
【分散式限流】你被12306的驗證碼坑過麼?
阿新 • • 發佈:2021-02-23
> Stay Hungry,Stay Foolish——
> 求知若飢,虛心若愚
_目錄_
- 前言
- 基本概念
- 解決方案
- 基於guava實現限流
- 閘道器層面實現限流
- 中介軟體實現限流
- 常用限流演算法
- 令牌桶演算法
- 漏桶演算法
- 實戰
- 基於guava的限流實戰
- 基於Nginx限流實戰
- 基於Redis+Lua的限流元件(略)
- 寫在最後
### 前言
相信很多在中小型企業或者TO B企業的小夥伴們都未曾接觸過限流。舉個例子,小夥伴們就會發現,原來軟體限流就在身邊。相信很多小夥伴們都有12306買票回家的體驗吧。如下圖大家應該非常熟悉。
沒錯,這就是坑死人不償命的驗證碼,尤其在搶票的時候(當然今年疫情期間搶票容易很多),不管怎麼選,總是被告知選錯了。要麼就給你一堆鬼都看不出什麼東西的圖,有時候真的讓人懷疑人生。其實這就是一種限流措施,這種故意刁難使用者的手段,光明正大地限制了流量的訪問,大大降低了系統的訪問壓力。
### 基本概念
通過上述例子,老貓覺得小夥伴們至少心裡對限流有了個定數,那麼我們再來細看一下限流的維度。
其實對於一般限流場景來說,會有兩個維度的資訊:
1. **時間**:限流基於某個時間段或者時間點,即“時間視窗”,對每分鐘甚至每秒做限定。
2. **資源**:基於現有可用資源的限制,比方說最大訪問次數或者最高可用連線數。
基於上述的兩個維度,我們基本可以給限流下個簡單的定義,限流就是某個時間視窗對資源訪問做限制。打個比方,每秒最多100個請求。但是在真正的場景中,我們不會僅僅只設定一種限流規則,而是多種規則共同作用。
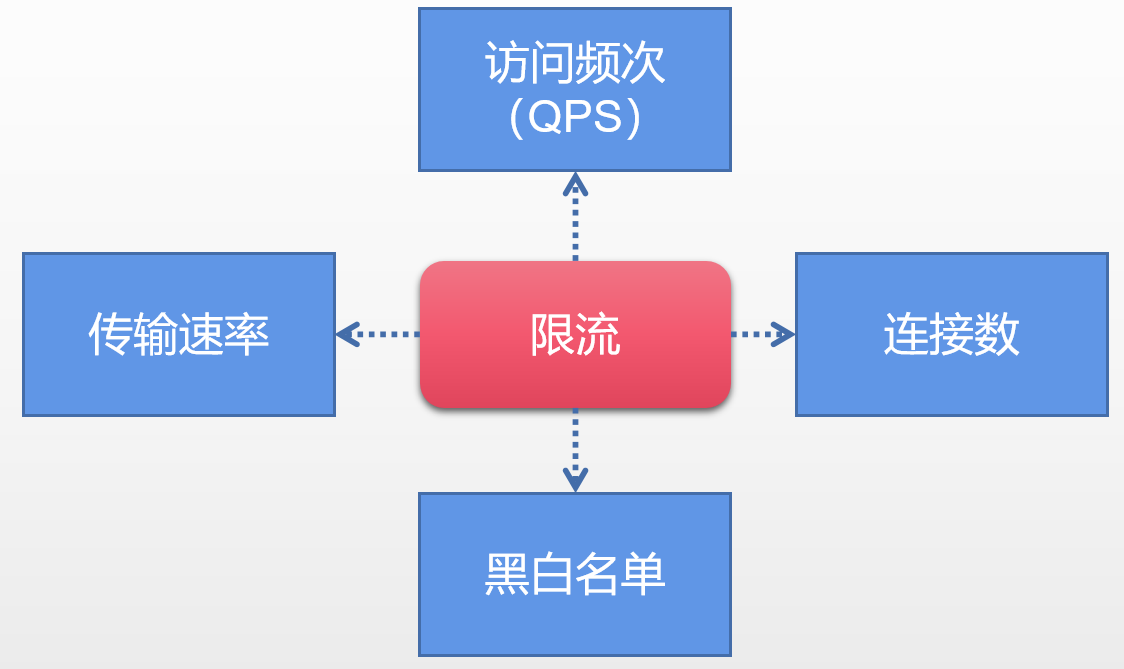
**QPS以及連線數控制**
針對上圖中的連線數以及訪問頻次(QPS)限流來說,我們可以設定IP維度的限流。也可以基於當個伺服器的限流。在實戰的時候通常會設定多個維度限流規則,舉個例子,訪問同一個IP每秒訪問頻率小於10連線小於5,在設定每臺機器QPS最高1000,連線數最大保持200。更進一步的,我們可以把整個伺服器組以及機房當做一個整體,然後設定更高級別的限流規則。關於這個場景,老貓會在本文的後面篇幅給出具體的實現的demo程式碼。
**傳輸速率**
對於傳輸速率,大家應該不陌生,例如某盤如果不是會員給你幾KB的下載,充完會員給你幾十M的下載速率。這就是基於會員使用者的限流邏輯。其實在Nginx中我們就可以限制傳輸速率,demo看本文後面篇幅。
