數理統計15:擬合優度檢驗(2),列聯表,正態性檢驗
阿新 • • 發佈:2021-02-22
本文我們繼續討論擬合優度檢驗的相關問題。由於本系列為我獨自完成的,缺少審閱,**如果有任何錯誤,歡迎在評論區中指出,謝謝**!
[toc]
## Part 1:分佈未知的Pearson $\chi^2$檢驗
在上篇文章中我們講到了分佈已知的Pearson $\chi^2$檢驗,這是將觀測值分成$r$個組,根據實際頻數$\nu_i$和理論頻數$np_i$計算$\chi^2$統計量
$$
K_n=\sum_{i=1}^r\frac{(\nu_i-np_i)^2}{np_i},
$$
將其近似為$\chi^2_{r-1}$分佈給出擬合優度。其條件是,每一個$p_i$都是已知的,如上例中孟德爾豌豆實驗的$9:3:3:1$,或者具體地服從引數為$3$的泊松分佈,等等。
現在我們要討論的問題是,給定一定的樣本,要檢驗的問題是:它是否服從某一特定的分佈族,如泊松分佈族、均勻分佈族、正態分佈族,等等。它與上文中所討論的情況區別在於,此時不知道每一個具體的$p_i$是多少,自然就不能計算$np_i$是多少。
對於引數分佈族而言,它們的未知性完全由少數幾個引數決定,這就給我們的擬合優度檢驗提供了思路:如果我們能把這些引數變成已知量,那麼$p_i$就已知了,可以照常使用Pearson $\chi^2$檢驗。因此,如果給定了分佈族但沒有給定具體的分佈,則我們可以先估計出未知引數來。
這裡使用的估計方法是點估計,我們選擇普適性更強的極大似然估計,對分佈族$f(x;\theta)$,在給定樣本的情況下,可以先給出$\theta$的**極大似然估計**$\hat\theta$,從而將分佈變為具體的$f(x;\hat\theta)$,再執行適當的分組讓各個$p_i$已知,計算$\chi^2$統計量。
這裡的極大似然估計並不是樣本的極大似然估計,而是**對劃分區間**的極大似然估計,具體地,設$\nu_j$為樣本$X_1,\cdots,X_n$中歸類為第$j$類的個數,則似然函式為
$$
L=\frac{n!}{\nu_1!\cdots\nu_r!}(p_1(\theta))^{\nu_1}\cdots(p_r(\theta))^{\nu_r},
$$
對$\ln L$關於$\theta$求導(如果$\theta$是多維的,則是對向量求導),得到方程:
$$
\sum_{i=1}^r \frac{\nu_i}{p_i(\theta)}\cdot\frac{\partial p_i(\theta)}{\partial\theta}=0,
$$
由此方程解出的$\hat\theta$是我們這裡所需要的極大似然估計,它與由樣本直接計算的極大似然估計是不一樣的。
不過,需要注意的是,由於引數使用了估計量,所以$\chi^2$統計量儘管計算方法相同,但卻不再具有$\chi^2_{r-1}$的極限分佈。Fisher指出:若存在引數空間$\Theta$的**$s$維內點$\theta$**,使得$X$的分佈為$F(x;\theta)$,則對於$\theta$的相合估計量$\hat\theta$,在原假設成立的情況下,有
$$
K_n\stackrel{d}\to \chi^2_{r-1-s}.
$$
> 一般,矩估計不能用於待估引數的估計,尋找待估引數$\hat\theta$可以使用最小$\chi^2$法,即定義
> $$
> K_n(\theta)=\sum_{i=1}^n\frac{(\nu_i-np_i(\theta))^2}{np_i(\theta)},
> $$
> 尋找使得$K_n(\theta)$最小也就是偏離量最小的$\theta$作為引數估計,即求解
> $$
> \frac{\partial K_n(\theta)}{\partial \theta}=0.
