
淺談深度學習的落地問題
阿新 • • 發佈:2021-02-21
# 前言
深度學習不不僅僅是理論創新,更重要的是應用於工程實際。
關於深度學習人工智慧落地,已經有有很多的解決方案,不論是電腦端、手機端還是嵌入式端,將已經訓練好的神經網路權重在各個平臺跑起來,應用起來才是最實在的。
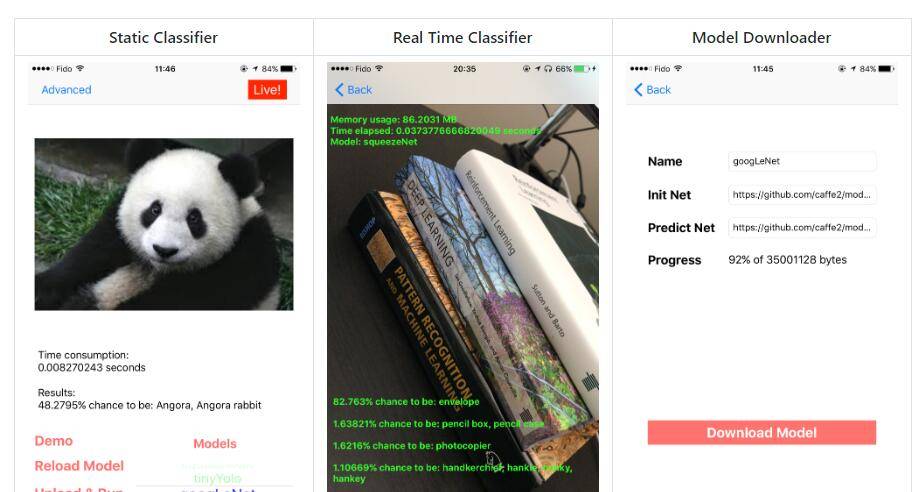
(caffe2-ios:https://github.com/KleinYuan/Caffe2-iOS)
這裡簡單談談就在2018年我們一般深度學習落地的近況。
## Opencv
Opencv相比大家都比較瞭解,很流行很火的開源影象處理庫,人工智慧深度學習大夥,Opencv自然不能落下。早在去年Opencv開始加入Dnn模組,並且一直更新,但是有點需要注意,`Opencv`的深度學習模組是用來`inference`推斷而不是用來訓練的。
為什麼,因為現在已經存在很多優秀的深度學習框架了(TensorFlow、Pytorch),Opencv只需要管好可以讀取訓練好的權重模型進行推斷就足夠了。
(opencv-4.0.0已經發布)
自己試著跑了一下Opencv版的yolov3,利用yolo官方訓練好的權重,讀取權重並且利用Opencv的前向網路執行——速度還可以,在**i5-7400** CPU上推斷用了**600+ms**。