**黑白名單**
黑白名單是很多企業的常見限流以及放行手段,而且黑白名單往往是動態變化的。舉個例子,如果某個IP在一段時間中訪問次數過於頻繁,別系統識別為機器人或者流量攻擊,那麼IP就會被加入黑名單,從而限制了對系統資源的訪問,這就是封IP,還是說到搶火車票,大家會用到第三方的軟體,在進行刷票的時候,不曉得大家有沒有留意有的時候會關進小黑屋,然後果斷時間又被釋放了。其實這就是基於黑名單的動態變化。
那關於白名單的話就更加不用解釋了,就相當於通行證一樣可以自由穿行在各個限流規則中。
**分散式限流**
現在很多系統都是分散式系統,老貓在之前和大家分享了分散式鎖機制。那麼什麼叫做分散式限流呢?其實也很簡單,就是區別於單機限流場景,把整個分散式環境中所有的伺服器當做一個整體去考量。舉個例子,比方說針對IP的限流,我們限制一個IP每秒最多100個訪問,不管落到哪臺機器上,只要是訪問了叢集中的服務節點,就會受到限流約束。
因此分散式的限流方案一般有這兩種:
- 閘道器層限流:流量規則放在流量入口。
- 中介軟體限流:利用中介軟體,例如Redis快取,每個元件都可以從這裡獲取當前時刻的流量統計,從而決定放行還是拒絕。
### 解決方案
老貓本篇文章中主要給大家介紹一下三種解決方案。
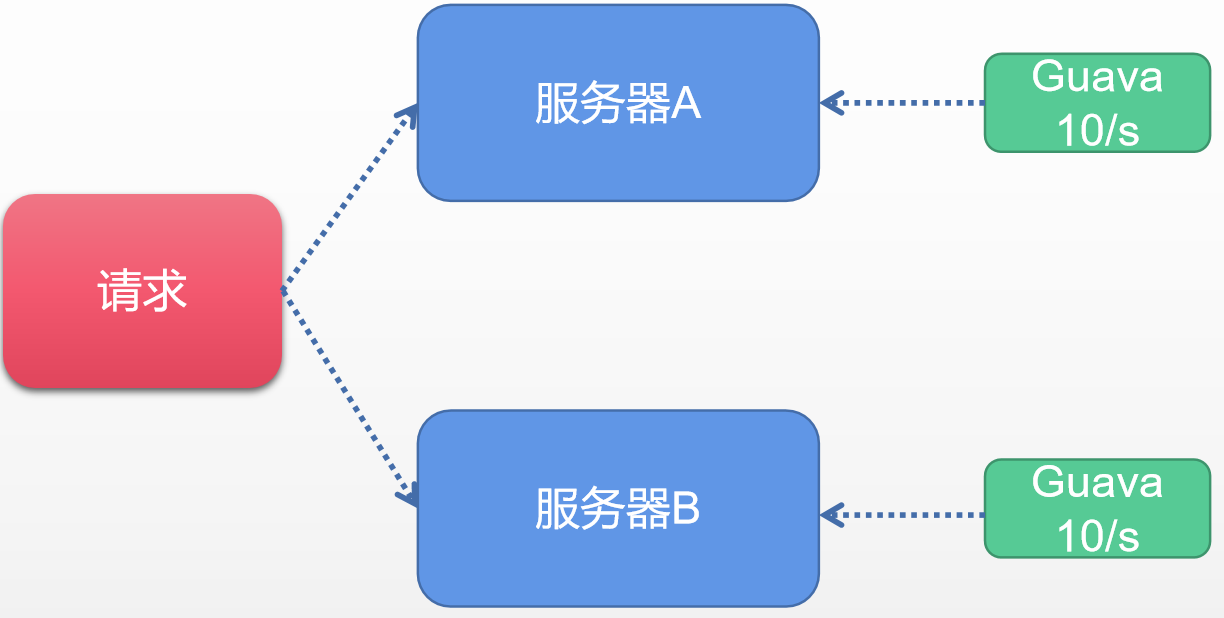
**方案一:基於GUAVA實現限流**
相信很多鐵子比較熟悉guava,它其實是谷歌出品的工具包,我們經常用它做一些集合操作或者做一些記憶體快取操作。但是除了這些基本的用法之外,其實Guava在其他的領域涉及也很廣,其中包括反射工具、函數語言程式設計、數學運算等等。當然在限流的領域guava也做了貢獻。主要的是在多執行緒的模組中提供了RateLimiter為首的幾個限流支援類。Guava是一個客戶端元件,就是說它作用範圍僅限於當前的伺服器,不能對叢集以內的其他伺服器加以流量控制。簡單示例圖如下。
**方案二:閘道器層面實現限流**
咱們直接看個圖,準確地來說應該是個漏斗模型,具體如下:
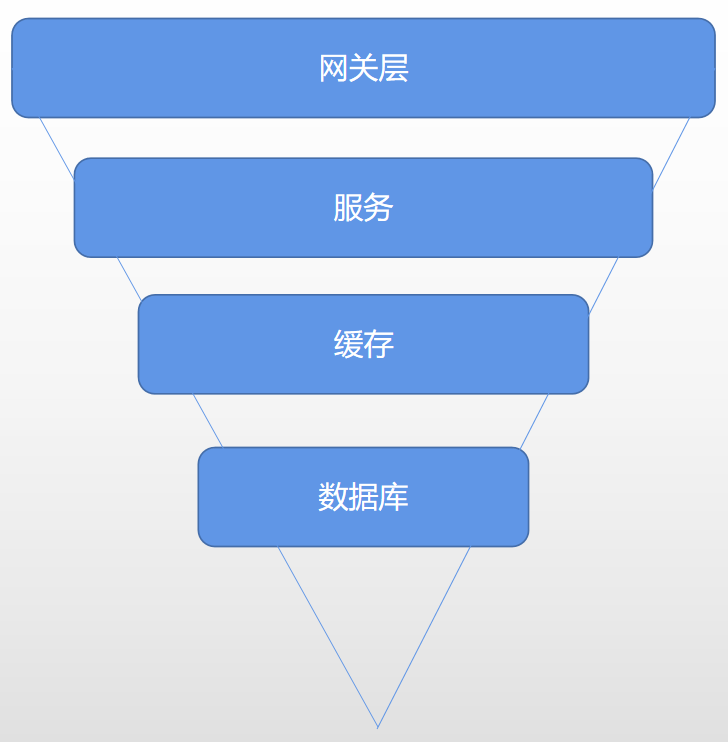
從上圖中我們可以發現這基本是我們日常請求的一個正常的請求流程:
1. 使用者流量從閘道器層到後臺服務
2. 後臺服務承接流量,呼叫快取獲取資料
3. 快取中無資料的情況則回源查詢資料庫
那麼我們為什麼稱呼它為漏斗模型?其實很簡單,因為流量自上而下是遞減的,在閘道器層聚集了最為密集的使用者訪問請求,其次才是後臺服務,經過服務驗證之後,刷掉一部分錯誤請求,剩下的請求落到快取中,如果沒有快取的情況下才是最終的資料庫層,所以資料庫請求頻次是最低的。之後老貓會將閘道器層Nginx的限流演示給大家看。
