
Java 集合學習筆記
阿新 • • 發佈:2021-02-21
@[TOC]
# Java 集合(容器)
## 一、Java 集合框架概述
* 一方面,面嚮物件語言對事務的體現都是以物件的形式,為了方便對多個物件的操作,就要對物件進行儲存。另一方面,使用 Array 儲存物件放面具有一些弊端,而 Java 集合就像一種容器,可以動態的把多個物件的引用放入容器中。
* 陣列在記憶體儲存方面的特點:
* 陣列初始化以後,長度就確定了
* 陣列宣告的型別,就決定了元素初始化時的型別
* 陣列在儲存資料方面的弊端:
* 陣列初始化以後,長度不可變,不便於擴充套件
* 陣列中提供的屬性和方法少,不便於進行新增、刪除、插入等操作,且效率不高。同時無法直接獲取儲存的元素的個數
* 陣列儲存的資料是有序的、可重複的。(儲存資料的特點單一)
* Java 集合類可用於儲存數量不等的多個物件,還可用於儲存具有對映關係的關聯陣列。
* Java 集合可分為 Collection 和 Map 兩種體系
* Collection 介面:單列資料,定義了存取一組物件的方法和集合
* List:元素有序、可重複的集合
* Set:元素無需、不可重複的集合
* Map 集合:雙列資料,儲存具有對映關係 “ key - value 對” 的集合
* Collection 介面繼承樹
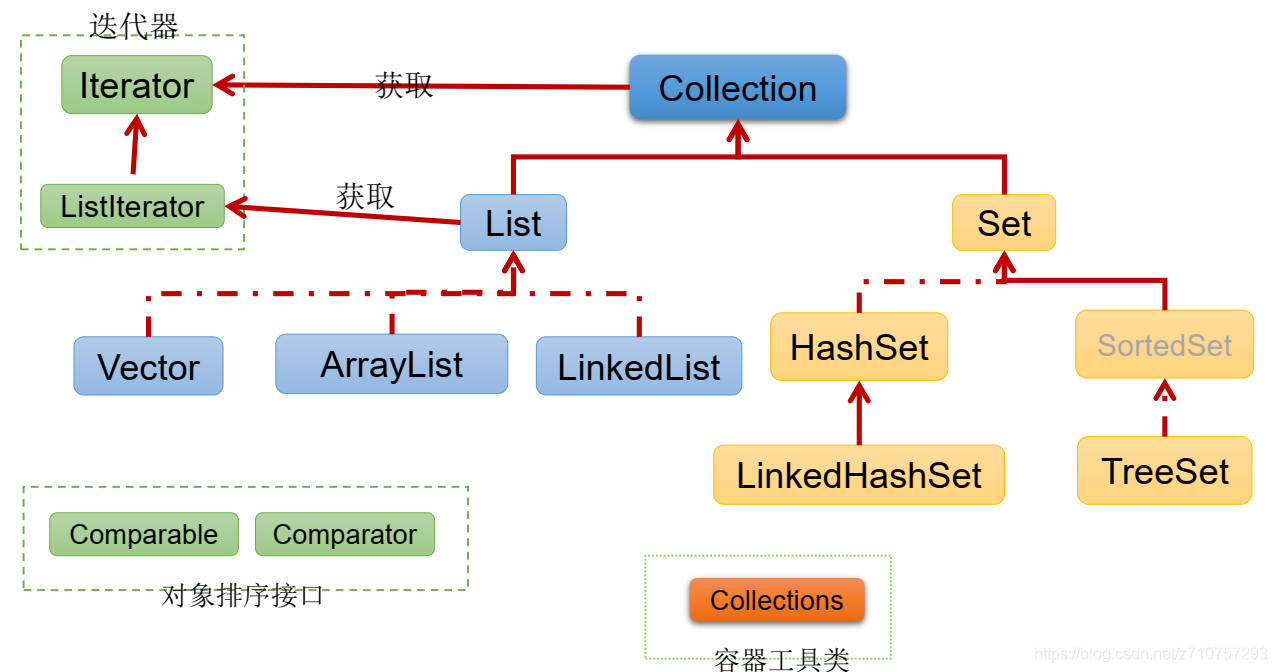
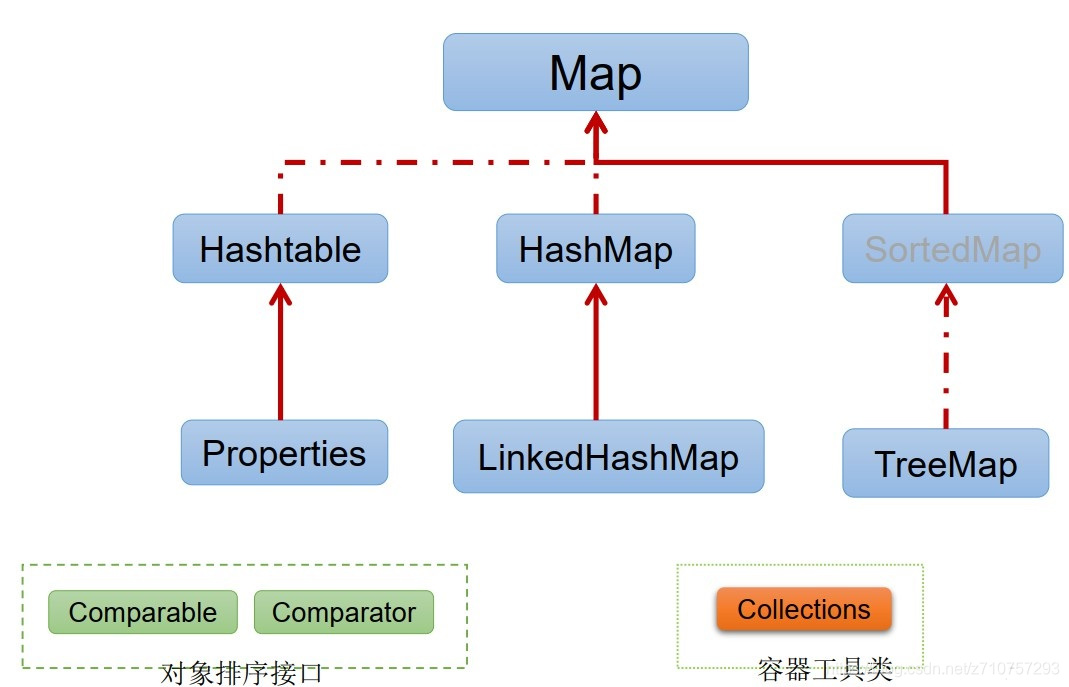
* Map 介面繼承樹
## 二、Collection 介面方法
[Collection 介面中文文件(JDK 11)](https://www.runoob.com/manual/jdk11api/java.base/java/util/Collection.html)
1. 新增
* add(Object obj)
* addAll(Collection coll):將集合 coll 中的所有元素新增到當前集合中
2. 獲取有效元素的個數
* int size()
3. 清空合集
* void clear()
4. 是否為空集合
* boolean isEmpty()
5. 是否包含某個元素
* boolean contains(Object obj):是通過**元素的 equals 方法**來判斷是否是同一個物件
* boolean containsAll(Collection c):也是呼叫 equals 方法來比較,用兩個集合的元素挨個比較。
6. 刪除
* boolean remove(Object obj):通過 equals 方法定位,並刪除,**只會刪除找到的第一個元素**
* boolean removeAll(Collection coll):取當前集合的差集
7. 取兩個集合的交集
* boolean retainAll(Collection c):把交集的結果存在當前集合中,不影響集合 c
8. 集合是否相等
* boolean equals(Object obj)
9. 轉成物件陣列
* Object[] toArray()
