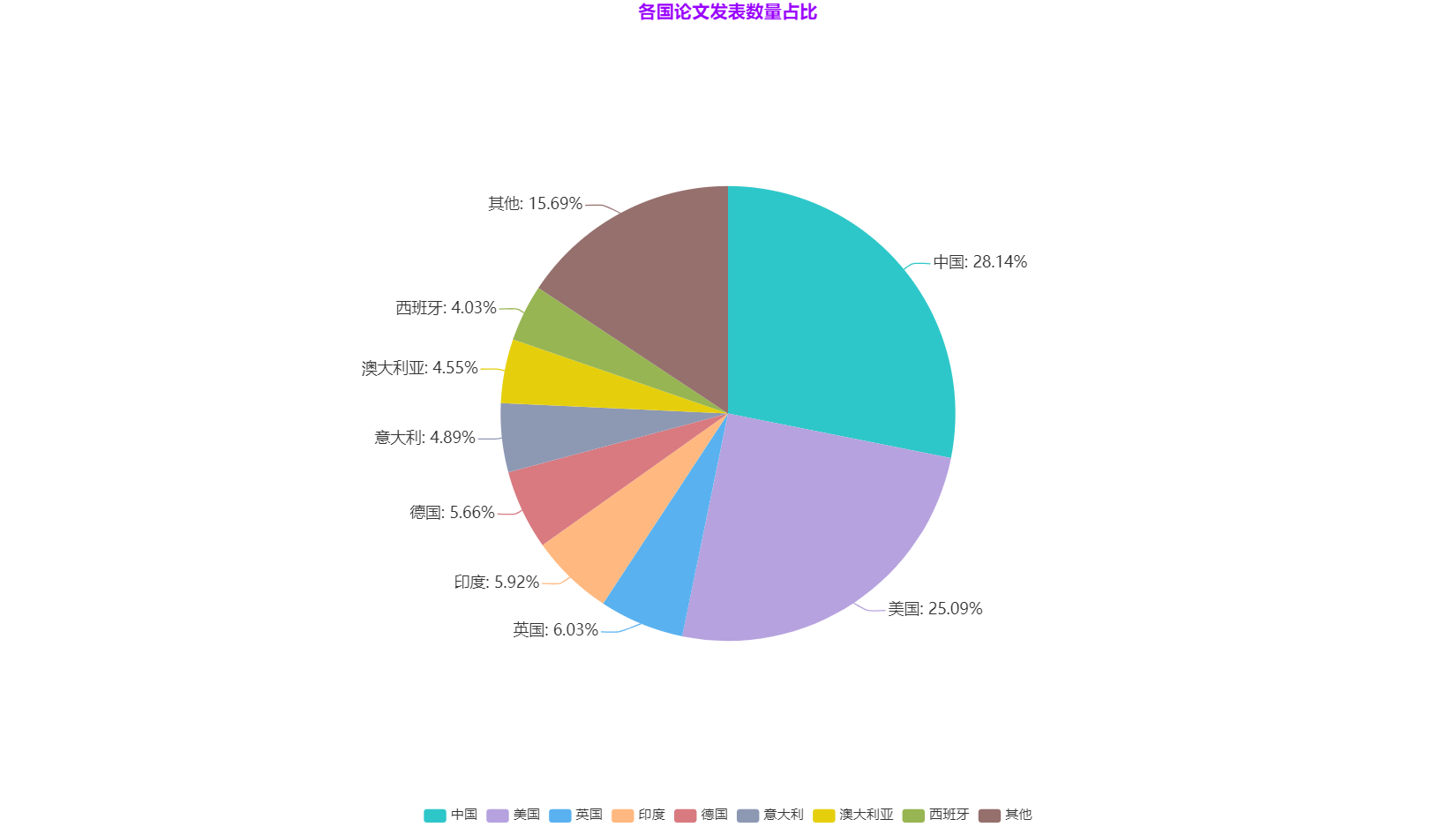
資料來源:Web of Science,2020年10月
從上圖可以看出,論文發表數量在2018年達到頂峰,是2012年的5.4倍,年增長率為 32.5%,隨後2019年論文數量開始下降,2020年全年數量預計較去年還會近一步下滑,這也說明**隨著科學研究的不斷進展,大資料的相關理論體系逐漸成熟**,未來學術論文發表增長速度或將放緩。
從國家來看,中國和美國仍然是大資料學術研究的核心地帶。發表的論文數量遙遙領先於其他國家。未來在大資料領域,應該還是以中國和美國為首,帶領大資料技術走向更高的水平。
再來看國內大資料產業的發展狀況,根據工業和資訊化部發布的資料顯示,2019年我國以雲端計算、大資料技術為基礎的平臺類技術服務收