
Redis快取穿透、快取雪崩、快取擊穿好好說說
阿新 • • 發佈:2021-03-01
### 前言
Redis是目前非常流行的快取資料庫啦,其中一個主要作用就是為了避免大量請求直接打到資料庫,以此來緩解資料庫伺服器壓力;用上快取難道就高枕無憂了嗎?no,no,no,沒有這麼完美的技術, 快取穿透、快取雪崩、快取擊穿這些問題都得好好聊聊。
### 正文
#### 1. 快取穿透
##### 1.1 簡要描述
**快取穿透**是指查詢的資料**在快取和資料庫中都不存在**,導致每一次請求資料**從快取中都獲取不到**,而將請求打到資料庫伺服器,但資料庫中也沒有對應的資料,最後每一次請求都到資料庫;如果在高併發場景或有人惡意攻擊,就會導致後臺資料庫伺服器壓力增大,最終系統可能崩掉。來個直接點的圖:
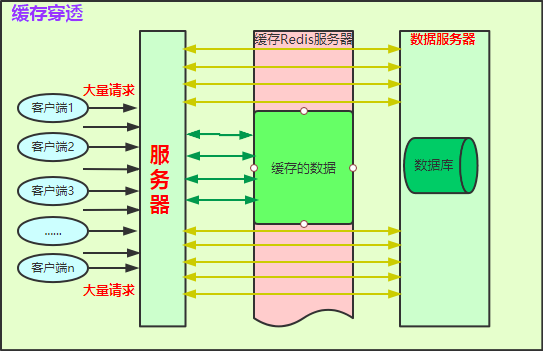
簡要說明:
快取Redis伺服器顏色說明:**綠色塊**代表有快取資料,**粉色塊**代表快取中沒有資料;**綠色箭頭**代表直接從快取中獲取資料;**黃色箭頭**代表穿過快取從資料庫中查資料,但不一定有。
流程大概如下:
1. 大量客戶端發起大量請求到伺服器;
2. 伺服器程式碼邏輯將先經過快取,如果**有快取資料(綠色部分)**,直接從快取中獲取資料資料返回;如果快取中**沒有資料(粉色部分)**,請求就會直接打到資料庫伺服器(如黃色箭頭)。
3. 如果存在大量無快取資料的請求,最終資料庫將因為過大壓力而崩掉,導致系統不可用。
##### 1.2 常用解決措施
- **快取空值**:如果沒有在資料庫中獲取到資料,可以將其對應鍵的空值進行快取,並設定較短過期時間;
優點:在過期時間內直接通過快取返回空值;從而避免資料庫壓力;
缺點:
消耗Redis記憶體:如果是攻擊者換著非常規的鍵值請求,如果每次都快取到Redis中,大量的空資料也佔記憶體空間;
資料不一致:如果是正常資料,剛開始沒有資料,然後將空值進行快取,並設定短暫的過期時間;如果在過期時間內正常維護了對應的資料,此時取到值仍是空,並沒有去資料庫中獲取新維護資料,導致資料獲取不一致。
- **布隆過濾器**
加一層過濾器進行攔截,判斷請求對應的鍵是否在過濾器中,如果不在就直接返回,不去請求資料庫,也不用快取空值。而布隆過濾器採用bit位的形式標識對應鍵(每個鍵進行Hash過後都會得到具體的位置)是否存在,可以用極少的空間標識超大量的資料。
缺點:布隆過濾器可以判斷資料一定不在過濾器中,而對於存在的判斷有誤判率,因為Hash演算法存在衝突的情況。
##### 1.3 布隆過濾器
布隆過濾器不是專門用來針對快取穿透的,它的應用場景很多,比如避免郵件重發、爬蟲軟體重爬、視訊推送重複等;可能有的小夥伴還不明白為什麼可以這麼用,那先簡單說說布隆過濾器的原理。
瞅個圖先:
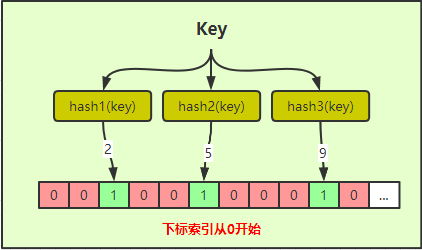
簡要說明:
1. 先來一個Key,後續需要判斷Key是否存在(這裡Key可以是任意想存的資料,比如使用者ID、視訊標識等);
2. 將Key進行多次hash計算;每次的hash演算法得到的結果都不一樣;上圖只畫了三次hash計算,其實實際根據誤判率不一樣,hash次數就不一樣;
3. 將hash結果對應下標索引的bit位改為1,表示存在; 上圖經過三次hash,結果分別為2、5、9,則將對應的位置改為1;
4. 如果需要判斷Key是否在過濾器中,同樣需進行多次hash計算,上圖為三次,將計算出來的結果作為索引去獲取對應的標識,三次中只要有一次對應位置的值為0,那就證明Key不存在過濾器中。 如果是判定存在,則三次的結果對應位置的值應該都為1,不過這樣是有誤判可能,因為不同的Key,hash的結果有可能是一樣的,從而就導致設定對應索引位時就會有衝突,如下圖;