* 陣列 轉化成 集合:呼叫 Arrays 類的靜態方法 asList()。
* 但要注意該方法直接寫入 new int[](123, 456) 只是把整體當成一個元素存入,此時用包裝類的方式即可解決。
10. 獲取集合物件的雜湊值
* hashCode()
11. 遍歷
* iterator():返回迭代器物件,用於遍歷集合
## 三、Iterator 迭代器介面
### 1. 使用 Iterator 介面遍歷集合元素
* Iterator 物件稱為迭代器(設計模式的一種),主要用於遍歷 Collection 集合中的元素。
* GOF 給迭代器模式的定義為:提供一種方法訪問一個容器(container)物件中各個元素,而又不需要暴露該物件的內部細節。迭代器模式,便是為容器而生。類似於”公交車上的售票員”、”火車上的乘務員“、”空姐“。
* Collection 介面繼承了 java.lang.Iterator 介面,該介面有一個 Iterator() 方法,那麼所有實現了 Collection 介面的集合類都有一個 Iterator() 方法,用以返回一個實現了 Iterator 介面的物件。
### 2. Iterator 介面的方法
| boolean | hasNext(): Return true if the iterator has more elements. |
| ------- | ------------------------------------------------------------ |
| E | next(): Return the next element int the iteration. |
| void | remove(): Removes from the underlying collection the last element returned by the iterator(optional operation). |
* 可採取 hasNext() 和 next() 方法配合遍歷集合
==在呼叫it.next()方法之前必須要呼叫it.hasNext()進行檢測。若不呼叫,且下一條記錄無效,直接呼叫it.next()會丟擲NoSuchElementException異常。==
```java
while(iterator.hasNext) {
iterator.next();
}
```
**兩種常見的錯誤遍歷方式:**
```java
//方式一:
Iterator iterator = coll.iterator();
while(iterator.next() != null) {
System.out.println(iterator.next());
}
//while的條件會使 集合指標 移動一次,導致輸出結果跳躍
```
```java
//方式二:
while(coll.iterator().hasNext()) {
System.out.println(coll.iterator().next());
}
//集合物件每次呼叫 iterator() 方法都會得到一個全新的迭代器物件,預設指標 都會從集合的第一個元素開始。
```