而我用2017版MacBookPro-2.3GHz版本的CPU(i5-7260u)則跑了**500ms**。要知道這是完全版本的yolo-v3。如果進一步優化的話,在稍微好點的CPU端是可以跑到10fps!
另外在[learnopencv](https://www.learnopencv.com/deep-learning-based-object-detection-using-yolov3-with-opencv-python-c/)相關文章中,也有詳盡的評測:
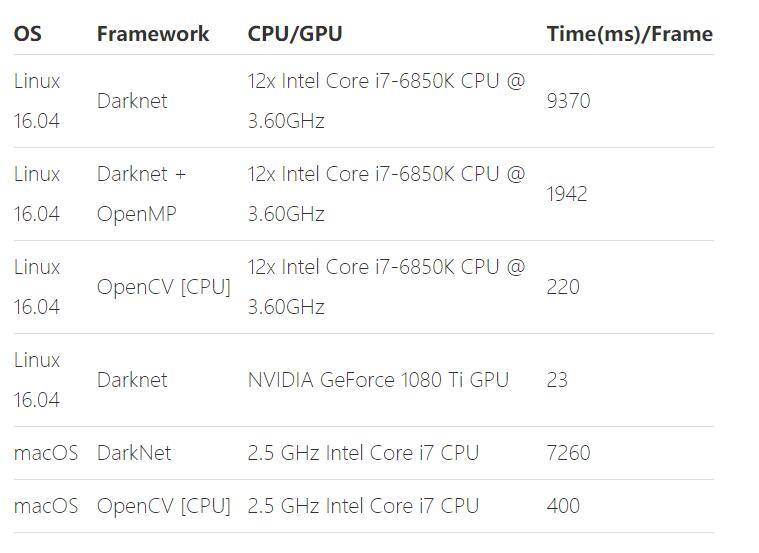
在6核12執行緒的CPU中可以跑到**200ms**,速度相當快了,而且優化的空間還是有的。
為什麼Opencv版的比Darknet版的速度快那麼多,是因為Opencv的Cpu端的op編寫過程中利用了CPU-MKL等很多優化庫,針對英特爾有著很好的優化,充分利用了多執行緒的優勢(多執行緒很重要,平行計算比序列計算快很多)。
當然這些優化還不是盡頭,Opencv也在一直更新:
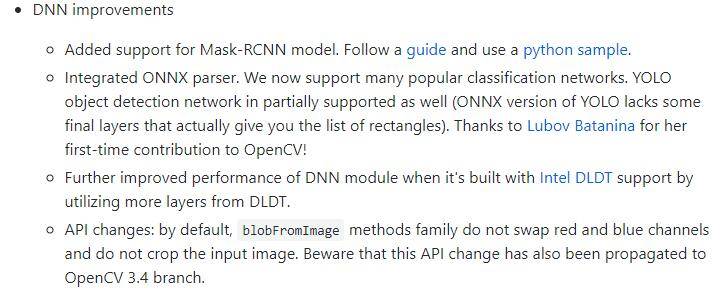
Opencv可以作為一個不錯的落地的深度學習推斷平臺,只要安裝好Opencv,就可以跑深度學習程式碼了,不需要安裝其他深度學習框架了。但是有點需要注意,Opencv最好的實踐是CPU端,GPU端Opencv對cuda的支援不是很好,Opencv只有利用OpenCL支援GPU,但速度沒有cuda庫快。
## Pytorch-v1.0
Pytorch-v1.0的預覽版已經發布了,正式版應該是在國慶節的第一天釋出。

但我們在觀察Pytorch的1.0文件中已經可以熟知,為什麼Pytorch-v1.0稱為從**研究到生產**:

最重要的三點:
- 分散式應用
- ONNX的完全支援
- 利用C++部署生成環境
簡單談談第三個要點,看了官方的說明文件,Pytorch也做了類似於Opencv工作,新的Pytorch支援直接應用Pytorch的C++部分從而編譯可以單獨執行Pytorch的推斷部分而不需要安裝所有Pytorch的元件。
近期會測試一下Pytorh和Opencv相比在Cpu端的速度,看看哪個對CPU端的優化更好些。
## IOS、安卓
IOS最大的看點就是:Iphone最新出來的A12仿生處理器!

5W億次每秒執行速度,跟專業顯示卡比起來可能不算什麼,但是在手機端,意思可想而知。
只是不知道具體的速度如何,跑Yolo的話可不可以實時,期待之後的測評吧。

不過在HomeCourt這款APP中(中國目前還不可以使用),憑藉A12強大的效能,貌似可以實時追蹤人體骨架。還是很值得期待的。
至於安卓端,因為華為的晶片還沒有具體公佈,目前在移動端上的神經網路框架大部分是用CPU跑。
速度快慢就看在arm端的優化如何了。
比較流行的兩個框架是ncnn(主要是cpu)和mace(也支援Gpu)。都在發展階段,前者出世1年左右,後者出世半年不到。
也期待一下吧!
## 後記
深度學習落地,最繁瑣的莫過於配置各種環境,希望之後各大深度學習框架能夠在落地這塊加大投入,實現快速方便地部署吧!
配一張Openpose的配置資訊:

([OpenPose](https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/installation.md#windows-portable-demo)中對Windows的要求較為苛刻)
# 撩我吧
- 如果你與我志同道合於此,老潘很願意與你交流;
- 如果你喜歡老潘的內容,歡迎關注和支援。
- 如果你喜歡我的文章,希望點贊