入2.2萬億元,其中,典型雲服務和大資料服務收入達3284億元,提供服務的企業達2977家,由此可見,大資料產業發展日益壯大。
#### 2. 大資料企業
**大資料企業數量增長統計**
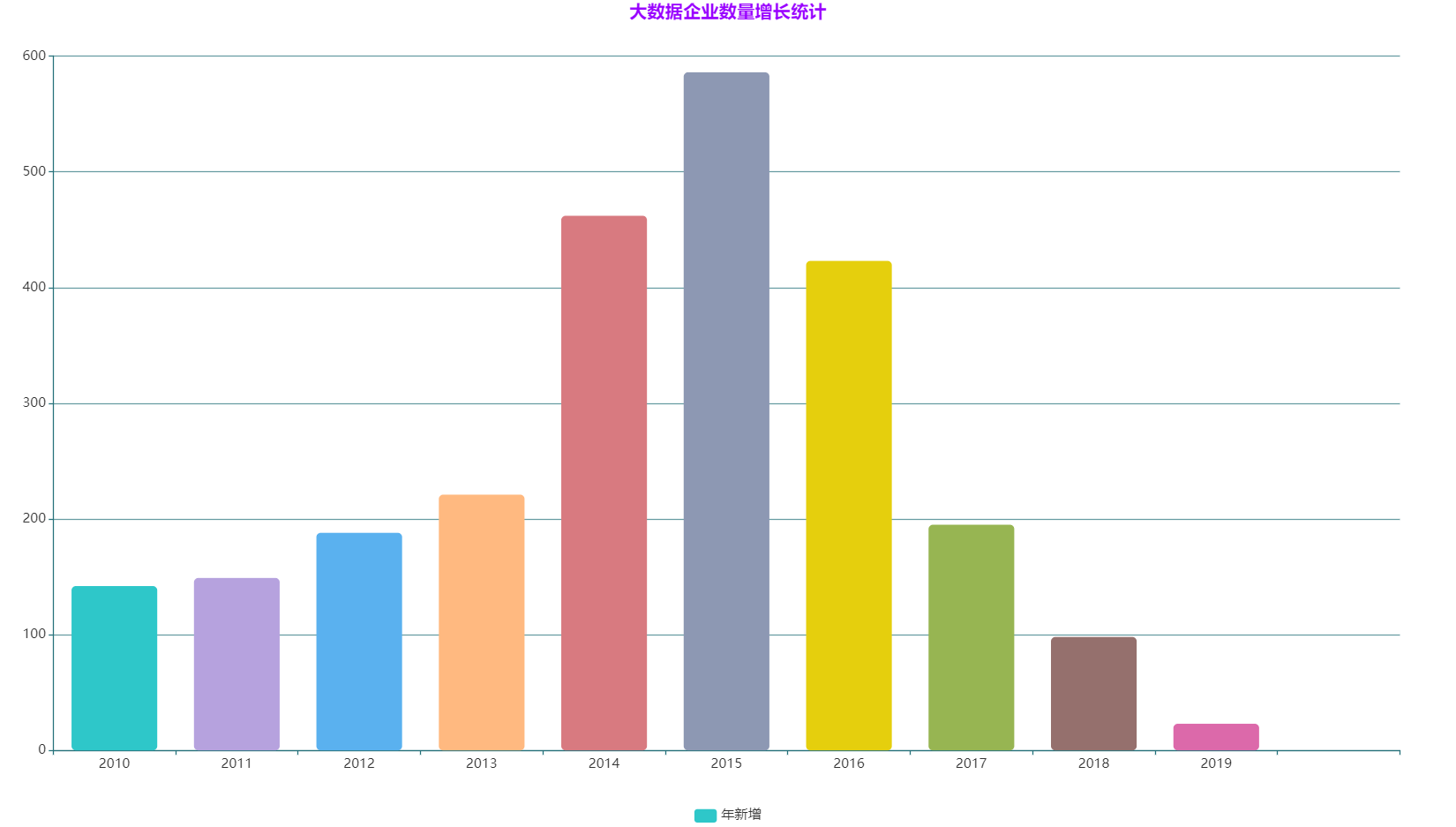
資料來源:中國資訊通訊研究院,2020年10月
從上圖可以看出國內大資料企業在 2014 年、2015 年呈現爆發式增長,而在 2016 年
後又有回落,這與大資料在我國的發展狀況相對應。**2014 年被稱為大資料元年**,隨後在國家政策的支援下,各大資料企業應運而生,之後隨著創業者的冷靜,大資料企業也趨於減少。
***
**是否有國資背景**
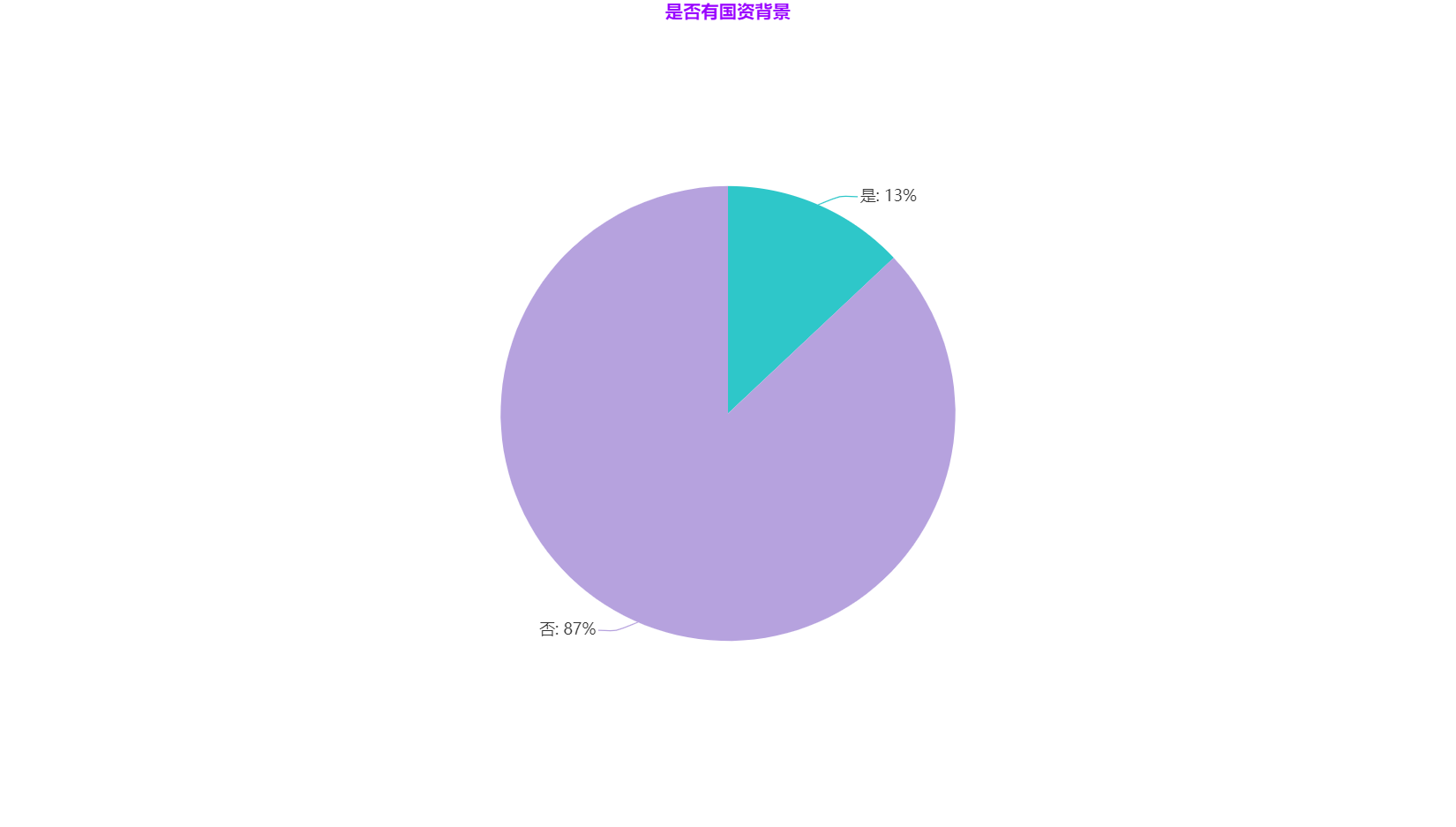