* 有關 remove()
```java
Iterator iter = coll.iterator();
while(iter.hasNext()) {
Object obj = iter.next();
if(obj,equals("Tom")) {
iter.remove();
}
}
```
* 注意
* Iterator 可以刪除集合的元素,但是 是通過遍歷過程中通過迭代器物件的 remove 方法,不是集合物件的 remove 方法。
* 如果還未呼叫 next() 或在上一次呼叫 next 方法之後已經呼叫了 remove 方法,再呼叫 remove 都會報IllegalStateException
### 3. 使用 foreach 迴圈遍歷集合元素
* Java 5.0 提供了 foreach 迴圈迭代訪問 Collection 和 陣列
* 遍歷操作不需要獲取 Collection 或陣列的長度,無需使用索引訪問元素
* 遍歷集合和底層呼叫 Iterator 完成操作
* foreach 還可以用來遍歷陣列

## 四、Collection 子介面一:List
### 1. List 介面概述
* 鑑於 Java 中陣列用來儲存資料的侷限性,我們通常使用List替代陣列
* List 集合類中 元素有序、且可重複,集合中的每個元素都有其對應的順序索引。
* List容器中的元素都對應一個整數型的序號記載其在容器中的位置,可以根據序號存取容器中的元素。
* JDK API中List介面的實現類常用的有:ArrayList、LinkedList和Vector。
### 2. List 介面方法
* List 除了從 Collection 集合繼承的方法外,List 集合裡添加了一些根據索引來操作集合元素的方法。
* void add(int index, Object ele):在 index 位置插入 ele 元素
* boolean addAll(int index, Collection eles):從 index 位置開始將 eles 中的所有元素新增進來
* Object get(int index):獲取指定 index 位置的元素
* int indexOf(Object obj):返回 obj 在集合中首次出現的位置
* int lastIndexOf(Object obj):返回 obj 在當前集合中末次出現的位置
* Object remove(int index):移除指定 index 位置的元素,並返回此元素
* Object set(int index, Object ele):設定指定 index 位置的元素為 ele
* List subList(int fromIndex, int toIndex):返回從 fromIndex 到 toIndex 位置的子集合
### 3. List 實現類之一:ArrayList(主要)
* ArrayList 是 List 介面的典型實現類、主要實現類
* 本質上,ArrayList 是物件引用的一個“變長“陣列
* ArrayList 的 JDK 1.8 之前與之後的 空參構造器 的實現區別(其他方面無異)?