> $$
> 這個方程組很難解。
>
> 使用極大似然法,將$\theta$關於劃分區間的極大似然估計作為估計值會更簡單一些,並且也滿足條件。但是這個方程組也不是很容易求解。
>
> 為圖方便,我們可能會想著直接用**樣本的極大似然估計**(如正態分佈中的$\bar X$和$\frac{n-1}{n}S^2$)來作為$\theta$的估計量,這樣計算量就小得多。但是此時$K_n(\theta)$**不一定有極限分佈**$\chi^2_{r-1-s}$,更確切地說來,此時的擬合優度真值是介於$[\mathbb{P}(\chi^2_{r-s-1}\ge k_0),\mathbb{P}(\chi^2_{r-1}\ge k_0)]$之間的。
關於這部分的內容,不再詳細展開,如果能夠計算出引數的估計值,就自然可以算出各個區間的概率,然後用`pearson.chi2()`函式即可計算。不過要注意,此時只有$K_n$的計算值是可用的,擬合優度需要用$\chi^2_{r-s-1}$的分佈來計算。
## Part 2:列聯表
列聯表指的是將每一個樣本的兩類指標$A$和$B$作統計,進而判斷兩個指標之間是否存在一定的關係,典型例子就是吸菸和肺癌之間的關聯。具體地,列聯表相關的問題又可以分為獨立性檢驗與齊一性檢驗,它們都可以使用$\chi^2$檢驗來完成,與擬合優度檢驗類似,又有所不同。
### Section 1:獨立性檢驗
獨立性檢驗指的是,判斷某個個體的兩項指標$A,B$是否相關。一般地,可以將一個由大量個體構成的總體按照指標$A$劃分成$r$級:$A_1,\cdots,A_r$,按照指標$B$劃分成$s$級:$B_1,\cdots,B_s$,第$i$個個體的指標狀況為$(A_{r_i},B_{s_i})$。
這將第$i$個個體看成隨機向量$X_i$,就有$X_i=(r_i,s_i)$。如果不同個體之間相互獨立,就可以將$n$個個體$X_1,\cdots,X_n$視為$n$個從總體$X$中抽取的簡單隨機樣本,指標$A,B$無關就意味著$X=(X^{(1)},X^{(2)})$的兩個分量$X^{(1)},X^{(2)}$相互獨立。記
$$
p_{ij}=\mathbb{P}(X^{(1)}=i,X^{(2)}=j),\quad \forall i=1,\cdots,r;j=1,\cdots,s.
$$
則$X^{(1)},X^{(2)}$獨立的充要條件是:存在$p^{(1)}_1,\cdots,p_r^{(1)}$和$p_1^{(2)},\cdots,p_s^{(2)}\ge 0$使得
$$
\sum_{i=1}^r p_i^{(1)}=1,\quad \sum_{j=1}^s p_j^{(2)}=1,\\
p_{ij}=p_i^{(1)}\cdot p_j^{(2)},\quad \forall i=1,\cdots,r;j=1,\cdots,s.
$$
這樣便定義了一個**含引數的擬合優度檢驗**問題,完成了模型的轉化,接下來的推導步驟請儘可能理解,如果難以理解也可以直接記住結論。
對於列聯表而言,令$n_{ij}$為$X^{(1)}=i,X^{(2)}=j$的樣本個數,則可以作出這樣的列聯表:
$$
\begin{matrix}
& 1 & \cdots & j & \cdots & s \\
1 & n_{11} & \cdots & n_{1j} & \cdots & n_{1s} & n_{1\cdot} \\
\vdots & \vdots & & \vdots & & \vdots & \vdots \\
i & n_{i1} & \cdots & n_{ij} & \cdots & n_{is} & n_{i\cdot} \\
\vdots & \vdots & & \vdots & & \vdots & \vdots \\
r & n_{r1} & \cdots & n_{rj} & \cdots & n_{rs} & n_{r\cdot} \\
& n_{\cdot 1} & \cdots & n_{\cdot j} & \cdots & n_{\cdot s} & n
\end{matrix}
$$
計算表明,應當用$n_{i\cdot}/n$來作為$p_i^{(1)}$的估計值,$n_{\cdot j}/n$來作為$p_j^{(2)}$的估計值,於是計算所得的$\chi^2$統計量為
$$
K_n=\sum_{i=1}^r\sum_{j=1}^s\frac{\left(n_{ij}-n\hat p_i^{(1)}\hat p_j^{(2)}\right)^2}{n\hat p_i^{(1)}\hat p_j^{(2)}}=n\left(\sum_{i=1}^r\sum_{j=1}^s\frac{n_{ij}^2}{n_{i\cdot}n_{\cdot j}}-1 \right).
