
(十二)資料庫查詢處理之Query Execution(1)
阿新 • • 發佈:2021-02-28
## (十二)資料庫查詢處理之Query Execution(1)
### 1. 寫在前面
1. 這一大部分就是為了**Lab3**做準備的
2. 每一個query plan都要實現一個next函式和一個init函式
> 對於next函式每次呼叫時,返回一個元組或空標記(如果沒有更多元組
### 2. 迭代模型(ITERATOR MODEL)

對於上面這個圖的理解就是獲取所有的`r.id`然後構建hash表

然後在right的關係中獲取出所有滿足要求的`S.ID`
這裡的`evalPred(t)`就等價於 `S.value > 100`
幾乎所有的DBMS都是用上面的方法。但是允許我們流水線化的實現
> 不過一些操作必須是順序化的如Joins、Order By
### 3. MATERIALIZATION 模型
一次處理所有輸入,然後一次獲得它的所有輸出。

可以發現這種實現沒有了next函式(可以把next理解成一種迭代器)
而是在一個`list`中放了所有滿足要求的輸入。然後最後也是獲得所有輸出
對於OLTP(主要是對資料的增刪改)工作負載更好,因為一次訪問少量元組。→降低執行/協調開銷。→更少的函式呼叫。
Not good for OLAP(主要是對於大型資料的分析) queries with large intermediate results.
### 4. VECTORIZATION 模型
和上面模型的區別是這種模型用`batch`代替了全部

這種方法適合`OLAP`因為它大大減少了每個運算子的執行次數
### 5. 對於順序掃描的優化
DBMS可以訪問儲存於table中的資料的最簡單方法莫過於順序掃描法
```python
for page in table.pages:
for t in page.tuples:
if (check(t)):
// DO something
```
很顯然這種方法不好。下面來看一些對於這個方法的簡單優化
**1. Zone MAPS**
先維護一些關於這個page 的資訊
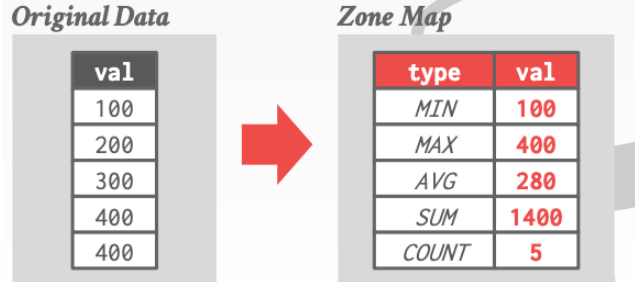
對於這個page那們我們如果要執行
```sql
SELECT * FROM TABLE WHERE val > 500
```
我們就不用訪問這個`page`了因為我們通過`Zone Map `知道了這個`page`裡最大的val為400.
**2. LATE MATERIALIZATION**
DBMS可以延遲拼接元組。到最上層的操作再進行元祖拼接
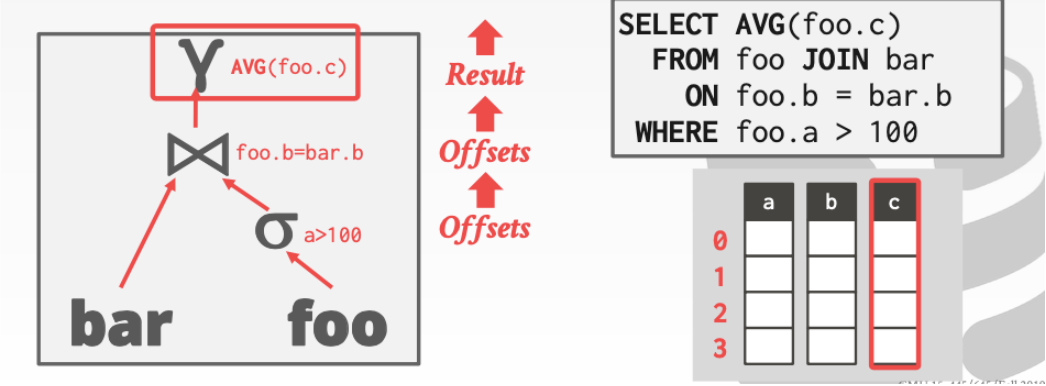
對於上面,這個操作而言我們進行一些分析
1. 獲取a表中滿足要求的行號比如(0 ,1,3)並往上傳遞
2. 獲取b中在(0,1,3)行滿足要求的行號比如(0,3)然後繼續往上傳遞
3. 在最上層元素我們就可以直接在c中的(0,3)行進行AVG操作
**3. HEAP CLUSTERING**
就是前面說過的聚簇索引。
### 6. index scan
1. **多index scan**

這個比較簡單對於每一個索引根據條件獲取一個集合。然後把集合結合起來最後根據另一個查詢條件獲得結果
**2. INDEX SCAN PAGE SORTING**
檢索元組在非聚簇索引中是十分低效的
DBMS可以根據page id對於元組進行排序。這樣就可以把我們隨機訪問變成順序訪問

### 7. EXPRESSION EVALUATION
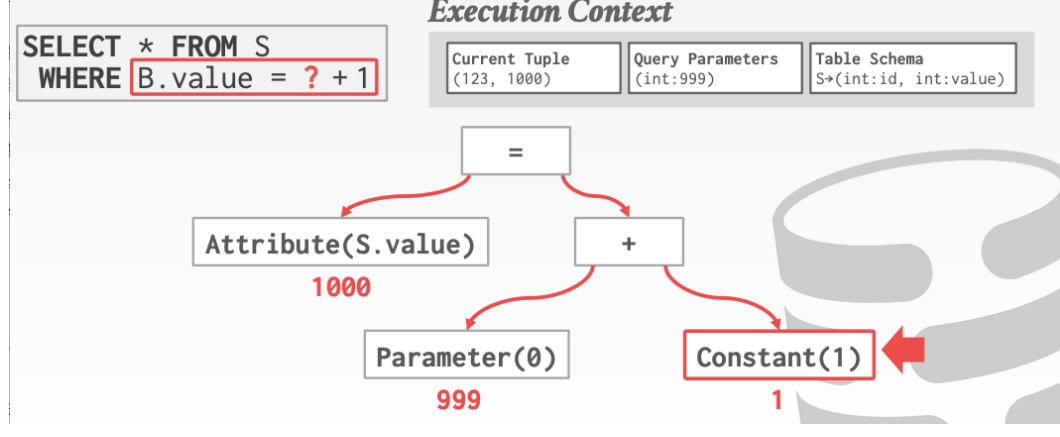
當執行語句發生的時候。我們會有一個`Execution Context`的東西來儲存我們的上下文
上下文中包含
```tex
當前元組
執行的引數
Table的Scheme
```
### 8.總結
1. 相同的query plan 會有不同的執行方法
2. 要儘可能多的利用index scan
3. 表示式樹雖然很直觀但是