* JDK 1.7:類似餓漢式,直接建立一個初始容量為 10 的陣列
* ```java
ArrayList list = new ArrayList();
list.add(123); // elementData[0] = new Integer(123);
```
* 當陣列 elementData 陣列容量不夠時,預設情況下,擴容為原來的 1.5 倍,同時將原來陣列中的資料複製到新的陣列中。
* 建議開發中使用帶參構造器:一開始人為的確定容量
* JDK 1.8:類似懶漢式,一開始建立一個長度為 0 的陣列,當新增第一個元素時再建立一個是容量為 10 的陣列
* Array.asList() 方法返回的 List 集合,既不是ArrayList 試裡,也不是 Vector 例項。Array.asList() 返回值是一個固定長度的 List 集合。
* [**原始碼分析傳送門**
Vector 和 ArrayList 幾乎完全相同,最大區別為 Vector 是同步類(synchronized),屬於強同步類。因此開銷比 ArrayList 要大,訪問要慢。正常情況下,一般使用 ArrayList 而不是 Vector,因為同步完全可以由程式設計師自己來控制(如使用Collections的方法)。
Vector 每次擴容請求其大小的 2 倍空間,而 ArrayList 是 1.5 倍。
Vector還有一個子類 Stack ## 五、Collection 子介面二:Set ### 1. Set 介面概述 * Set 介面是 Collection 的子介面,Set 介面沒有提供額外的方法。 * Set 集合不允許包含相同的元素 * Set 判斷兩個物件是否相同,使用的是 equals() 方法。 ### 2. Set 實現類之一:HashSet * HashSet 是 Set 介面的典型實現,大多數使用 Set 集合時都使用該實現類。 * HashSet 按 Hash 演算法來儲存集合種的元素,因此具有很好的存取、查詢、刪除效能。 * **HashSet 具有以下特點:** * 不能保證元素的排列順序 * HashSet 不是執行緒同步的 * 集合元素可以時null * **HashSet 集合判斷兩個元素相等的標準:** 通過 hashCode() 方法比較相等,並且兩個物件的 equals() 方法返回值也相等。 * 對於存放在 Set 容器種的物件,對應的類一定要重寫 equals() 和 hashCode(Object obj) 方法,以實現物件相等規則。即:”相等的物件必須具有相等的雜湊碼“。 * HashSet新增元素的過程: 新增元素a,首先呼叫元素 a 所在類的 hashcode() 方法,計算元素a的雜湊值,通過此雜湊值和某種雜湊函式
Vector 和 ArrayList 幾乎完全相同,最大區別為 Vector 是同步類(synchronized),屬於強同步類。因此開銷比 ArrayList 要大,訪問要慢。正常情況下,一般使用 ArrayList 而不是 Vector,因為同步完全可以由程式設計師自己來控制(如使用Collections的方法)。
Vector 每次擴容請求其大小的 2 倍空間,而 ArrayList 是 1.5 倍。
Vector還有一個子類 Stack ## 五、Collection 子介面二:Set ### 1. Set 介面概述 * Set 介面是 Collection 的子介面,Set 介面沒有提供額外的方法。 * Set 集合不允許包含相同的元素 * Set 判斷兩個物件是否相同,使用的是 equals() 方法。 ### 2. Set 實現類之一:HashSet * HashSet 是 Set 介面的典型實現,大多數使用 Set 集合時都使用該實現類。 * HashSet 按 Hash 演算法來儲存集合種的元素,因此具有很好的存取、查詢、刪除效能。 * **HashSet 具有以下特點:** * 不能保證元素的排列順序 * HashSet 不是執行緒同步的 * 集合元素可以時null * **HashSet 集合判斷兩個元素相等的標準:** 通過 hashCode() 方法比較相等,並且兩個物件的 equals() 方法返回值也相等。 * 對於存放在 Set 容器種的物件,對應的類一定要重寫 equals() 和 hashCode(Object obj) 方法,以實現物件相等規則。即:”相等的物件必須具有相等的雜湊碼“。 * HashSet新增元素的過程: 新增元素a,首先呼叫元素 a 所在類的 hashcode() 方法,計算元素a的雜湊值,通過此雜湊值和某種雜湊函式