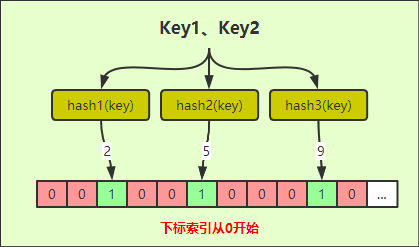
先假設Key1、Key2經過三次hash的結果一樣(實際場景是存在的),倘若Key1先來都將2、5、9位置的值設為1,那Key2進來判斷存在時,由於hash的結果一樣,從而就誤判為在過濾器中,其實不存在;
誤判率在布隆過濾器中是可以控制,如果需要降低誤判率,那就多進行幾次hash計算,那位置相同的概率就降低啦;但這樣會影響效率,另外也會有記憶體的額外開銷,hash次數多,需要標識的位就越多。 就算有誤判率,也很小,在絕大多數場景下可接受。
##### 1.4 布隆過濾器的使用
既然說Redis,就說Redis的布隆過濾器吧,其實小夥伴可以根據自己的需求利用Redis的bitmap實現。那有沒有造好的輪子呢,當然有,在Redis4.0開始就有一個布隆過濾器的元件,開箱即用,當然也有一些其他大佬封裝的,基於記憶體的,基於分散式都有。這裡簡單說說Redis布隆過濾器的外掛,個人覺得挺好的,推薦哦。
官方文件地址:https://oss.redislabs.com/redisbloom/
我這面是用centos進行演示,主要步驟如下:
1. 如果沒有git的需要安裝一下;如果不用git就去下載程式碼壓縮包;
```bash
yum install -y git
```
2. 把redis布隆過濾器的原始碼搞下來,這裡用git;也可以通過下載的方式;
```bash
git clone https://github.com/RedisLabsModules/redisbloom.git
```
3. 進入程式碼目錄進行make(生成redisbloom.so檔案),如果make命令找不到,就需要安裝VC++編譯相關的包;
```bash
cd redisbloom
make
```
4. 在Redis配置檔案中配置載入redisbloom外掛,然後重啟就可以用啦;也可以啟動的時候指定載入外掛執行;
配置檔案方式式:在配置檔案中新增如下配置,需要指定redisbloom.so具體的檔案位置。
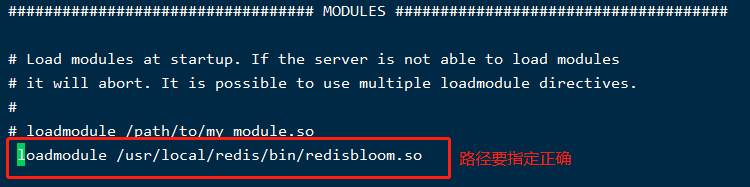
然後指定配置檔案啟動即可;
```bash
./redis-server redis.conf
```
啟動時指定模組執行方式:
```bash
./redis-server --loadmodule ./redisbloom.so
```
5. 簡單使用

命令使用和常規命令一樣啦,就不需要我再寫程式了吧,如果非要的話,那就簡單說兩句:
A.將需要判斷資料儲存在過濾器中,比如所有的使用者id;
B.當請求過來時就先從過濾器中判斷有無資料,沒有直接返回,不去快取,也不去資料庫;
C.如果有新新增的使用者,需要將新的使用者id放到過濾器中;
關於Redis布隆過濾器還有一些命令沒說,小夥伴可以去逛逛官網。有小夥伴說,不用這個外掛行嗎,當然行啊,可以自己實現嘛,不過有些小夥伴有封裝好的包啦,有基於記憶體的,也有基於Redis的,如下圖:
程式碼我就不上了,剩下的就留給小夥伴啦。
#### 2. 快取雪崩
##### 1.1 簡要描述
快取雪崩是指突然快取層不可用,導致大量請求直接打到資料庫,最終由於資料庫壓力過大可能導致系統崩掉。快取層不可用指以下兩方面:
- 快取伺服器宕機,系統將請求打到資料庫;
- 快取資料突然大範圍集中過期失效,導致大量請求打到資料庫重新載入資料;
如圖:
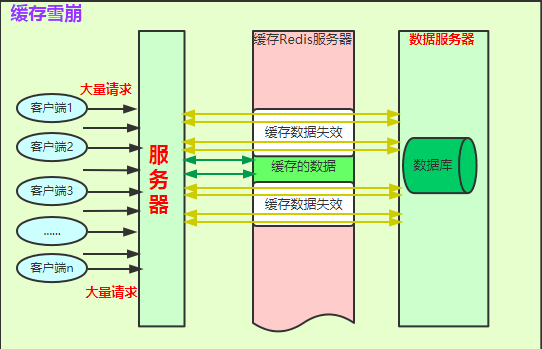
簡要說明:
快取Redis伺服器顏色說明:**綠色塊**代表有快取資料,**粉色塊**代表快取中沒有資料;**白色塊**代表大範圍失效的快取資料,**綠色箭頭**代表直接從快取中獲取資料;**黃色箭頭**代表穿過快取從資料庫中查資料。
