
Java ThreadPoolExecutor詳解
阿新 • • 發佈:2021-02-21
ThreadPoolExecutor是Java語言對於執行緒池的實現。池化技術是一種複用資源,減少開銷的技術。執行緒是作業系統的資源,執行緒的建立與排程由作業系統負責,執行緒的建立與排程都要耗費大量的資源,其中執行緒建立需要佔用一定的記憶體,而執行緒的排程需要不斷的切換執行緒上下文造成一定的開銷。同時執行緒執行完畢之後就會被作業系統回收,這樣在高併發情況下就會造成系統頻繁建立執行緒。
為此執行緒池技術為了解決上述問題,使執行緒在使用完畢後不回收而是重複利用。如果執行緒能夠複用,那麼我們就可以使用固定數量的執行緒來解決併發問題,這樣一來不僅節約了系統資源,而且也會減少執行緒上下文切換的開銷。
### 引數
ThreadPoolExecutor的建構函式有7個,它們分別是:
1. corePoolSize(int):執行緒池的核心執行緒數量
2. maximumPoolSize(int):執行緒池最大執行緒數量
3. keepAliveTime(long):保持執行緒存活的時間
4. unit(TimeUnit):執行緒存活時間單位
5. workQueue(BlockingQueue):工作佇列,用於臨時存放提交的任務
6. threadFactory(ThreadFactory):執行緒工廠,用於建立執行緒
7. handler(RejectedExecutionHandler):任務拒絕處理器,當執行緒池無法再接受新的任務時,會交給它處理
一般情況下,我們只使用前五個引數,剩餘兩個我們使用預設引數即可。
### 任務提交邏輯
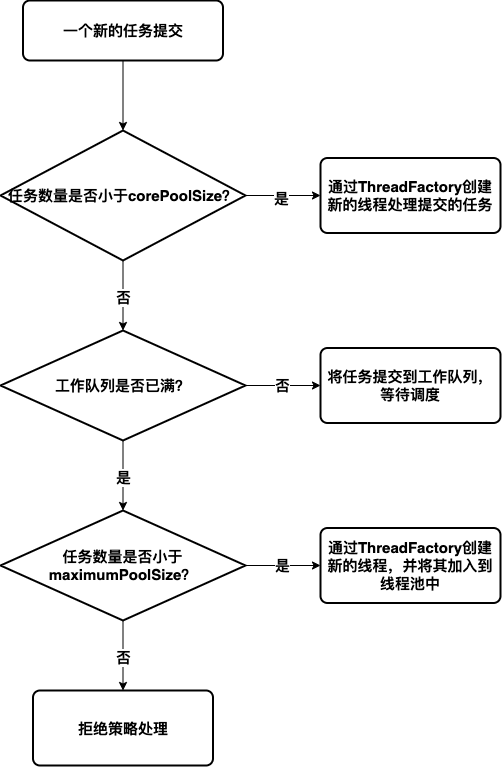
其實,執行緒池建立引數都與執行緒池的任務提交邏輯密切相關。根據原始碼描述可以得知:當提交一個新任務時(執行執行緒池的execute方法)會經過三個步驟的處理。
1. 當任務數量小於`corePoolSize`時,執行緒池會建立一個新的執行緒(建立新執行緒由傳入引數`threadFactory`完成)來處理任務,**哪怕執行緒池中有空閒執行緒,依然會選擇建立新執行緒來處理**。
2. 當任務數量大於`corePoolSize`時,執行緒池會將新任務**壓入工作佇列**(引數中傳遞的`workQueue`)等待排程。
3. 當新提交的任務無法壓入工作佇列時,會檢查當前任務數量是否大於`maximumPoolSize`。如果小於`maximunPoolSize`則會新建執行緒來處理任務(這時我們的`keepAliveTime`引數就起作用了,它主要作用於這種情況下建立的執行緒,如果任務數量減小,這些執行緒閒置了,那麼在超過`keepAliveTime`時間後就會被回收)。如果大於了`maximumPoolSize`就會交由任務拒絕處理器`handler`處理。
### 執行緒池狀態
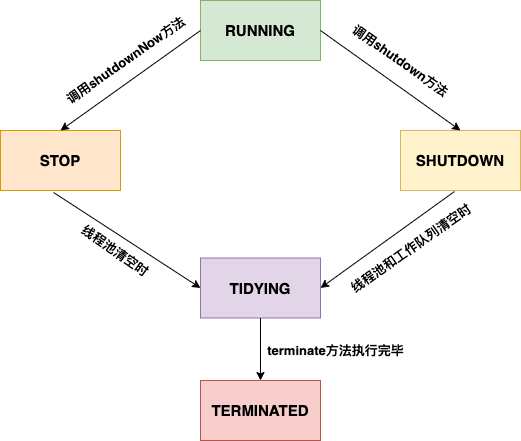
正如執行緒有不同的狀態一樣,執行緒池也擁有不同的執行狀態。原始碼中提出,執行緒池有五種狀態,分別為:
1. RUNNING:執行狀態,不斷接收任務並處理它們。
2. SHUTDOWN:關閉狀態,不接收新任務,但是會處理工作佇列中排隊的任務。
3. STOP:停止狀態,不接收新任務,清空工作佇列且不會處理工作佇列的任務。
4. TIDYING:待終止狀態,此狀態下,任務佇列和執行緒池都為空。
5. TERMINATED:終止狀態,執行緒池關閉。
### 如何讓執行緒不被銷燬
文章開頭說到,執行緒在執行完畢之後會被作業系統回收銷燬,那麼執行緒池時如何保障執行緒不被銷燬?首先看一個測試用例:
```java
public static void testThreadState()
{
Thread thread = new Thread(() -> System.out.println("Hello world")); // 建立一個執行緒
System.out.println(thread.getState()); // 此時執行緒的狀態為NEW
thread.start(); // 啟動執行緒,狀態為RUNNING
System.out.println(thread.getState());
try
{
thread.join();
System.out.println(thread.getState()); // 執行緒執行結束,狀態為TERMINATED
thread.start(); // 此時再啟動執行緒會發生什麼呢?