資料來源:資料觀
大資料行業雖然有國家政策的支援,但大部分還是以私企為主,具有國資背景的企業較少,只佔總體的 13%。
***
**大資料企業地域分佈**
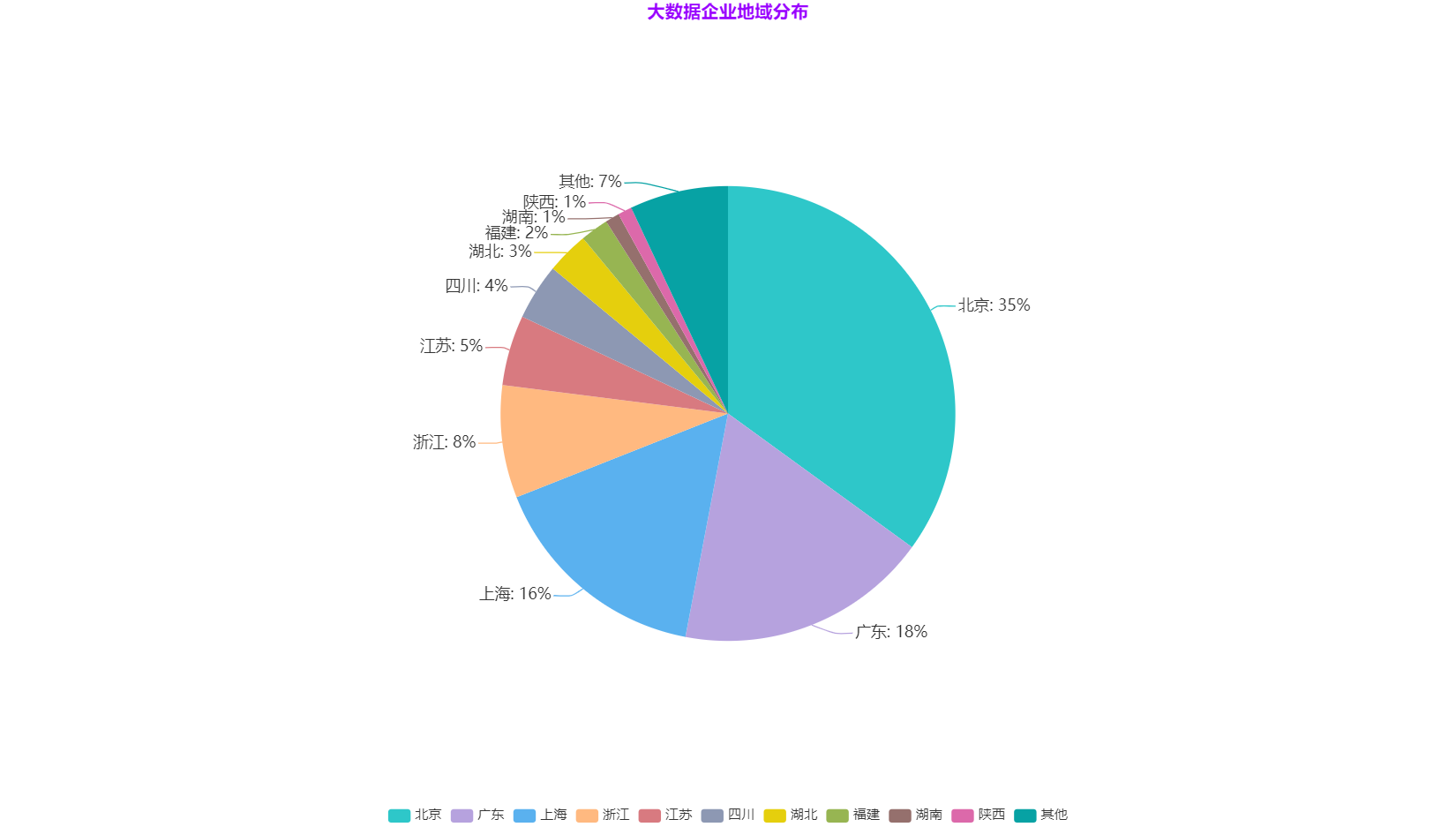
資料來源:中國資訊通訊研究院,2020年10月
由表中資料可以得出,北京是大資料企業的“高發區”,佔比為35%,其次是廣東(18%),之後是上海(16%),然後是浙江(8%),所以我國大資料企業主要分佈在北京、廣東、上海、浙江等經濟發達省份。
***
**大資料行業應用企業型別分佈**
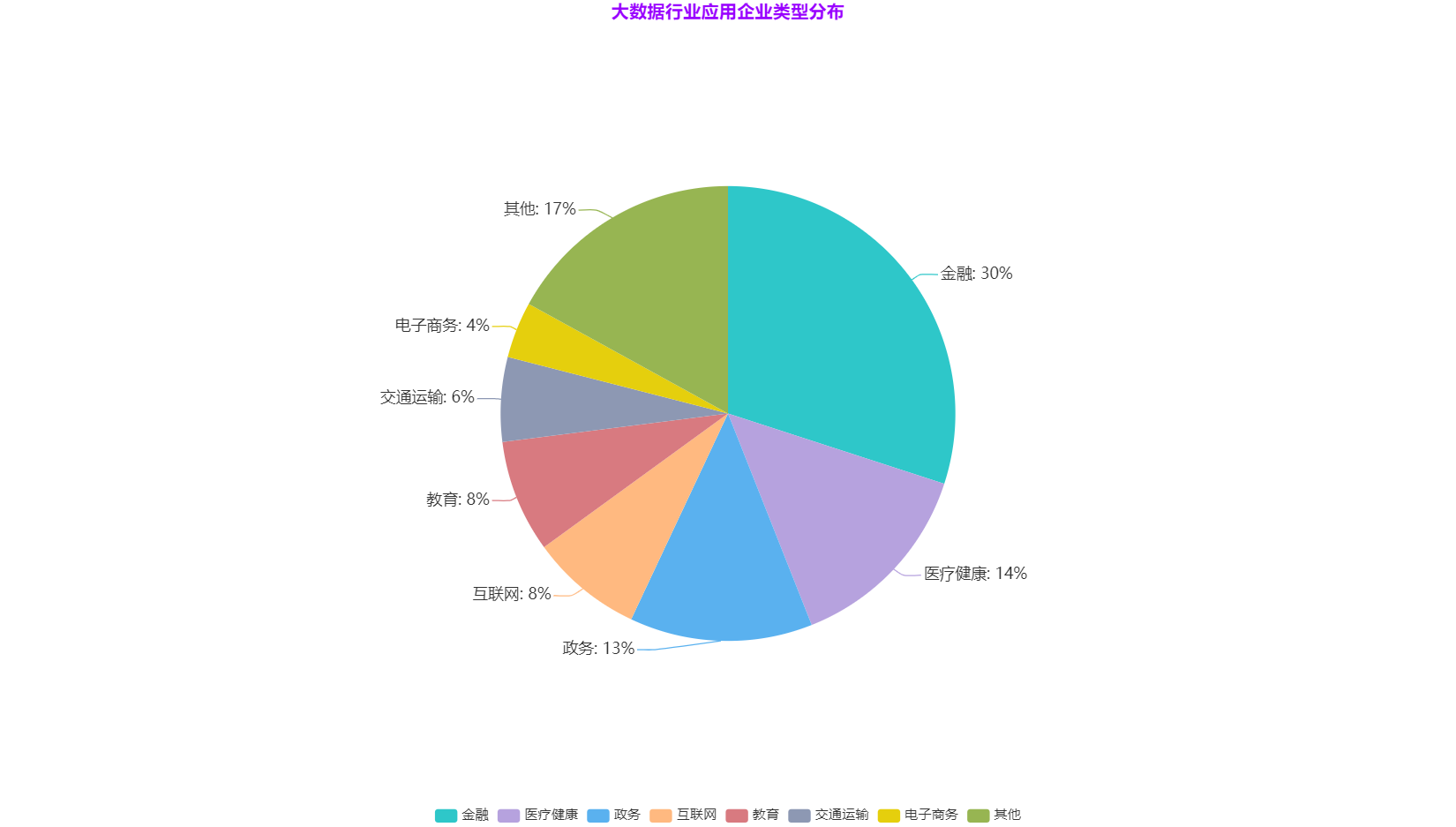
資料來源:中國資訊通訊研究院,2020年10月