$$
在獨立性假設成立的情況下,$K_n$應當漸進服從自由度為
$$
rs-1-(r+s-2)=(r-1)(s-1)
$$
的$\chi^2$分佈。
> R語言中有可以直接用於獨立性檢驗的函式,但是計算結果與我們實際的計算式略有不同,因此我們自編一個`chisq.independence()`函式進行獨立性檢驗,程式碼見附錄。
>
> ```R
> > mat <- matrix(c(442, 38, 514, 6), nrow=2)
> > chisq.independence(mat)
>
> Pearson chi2 independence test
>
> The value of K: 27.13874
> p-value: 1.893646e-07
> ```
>
> 此時`p-value`遠小於$0.05$,所以認為獨立性假設不成立。
特別在$r=s=2$時(考試可能出到的範圍),以下公式有助於簡化計算$K_n$的值:
$$
K_n=\frac{n(n_{11}n_{22}-n_{12}n_{21})^2}{n_{1\cdot}n_{2\cdot}n_{\cdot 1}n_{\cdot 2}}.
$$
這是我們在高中時常用的計算式,而高中常用到的$3.841$就是自由度為$1$,$\alpha=0.05$時的臨界值。
### Section 2:齊一性檢驗
齊一性檢驗的提法是$r$個工廠$A_1,\cdots,A_r$生產的產品可以分為$B_1,\cdots,B_s$的$s$個等級,第$i$個工廠的$j$等品率為$p_i(j)$,要驗證的假設是$r$個工廠產品質量相同,即
$$
p_1(j)=\cdots =p_r(j),\quad \forall j=1,\cdots,s.
$$
齊一性檢驗與獨立性檢驗略有不同,其關鍵不同就在於此時$A_1,\cdots,A_r$的$r$個工廠中抽取的產品數不是隨機的,而是可以自由挑選的,也就是說$n_{i\cdot}$是**事先選定的而非隨機的**。這一點關鍵的不同帶來的問題是$\chi^2_{(r-1)(s-1)}$的極限分佈是否依然存在,但幸好,有結論表明,極限分佈依然是$\chi^2_{(r-1)(s-1)}$。對於這種情況,`chisq.independence(mat)`函式依然適用。
齊一性檢驗中還有一種情況,就是$j$等品的分佈是已知的,即要驗證的假設增加為
$$
p_1(j)=\cdots=p_r(j)=p_j^0,\quad \forall j=1,\cdots,s.
$$
此時,未知引數只剩下$p_{1}^{(1)},\cdots,p_{r}^{(1)}$,因而極限分佈的自由度應該是$(rs-1)-(r-s)=r(s-1)$,$K_n$的計算式也自然變成了
$$
K_n=\sum_{i=1}^r\sum_{j=1}^s\frac{(n_{ij}-n_{i\cdot}p_j^0)^2}{n_{i\cdot}p_j^0}\stackrel{d}\to \chi^2_{r(s-1)}.