流程大概如下:
1. 大量客戶端發起大量請求到伺服器;
2. 伺服器程式碼邏輯將先經過快取,如果**有快取資料(綠色部分)**,直接從快取中獲取資料資料返回;如果**快取過期(白色塊部分)**,請求就會直接打到資料庫伺服器**(如黃色箭頭)**。
3. 如果存在大量熱資料的請求,但熱資料又大範圍過期,最終資料庫將因為過大壓力崩掉,導致系統不可用。
##### 1.2 常用解決措施
- 快取預熱:在高峰期還沒到來時,提前將熱資料載入到快取中,避免高峰期來臨時資料庫壓力過大。
- 均勻設定過期時間:針對不同的熱點資料,將過期時間加上一個隨機值,讓過期時間不集中在一個點,從而減小很大部分資料庫壓力;
- 多級快取:除了使用Redis快取,還可以根據業務增加一些熱點資料的其他快取,比如記憶體快取,可以將各級的快取有效期分開,這種方式也能緩解資料庫的壓力;
- 限流、降級:如果壓力過大,避免把系統搞崩,可以增加一些限流手段,不管是中介軟體還是訊息佇列等,主要保證系統的可用。
- 加互斥鎖:目的就是加鎖獨佔操作,讓一個操作向快取中重新載入資料,讓請求操作等待,其實這樣的體驗不好,慎用。如果要用,要超級注意鎖的效能和穩定性。
- 對於快取層整體崩掉的情況:使用高可用架構,比如之前說到的主從複製、哨兵、叢集,根據需求進行對應架構,保證快取層不崩掉。
#### 3. 快取擊穿
##### 1.1 簡要描述
快取擊穿是指在超級熱點資料突然過期,導致針對超級熱點的資料請求在過期期間直接打到資料庫,這樣資料庫伺服器會因為某一超熱資料導致壓力過大而崩掉。
超熱資料:比如秒殺時的資料,某寶、某東、某多多這種平臺的資料如果在秒殺時間段失效,請求量足矣讓資料庫崩掉。
如圖:
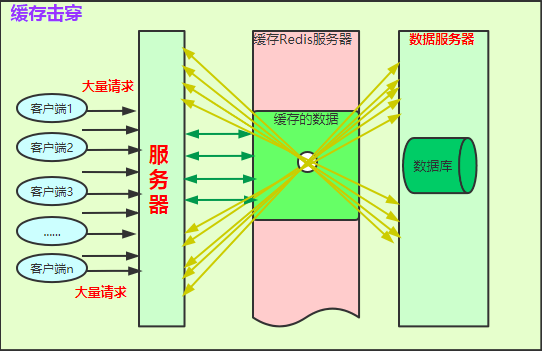
簡要說明:
快取Redis伺服器顏色說明:**綠色塊**代表有快取資料,**粉色塊**代表快取中沒有資料;**白色圈**代表超級熱點快取資料過期失效,**綠色箭頭**代表直接從快取中獲取資料;**黃色箭頭**代表穿過快取從資料庫中查資料。
流程大概如下:
1. 大量客戶端發起大量請求到伺服器;
2. 伺服器程式碼邏輯將先經過快取,如果**有快取資料(綠色部分)**,直接從快取中獲取資料資料返回;如果**超熱快取資料過期(白色圈部分)**,請求就會直接打到資料庫伺服器**(如黃色箭頭)**。
3. 超級熱點資料過期失效,如秒殺資料,如果在秒殺時段失效,最終資料庫將因為過大壓力崩掉,導致系統不可用。
注:這個只是針對超熱點資料,而不是大範圍資料。
##### 1.2 常用解決措施
- 熱點資料不過期:像這種超熱資料就設定永不過期。避免過期失效讓資料庫壓力過大而崩。
- 加互斥鎖:目的就是加鎖,然後向快取中重新載入資料,讓請求等待,其實這樣的體驗不好,慎用。如果要用,要超級注意鎖的效能和穩定性。
### 總結
快取穿透、快取雪崩、快取擊穿不管是哪個問題,其主要原因還是在快取層沒有命中,將請求直接打到資料庫啦,最終導致資料庫壓力過大,系統不可用。小夥伴根據系統需要進行問題處理,沒有完美的解決方案,但總會有一種適合需求的方案,解決業務問題才是真正目的。
今天沒有上程式碼,相信小夥伴都能根據解決措施寫出對應的程式碼,分散式鎖可能稍微有點難搞,下次抽時間給大家安排上。
關於Redis系列,下篇說說Lua指令碼就算初步完成啦,剩下的就是實戰的總結啦,在專案的使用過程中,如果有好的方案和棘手的問題都會和小夥伴分享。接下來資料庫優化系列即將開啟,主要針對MySql。
這篇文章特意安排在元宵釋出,熬夜到兩點,就是為了祝小夥伴元宵節快樂。
一個被程式搞醜的帥小夥,關注"Code綜藝圈",跟我一起學~~~