**方案三:中介軟體限流**
對於開發人員來說,閘道器層的限流需要尋找運維團隊的配合才能實現,但是現在的年輕人控制慾都挺強的,於是大部分開發會決定在程式碼層面進行限流控制,那麼此時,中介軟體Redis就成了不二之選。我們可以利用Redis的過期時間特性,請求設定限流的時間跨度(比如每秒是個請求,或者10秒10個請求)。同時Redis還有一個特殊的技能叫做指令碼程式設計,我們可以將限流邏輯編寫完成一段指令碼植入到Redis中,這樣就將限流的重任從服務層完全剝離出來,同時Redis強大的併發量特性以及高可用的叢集架構也可以很好支援龐大叢集的限流訪問。
### 常用限流演算法
**演算法一:令牌桶演算法(Token bucket)**
Token Bucket令牌桶演算法是目前應用最為廣泛的限流演算法,顧名思義,它由以下兩個角色構成:
- 令牌——獲取到令牌的請求才會被處理,其他請求要麼排隊要麼被丟棄。
- 桶——用來裝令牌的地方,所有請求都是從桶中獲取相關令牌。
簡單令牌處理如下圖:
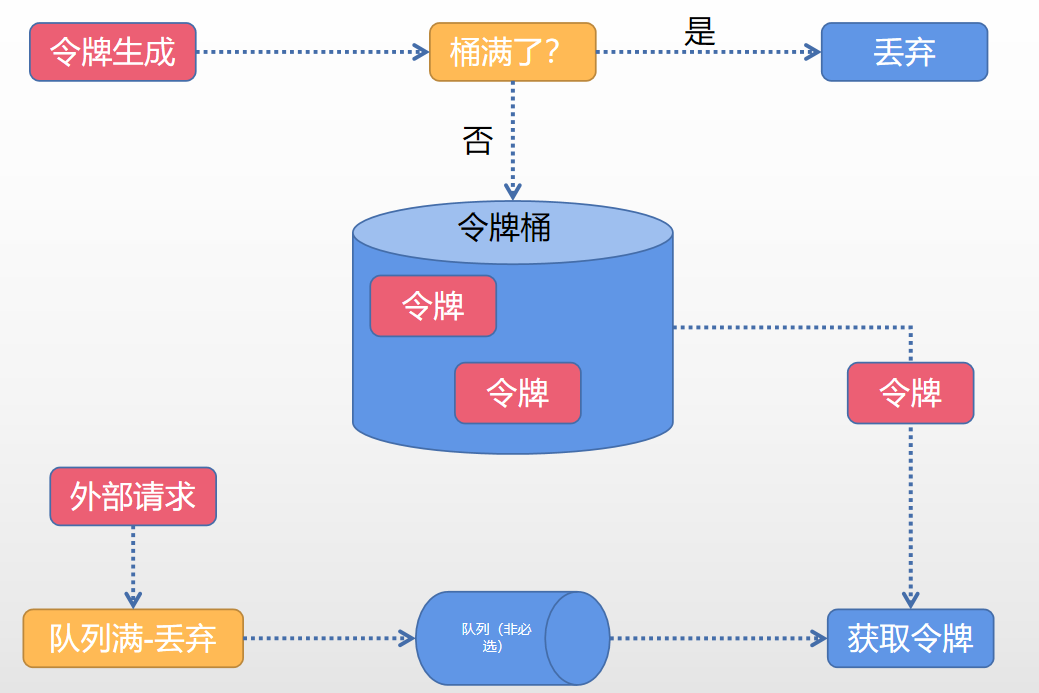
**令牌生成**
該流程涉及令牌生成器以及令牌桶,對於令牌生成器來說,它會根據一個預定的速率向桶中新增令牌,例如每秒100個請求的速率發放令牌。這裡的發放是勻速發放。令牌生成器類比水龍頭,令牌桶類比水桶,當水盛滿之後,接下來再往桶中灌水的話就會溢位,令牌發放性質是一樣的,令牌桶的容量是有限的,當前若已經放滿,那麼此時新的令牌就會被丟棄掉。(大家可以嘗試先思考一下令牌發放速率快慢有無坑點)。
**令牌獲取**
每個請求到達之後,必須獲取到一個令牌才能執行後面的邏輯。假如令牌的數量少,而訪問請求較多的情況下,一部分請求自然無法獲取到令牌,這個時候我們就可以設定一個緩衝佇列來儲存多餘的令牌。緩衝佇列也是一個可選項,並不是所有的令牌桶演算法程式都會實現佇列。當快取佇列存在的情況下,那些暫時沒有獲取到令牌的請求將被放到這個佇列中排隊,直到新的令牌產生後,再從佇列頭部拿出一個請求來匹配令牌。當佇列滿的情況下,這部分訪問請求就被拋棄。其實在實際的應用中也可以設定隊裡的相關屬性,例如設定佇列中請求的存活時間,或者根據優先順序排序等等。
**演算法二:漏桶演算法(Leaky Bucket)**
示意圖如下:
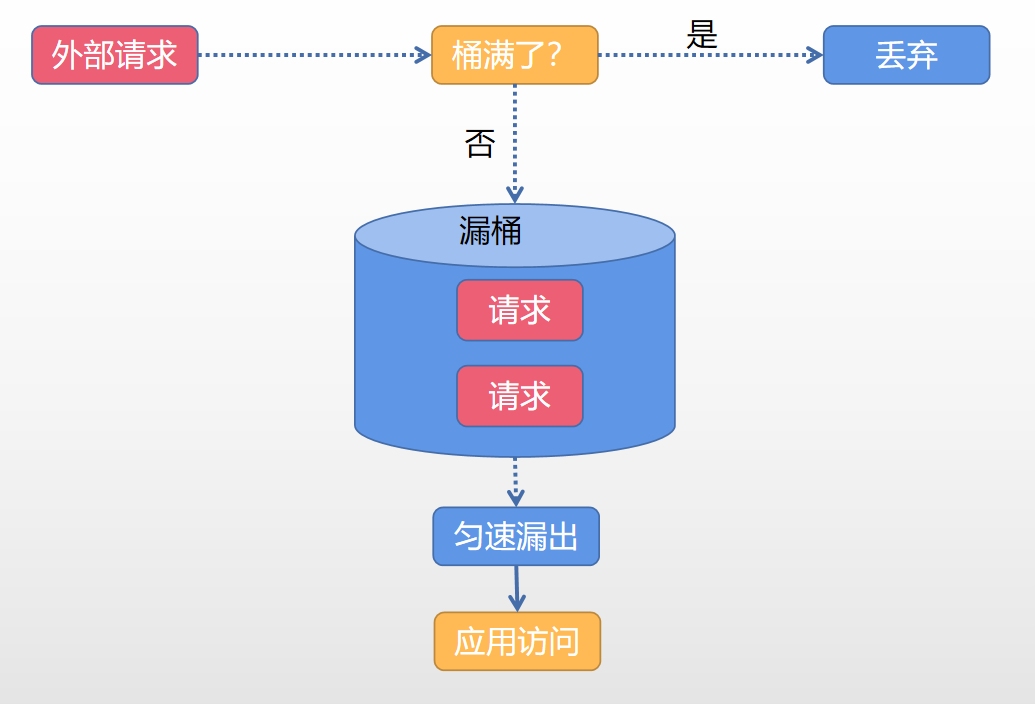
漏桶演算法判斷邏輯和令牌桶有所類似,但是操作物件不同,令牌桶是將令牌放入桶內,而漏桶是將請求放到桶中。一樣的是如果桶滿了,那麼後來的資料會被丟棄。漏桶演算法只會以一個恆定的速度將資料包從桶內流出。
兩種演算法的聯絡和區別:
- 共同點:這兩種演算法都有一個“恆定”的速率和“不定”的速率。令牌桶是以恆定的速率建立令牌,但是訪問請求獲取令牌的速率是不定的,有多少令牌就發多少,令牌沒了只能等著。漏桶演算法是以很定的速率處理請求,但是流入桶內的請求的速度是不定的