$$
類似編寫了`chisq.consistency(mat, prob)`函式用於應對這種情況,不過由於書上沒有給出相關例題,我也難以保證這個函式的執行結果是$100\%$正確的。
## Part 3:正態性檢驗
正態性檢驗是檢驗資料是否服從正態分佈的,理論上Pearson $\chi^2$檢驗和柯氏檢驗都可以完成這個任務。我們將其單獨拿出來討論,是因為正態分佈是一種重要的分佈,故需要一些更有針對性的檢驗,而不是使用適用面廣的檢驗。
小樣本下,正態性檢驗的方法是$W$檢驗;大樣本下,正態性檢驗的方法是$D$檢驗。其原理我們不詳述,以下給出R語言中,如何使用這兩種檢驗方法進行正態性檢驗。
$W$檢驗又叫Shapiro-Wilk檢驗,在R中的函式為`shapiro.test()`。其原假設是$H_0$:$X$服從正態分佈,計算出的$W$統計量越大,正態性越強,越應該接受原假設。儘管我們還沒有介紹什麼是檢驗的p-value,不過讀者只需要知道,p-value越大越應該接受原假設,如果p-value小於給定的閾值$\alpha$(可以取$0.05$)就拒絕原假設。以下以書上的例子為例給出$W$檢驗的例項。
```R
> v <- c(57, 66, 74, 77, 81, 87, 91, 95, 97, 109)
> shapiro.test(v)
Shapiro-Wilk normality test
data: v
W = 0.99134, p-value = 0.9982
```
$D$檢驗又叫D 'Agostino檢驗,在R語言的`fBasics`包中提供了`dagoTest()`函式:
```R
> dagoTest(runif(100))
Test Results:
STATISTIC:
Chi2 | Omnibus: 26.2949
Z3 | Skewness: -0.3753
Z4 | Kurtosis: -5.1141
P VALUE:
Omnibus Test: 1.95e-06
Skewness Test: 0.7074
Kurtosis Test: 3.152e-07
```
可以看到,我們使用均勻分佈隨機數時,綜合性檢驗、偏度檢驗、峰度檢驗有兩項都不能通過正態性檢驗。
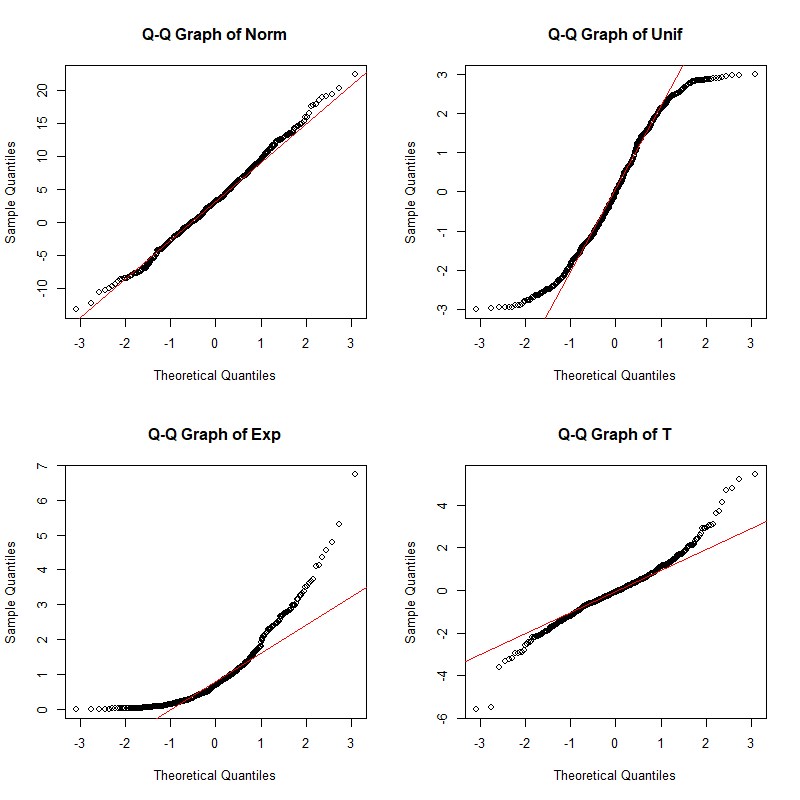
還有一種直觀的檢驗方法:**Q-Q圖檢驗**,其原理是將要檢驗的樣本的次序統計量,按照正態分佈的分佈函式反函式繪製到一張圖上,如果這個散點圖近似呈現一條直線,則認為這個樣本服從正態分佈。當然,這種方法有些主觀,主要依靠人眼,不過由於十分直觀,許多人也喜歡使用這個方法。