
部落格資料庫要連線Elasticsearch,使用MySQL還是MongoDB更合理
阿新 • • 發佈:2021-02-28
若進行部落格等文字類資料的讀寫以及專業搜尋引擎的連線的解決方案對比,可以肯定的下結論:MongoDB的解決方案中要遠遠好於MySQL的解決方案。
# 一、從開發工序角度
**MySQL的文章讀寫方式**
**方式一:**文章標題、作者、標籤、時間和內容存關係表,圖片存OSS,地址存關係表
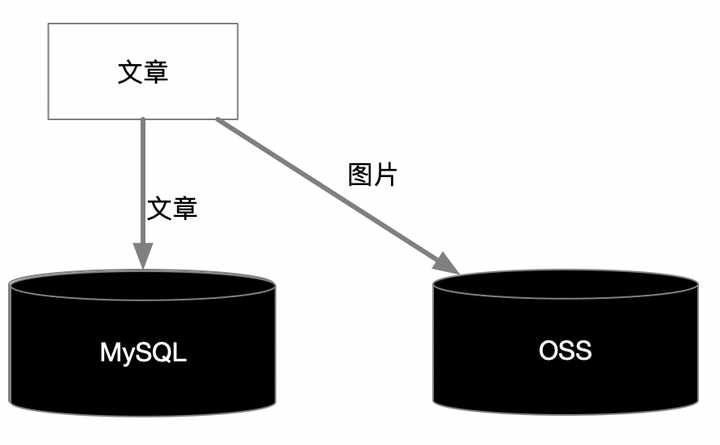
上述方式因為OSS和MySQL沒有事務關係,因此需要編輯文章過程中儲存圖片和儲存草稿都是分開設計,後臺寫入是分開執行,查詢過程更適合前端非同步獲取圖片,另外OSS需要額外的訪問授權。
最最關鍵的問題是OSS收費!
**方式2:**文章標題、作者、標籤、時間和內容存關係表,圖片存本地,地址存關係表,Nginx作為圖片查詢代理
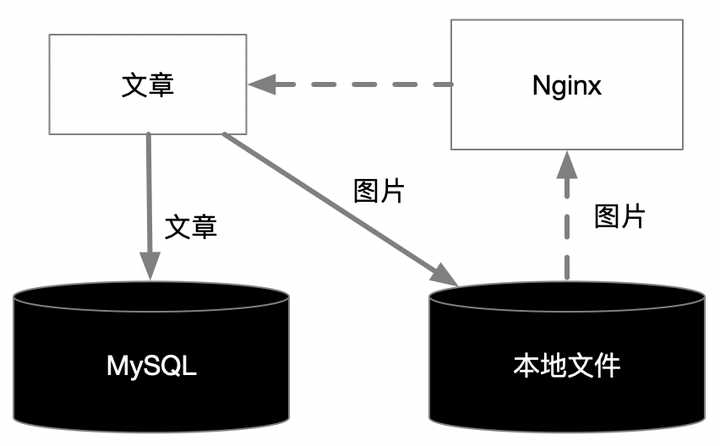
上圖中實線為寫入過程,虛線為查詢過程。寫入本地檔案的過程依然無法保證事務,因此仍需要後臺分開執行,查詢過程Nginx的業務授權非常麻煩,需要引入Openresty和授權伺服器的對接,而且檔案的儲存存在檔案數超過作業系統最大限制的可能,圖片缺乏可靠性備份機制。
唯一的好處就是圖片儲存本地不用額外付費。
**我們再看看MongoDB文章讀寫方式**
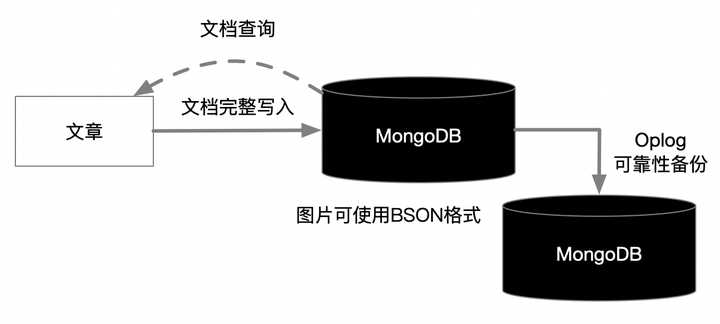
如上圖**方式一**:整存整取,MongoDB可以將文章標題、作者、標籤、時間和內容,圖片存在一個集合中,那麼圖片為BSON格式,形成整存整取,若文章+圖片的完整文件不超過16M,是BSON比較合適。
若文件因為圖過大,超過16M,就使用**方式二**,使用MongoDB提供的GridFS外掛存取。