- 不同點:漏桶天然決定它不會發生突發流量,就算每秒1000個請求,它後來服務輸出的訪問速率永遠都是恆定的。然而令牌桶不同,其特性可以“預存”一定量的令牌,因此在應對突發流量的時候可以在短時間裡消耗所有的令牌。突發流量的出率效率會比漏桶來的高,當然對應後臺系統的壓力也會大一些。
### 限流實戰
#### 基於guava的限流實戰
pom依賴:
```xml
```
demo程式碼:
```java
// 限流元件每秒允許發放兩個令牌
RateLimiter limiter = RateLimiter.create(2.0);
//非阻塞限流
@GetMapping("/tryAcquire")
public String tryAcquire(Integer count){
// 每次請求需要獲取的令牌數量
if (limiter.tryAcquire(count)){
log.info("success, rate is {}",limiter.getRate());
return "success";
}else {
log.info("fail ,rate is {}",limiter.getRate());
return "fail";
}
}
//限定時間的阻塞限流
@GetMapping("tryAcquireWithTimeout")
public String tryAcquireWithTimeout(Integer count, Integer timeout){
if (limiter.tryAcquire(count,timeout, TimeUnit.SECONDS)){
log.info("success, rate is {}",limiter.getRate());
return "success";
}else {
log.info("fail ,rate is {}",limiter.getRate());
return "fail";
}
}
//同步阻塞限流
@GetMapping("acquire")
public String acquire(Integer count) {
limiter.acquire(count);
log.info("success, rate is {}",limiter.getRate());
return "success";
}
```
關於guava單機限流的演示,老貓簡單地寫了幾個Demo。guava單機限流主要分為阻塞限流以及非阻塞限流。大家啟動專案之後,可以調整相關的入參來觀察一下日誌的變更情況。
老貓舉例分析一下其中一種請求的結果 localhost:10088/tryAcquire?count=2;請求之後輸出的日誌如下:
```tex
2021-02-18 23:41:48.615 INFO 5004 --- [io-10088-exec-9] com.ktdaddy.KTController:success,rate is2.0
2021-02-18 23:41:49.164 INFO 5004 --- [io-10088-exec-2] com.ktdaddy.KTController:success, rate is2.0
2021-02-18 23:41:49.815 INFO 5004 --- [o-10088-exec-10] com.ktdaddy.KTController:success, rate is2.0
2021-02-18 23:41:50.205 INFO 5004 --- [io-10088-exec-1] com.ktdaddy.KTController:fail ,rate is 2.0
2021-02-18 23:41:50.769 INFO 5004 --- [io-10088-exec-3] com.ktdaddy.KTController:success,rate is 2.0
2021-02-18 23:41:51.470 INFO 5004 --- [io-10088-exec-4] com.ktdaddy.KTController:fail ,rate is 2.0
```
從請求日誌中我們神奇地發現前兩次請求中間間隔不到一秒,但是消耗了令牌確都是成功的。這個是什麼原因呢?這裡面賣個關子,後面再和大家同步一下guava的流量預熱模型。
#### 基於Nginx限流實戰
nginx.conf限流配置如下:
```nginx
# 根據 IP地址限制速度
# (1)第一個引數 $binary_remote_addr:可以理解成nginx內部系統的變數
# binary_目的是縮寫記憶體佔用,remote_addr表示通過IP地址來限流
#
# (2)第二個引數 zone=iplimit:20m
# iplimit是一塊記憶體區域,20m是指這塊記憶體區域的大小(專門記錄訪問頻率資訊)
# (3)第三個引數 rate=1r/s,標識訪問的限流頻率
# 配置形式不止一種,還例如:100r/m
limit_req_zone $binary_remote_addr zone=iplimit:20m rate=10r/s;
# 根據伺服器級別做限流
limit_req_zone $server_name zone=serverlimit:10m rate=1r/s;
# 基於IP連線數的配置
limit_conn_zone $binary_remote_addr zone=perip:20m;