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
```
結果輸出:
```shell
NEW
RUNNABLE
Hello world
TERMINATED
Exception in thread "main" java.lang.IllegalThreadStateException
at java.base/java.lang.Thread.start(Thread.java:794)
at misc.ThreadPoolExecutorTest.testThreadState(ThreadPoolExecutorTest.java:90)
at misc.ThreadPoolExecutorTest.main(ThreadPoolExecutorTest.java:114)
```
可以看出,當一個執行緒執行結束之後,我們是不可能讓執行緒起死回生重新啟動的。既然如此ThreadPoolExecutor如何保障執行緒執行完一個任務不被銷燬而繼續執行下一個任務呢?
其實這裡就要講到我們最開始傳入的引數`workQueue`,它的介面型別為`BlockingQueue`,直譯過來就是阻塞佇列。這中佇列有個特點,**就是當佇列為空而嘗試出隊操作時會阻塞**。
基於阻塞佇列的如上特點,ThreadPoolExecutor採用**不斷迴圈+阻塞佇列**的方式來實現執行緒不被銷燬。
```java
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 從工作佇列中不斷取任務。如果工作佇列為空,那麼程式會阻塞在這裡
while (task != null || (task = getTask()) != null) {
w.lock();
// 檢查執行緒池狀態
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
//// 執行任務 ////
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
```
### 關閉執行緒池
想要關閉執行緒池可以通過呼叫`shutdown()`和`shutdownNow()`方法實現。兩種方法有所不同,其中呼叫`shutdown()`方法會停止接收新的任務,處理工作佇列中的任務,呼叫這個方法之後執行緒池會進入SHUTDOWN狀態,此方法無返回值並且不丟擲異常。
而`shutdownNow()`方法會停止接收新的任務,而且會返回未完成的任務集合,同時這個方法也會丟擲異常。
### 如何建立一個適應業務背景的執行緒池
執行緒池建立有七個引數,這幾個引數的相互作用可以創建出適應特定業務場景的執行緒池。其中最為重要的有三個引數分別為:`corePoolSize`,`maximumPoolSize`,`workQueue`。其中前兩個引數已經在上文中作了詳細介紹,而`workQueue`引數線上程池建立中也極為重要。`workQueue`主要有三種:
1. SynchronousQueue:這個佇列只能容納一個元素,而且只有當佇列為空時可以入隊。
2. ArrayBlockingQueue:這是一個固定容量大小的佇列。
3. LinkedBlockingQueue:鏈式阻塞佇列,容量無限。
通過上述三種佇列的特性我們可以得知,
1. 當使用SynchronousQueue的時候,總是傾向於新建執行緒處理請求,如果執行緒池大小引數設定的很大,那麼執行緒數量傾向於無限增長。這樣的執行緒池能夠高效處理突發增長的請求,而且處理效率很高,但是開銷很大。
2. 當使用ArrayBlockingQueue的時候,執行緒池所能處理的瞬時最大任務量為**佇列大小 + 執行緒池最大數量**,這樣的執行緒池中規中矩,使用的業務場景很多,具體還需結合業務場景來調配三個引數的大小。例如I/O密集型的場景,多數的執行緒處於阻塞狀態,為了提高系統吞吐量,我們希望能夠有多數執行緒來處理IO。這樣的話我們偏向於將corePoolSize設定的大一點。而且阻塞佇列大小不要設定很大,同時maximumPoolSize也設定的大一點。
3. 當使用LinkedBlockingQueue時,執行緒池的maximumPoolSize引數會失效,因為按照任務提交流程來看,LinkedBlockingQueue可以無限制地容納任務,自然不會出現佇列無法工作,新建執行緒處理的情況。使用LinkedBlockingQueue可以平穩地處理一些請求激增的情況,但是處理效率不會提高,僅僅能夠起到一定的緩衝