**方式一:**從開發工序上最簡單,但不適合太大圖片,導致文件整體超過16M。
**方式二:**相當於需要訪問不同的MongoDB資料庫,從程式碼複雜度上就要更高,而且一致性控制不如方式一好。
其他優勢:這兩種方式都可以得到MongoDB的統一訪問控制保護。這兩種方式都使圖片通過副本集實現可靠性備份。
但最最關鍵的是沒有MySQL變扭的超出技術範圍的架構考慮,到底用OSS要收費,還是用Http代理的免費模式,容忍可靠性、複雜性及安全性問題超級大的情況。
# 二、從效能角度看
**1、文章插入效能**
從目前MongoDB4實測情況看,給定時間段內資料寫入量級越大,MongoDB的完成時間就比MySQL的完成時間越短。因此部落格網站平臺或者部落格爬蟲系統,寫入的資料量特別大的情況下,MongoDB可以提供更優越的負載能力。
**2、伸縮性**
MongoDB和MySQL都可以進行資料庫級的記憶體快取,但是MongoDB可以將文件最大可能的快取在記憶體中,得到最優的效能表現。若記憶體不夠的情況出現就會溢位到磁碟中,那麼效能就會減弱,這個時候可以通過水平分割槽實現,更好的記憶體表現。
MySQL的分片必須通過自研或引入第三方的分片應用實現手動分片,即一張資料表遷移到不同MySQL庫中,按照資料記錄進行分表,最終達到分片應用對多庫實現負載均衡的目的,這種方式的缺點就是實現分片的過程非常複雜和麻煩。
MongoDB的分片屬於其核心架構之一,也是NoSQL天然所擅長的能力,因此MongoDB可以在使用者不干預的情況下實現集合分片,這比MySQL的手動分片不知道要輕鬆多少。
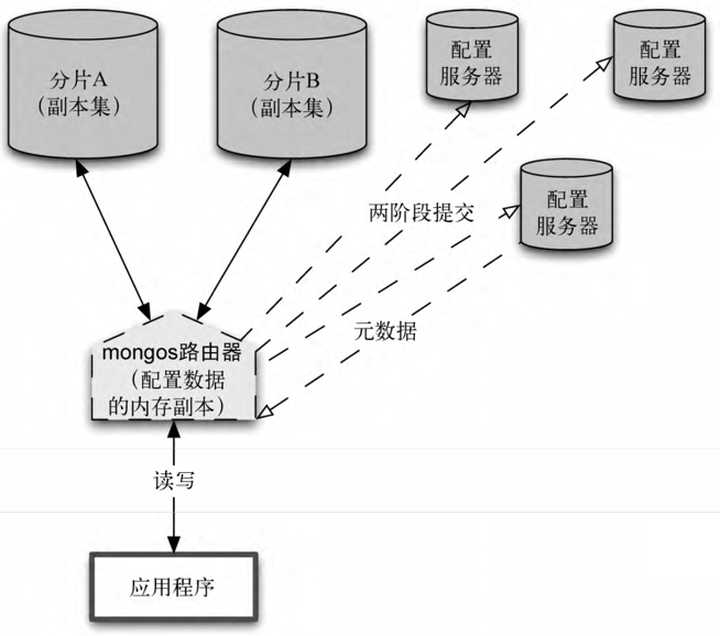
上圖中Mongos路由器作為介面,連線整個叢集,將所有的讀寫請求指引到合適的分片上,配置伺服器持久化分片叢集的元資料,以及資料在分片之間進行遷移的歷史資訊,而且配置伺服器本身也是高可靠的。