從圖中可以看出大資料涉及的行業是非常廣泛的,其中以金融、醫療健康、政務為大資料行業應用的主要型別。除此之外依次是網際網路,教育,交通運輸,電子商務等。
***
**大資料獲投輪次分佈**
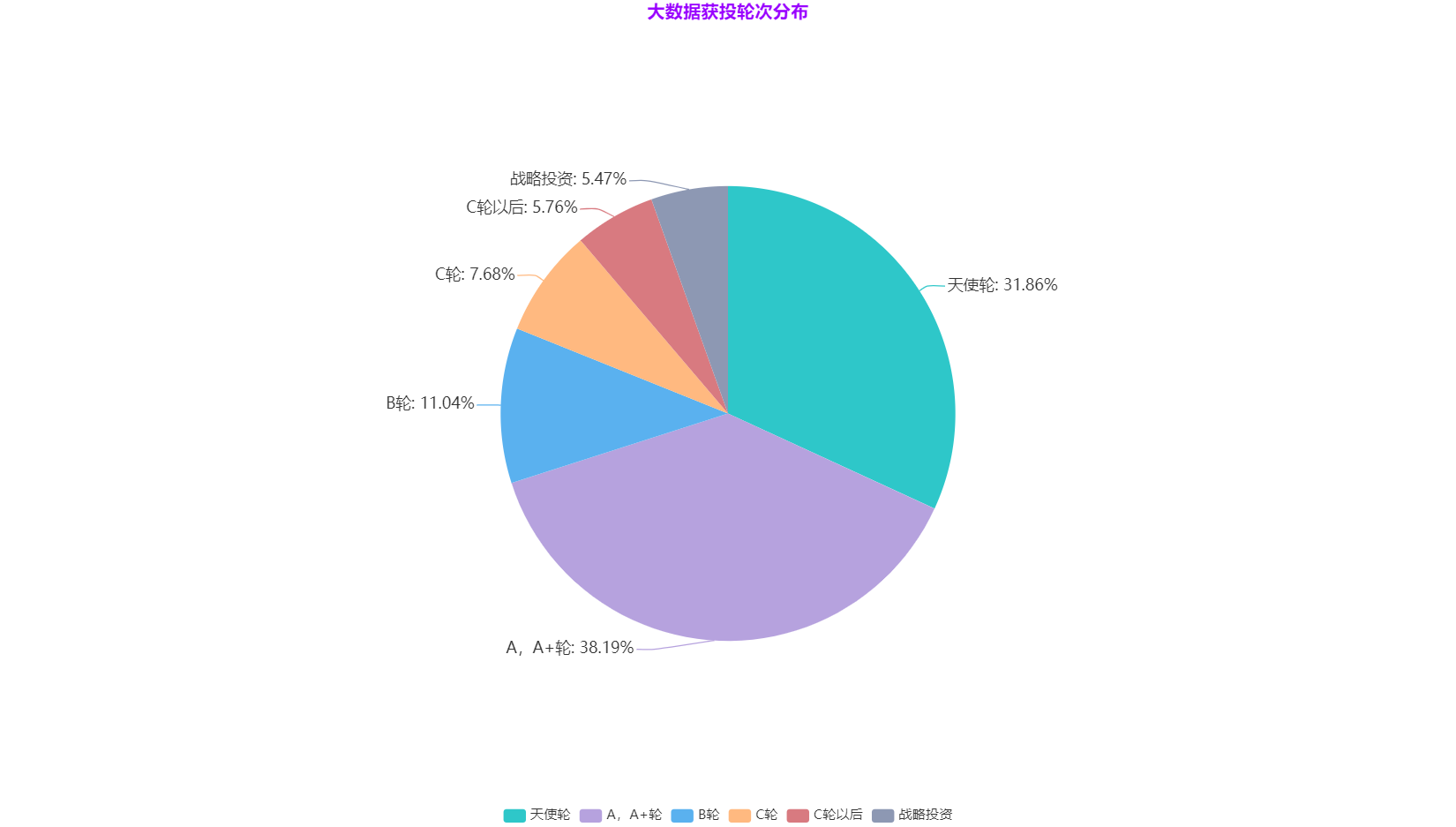
資料來源:中國資訊通訊研究院,2020年10月
從上圖看出獲 天使輪、A 輪 融資企業較多,說明我國大資料企業數量雖然眾多,但大部分處於初級階段,技術能力、技術落地能力有待提高。另一方面也說明投資機構對大資料市場依然充滿資訊,對未來估值抱有很大期望。
### 大資料未來發展趨勢
> 以下觀點來源:中國資訊通訊研究院
#### 1. 以控制成本為主要理念
大資料自誕生以來始終沿襲著基於Hadoop或者MPP的分散式框架,形成了具備儲存、計算、處理、分析等能力的完整平臺,**大資料分散式框架採用儲存與計算耦合**,使資料在自身儲存的節點上完成計算,以降低互動。