# 根據伺服器級別做限流
limit_conn_zone $server_name zone=perserver:20m;
# 普通的服務對映域名limit-rate.ktdaddy.com對映到http://127.0.0.1:10088/服務。
# 大家本地可以通過配置host對映去實現,很簡單,不多贅述。
server {
server_name limit-rate.ktdaddy.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:10088/;
# 基於IP地址的限制
# 1)第一個引數 zone=iplimit => 引用limit_req_zone的zone變數資訊
# 2)第二個引數 burst=2,設定一個大小為2的緩衝區域,當大量請求到來,請求數量超過限流頻率的時候
# 將其放入緩衝區域
# 3)第三個引數 nodelay=> 緩衝區滿了以後,直接返回503異常
limit_req zone=iplimit burst=2 nodelay;
# 基於伺服器級別的限制
# 通常情況下,server級別的限流速率大於IP限流的速率(大家可以思考一下,其實比較簡單)
limit_req zone=serverlimit burst=1 nodelay;
# 每個server最多保持100個連結
limit_conn perserver 100;
# 每個Ip地址保持1個連結地址
limit_conn perip 1;
# 異常情況返回指定返回504而不是預設的503
limit_req_status 504;
limit_conn_status 504;
}
# 簡單下載限速的配置,表示下載檔案達到100m之後限制速度為256k的下載速度
location /download/ {
limit_rate_after 100m;
limit_rate 256k;
}
}
```
上面配置裡面其實結合了nginx限流四種配置方式,分別是基於ip的限流方式,基於每臺服務的限流,基於IP連線數的限流,基於每臺服務連線數的限流。當然最後還給大家提到了下載限速的配置。大家有興趣可以模擬配置一下,體驗一下基於nginx的限流。
#### 基於Redis+Lua的限流元件
此處還是比較重要的,老貓決定單獨作為一個知識點和大家分享,此處暫時省略。
### 寫在最後
本文和大家分享了限流的相關概念以及實際中我們的應用還有相關的演算法以及實現。關於redis+lua指令碼的限流實現方式暫時沒有做分享。個人覺得還是比較實用的,後面單獨拉出來和大家分享,敬請期待,更多技術乾貨也歡迎大家關注公眾號“程式設計師老