# 三、與Elasticsearch連線角度看
**MySQL連線Elasticsearch**
一種方式可以通過CDC(資料變更捕獲)工具抓取binglog到Kafka,再由Kafka管道輸出到Elasticsearch
另一種方式通過JDBC輪詢資料庫,再推送Elasticsearch
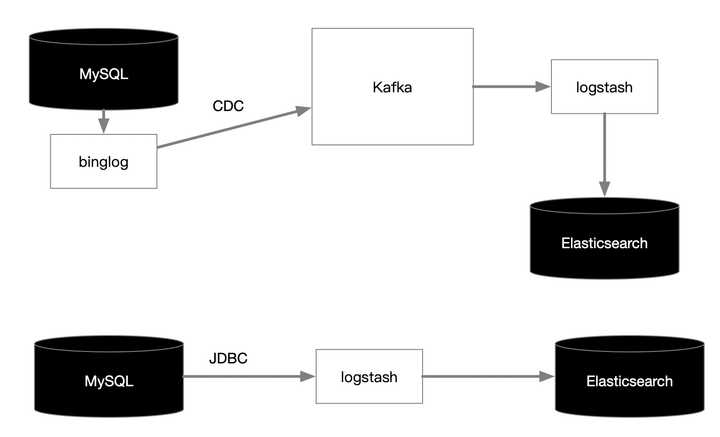
第一種方式在引入CDC抓取工具,例如debezium後,會讓整個流程非常複雜,經歷的環節過多,仍要控制好Kafka的按鍵分割槽和摺疊模式,資料管道也要解決關係結構向文件結構的ETL過程。
當然方式一也可以不用Kafka,直接走Logstash管道的過濾通道,但是第三方CDC抓取工具就要再考慮一層與Logstash的對接過程。
第二種方式雖然簡單,不過JDBC輪詢對MySQL有不小的影響,而且業務表需要提供變化日誌表,再有Logstash等清洗程式再做ETL合併同步,這個過程也不容易。
**我們再看MongoDB連線Elasticsearch**
通過mongo-connector可以輕鬆實現MongoDB到Elasticsearch的資料實時同步
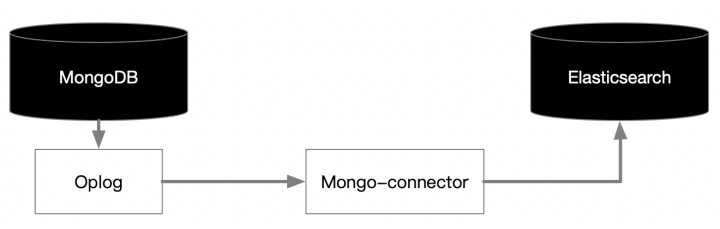
mongo-connector通過監聽Oplog,非常類似MySQL CDC工具對binglog的監聽,實時對資料進行採集並直接同步到Elasticsearch中,因為MongoDB和Elasticsearch都是無模式的文件型資料庫,因此ETL過程可以由mongo-connector工具實現MongoDB集合向ES索引的無縫寫入,會省去ETL過程很大的麻煩。
# 四、總結
從上面的架構描述上,其實已經強有力的論證了MongoDB無論作為儲存文件型的部落格文章也好,還是與其他專有搜尋引擎同步也好,相對於MySQL,是更好的解決方案。
> 我們是“讀位元組”技術專家團隊,感謝您的關注! [讀位元組官網](http://www.readby