但是實際業務中資料儲存與計算能力要求不同且各自獨立的。**在儲存與計算耦合的情況下,當二者之一出現瓶頸時,資源的橫向擴充套件必然導致儲存或計算能力的冗餘,造成難以避免的額外成本**。
**儲存與計算分離有效控制成本**。儲存與計算在資料的生命週期中剝離開,形成兩個獨立的資源集合。兩個資源集合之間互不干涉又通力協作,使得單位資源的成本儘量減少,同時兼具充分的彈性以供橫向擴充套件。這種模式應是未來的發展方向。
目前國內外眾多廠商已深入進行了存算分離的實踐。國內像阿里雲使用自身 **EMR+OSS產品代替原生 Hadoop 儲存架構**,整體費用預估下降 50% 。華為使用自身 **FusionInsight+EC**,儲存利用率從 33% 提升至 91.6%。
國外像 Snowflake 公司提出的**資料倉庫服務化(DaaS)**,將分析能力以雲服務的形式在AWS等雲平臺上提供按次計費的服務。
#### 2. 自動化智慧化需求緊迫
目前大資料領域的資料管理依賴人工操作,成本巨大。在基於機器學習的人工智慧不斷進步的情況下,**更加自動化智慧化的資料管理平臺將會助力資料管理工作高效進行。**
其中以 **資料建模、資料標籤、主資料發現、資料標準應用**成為主要的應用方向。
#### 3. 圖分析需求旺盛
以社交網路、使用者行為、網頁連結關係等為代表的資料,往往需要通過“圖”的形態以最原始、最直觀的方式展現其關聯性。
所以**專注於圖結構資料的圖分析技術成為資料分析技術的新方向**。與圖分析相關的技術成為熱點的產品方向,其中以**圖資料庫、圖計算引擎、知識圖譜**三項技術為主。
根據 DB-Engines 排名分析,圖資料庫關注熱度在2013-2020年間增長了10倍,關注度增長排名第一。國內阿里雲、華為、騰訊、百度等廠商及部分初創公司已佈局這一領域。
#### 4. 隱私計算技術熱度上升
在資料合規流通需求旺盛的環境下,隱私計算技術發展火熱,隱私計算為實現安全合規的資料流通帶來了可能。
目前隱私計算主要分為**多方安全計算**和**可信硬體**兩大流派。其中多方安全計算基於密碼學理論;可信硬體依賴對安全硬體的信賴。
此外,還有**聯邦學習**、**共享學習**等通過多種技術手段平衡安全性和效能的隱私保護,也為跨企業機器學習和資料探勘提供新的解決思路。
***
參考來源:中國資訊通訊研究院[大資料白皮書(2020年)];資料觀(www.cb