
2.5w字 + 36 張圖爆肝作業系統面試題,太牛逼了!
阿新 • • 發佈:2021-03-01
歡迎各位大佬訪問我的 github ,跪求 star
[bestJavaer](https://github.com/crisxuan/bestJavaer)
大家好,我是 cxuan,我之前彙總了一下關於作業系統的面試題,最近又重新翻閱了一下發現不是很全,現在也到了面試季了,所以我又花了一週的時間修訂整理了一下這份面試題,這份面試題可以吊打市面上所有的作業系統面試題了,不是我說,是因為我係統查過,如果有不相信的大佬,歡迎狠狠的打我臉。
這份面試題有 43 道題,囊括了校招面試和社招面試,看完這一篇文章,保準你能和麵試官侃侃而談,增加進入大廠的機率!
話不多說,下面我們直接進入面試題。
## 作業系統簡介篇
### 解釋一下什麼是作業系統
**作業系統是管理硬體和軟體的一種應用程式**。作業系統是執行在計算機上最重要的一種`軟體`,它管理計算機的資源和程序以及所有的硬體和軟體。它為計算機硬體和軟體提供了一種中間層,使應用軟體和硬體進行分離,讓我們無需關注硬體的實現,把關注點更多放在軟體應用上。
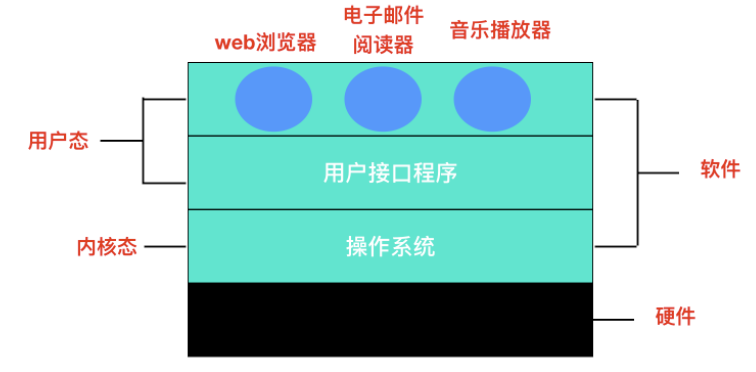
通常情況下,計算機上會執行著許多應用程式,它們都需要對記憶體和 CPU 進行互動,作業系統的目的就是為了保證這些訪問和互動能夠準確無誤的進行。
### 作業系統的主要功能
一般來說,現代作業系統主要提供下面幾種功能
* `程序管理`: 程序管理的主要作用就是任務排程,在單核處理器下,作業系統會為每個程序分配一個任務,程序管理的工作十分簡單;而在多核處理器下,作業系統除了要為程序分配任務外,還要解決處理器的排程、分配和回收等問題
* `記憶體管理`:記憶體管理主要是作業系統負責管理記憶體的分配、回收,在程序需要時分配記憶體以及在程序完成時回收記憶體,協調記憶體資源,通過合理的頁面置換演算法進行頁面的換入換出
* `裝置管理`:根據確定的裝置分配原則對裝置進行分配,使裝置與主機能夠並行工作,為使用者提供良好的裝置使用介面。
* `檔案管理`:有效地管理檔案的儲存空間,合理地組織和管理檔案系統,為檔案訪問和檔案保護提供更有效的方法及手段。
* `提供使用者介面`:作業系統提供了訪問應用程式和硬體的介面,使使用者能夠通過應用程式發起系統呼叫從而操縱硬體,實現想要的功能。
### 軟體訪問硬體的幾種方式
軟體訪問硬體其實就是一種 IO 操作,軟體訪問硬體的方式,也就是 I/O 操作的方式有哪些。
硬體在 I/O 上大致分為**並行和序列**,同時也對應序列介面和並行介面。
隨著計算機技術的發展,I/O 控制方式也在不斷髮展。選擇和衡量 I/O 控制方式有如下三條原則
>(1) 資料傳送速度足夠快,能滿足使用者的需求但又不丟失資料;
>
>(2) 系統開銷小,所需的處理控制程式少;
>
>(3) 能充分發揮硬體資源的能力,使 I/O 裝置儘可能忙,而 CPU 等待時間儘可能少。
根據以上控制原則,I/O 操作可以分為四類
* `直接訪問`:直接訪問由使用者程序直接控制主存或 CPU 和外圍裝置之間的資訊傳送。直接程式控制方式又稱為忙/等待方式。
* `中斷驅動`:為了減少程式直接控制方式下 CPU 的等待時間以及提高系統的並行程度,系統引入了中斷機制。中斷機制引入後,外圍裝置僅當操作正常結束或異常結束時才向 CPU 發出中斷請求。在 I/O 裝置輸入每個資料的過程中,由於無需 CPU 的干預,一定程度上實現了 CPU 與 I/O 裝置的並行工作。
上述兩種方法的特點都是以 `CPU` 為中心,資料傳送通過一段程式來實現,軟體的傳送手段限制了資料傳送的速度。接下來介紹的這兩種 I/O 控制方式採用硬體的方法來顯示 I/O 的控制
* `DMA 直接記憶體訪問`:為了進一步減少 CPU 對 I/O 操作的干預,防止因並行操作裝置過多使 CPU 來不及處理或因速度不匹配而造成的資料丟失現象,引入了 DMA 控制方式。
* `通道控制方式`:通道,獨立於 CPU 的專門負責輸入輸出控制的處理機,它控制裝置與記憶體直接進行資料交換。有自己的通道指令,這些指令由 CPU 啟動,並在操作結束時向 CPU 發出中斷訊號。
### 解釋一下作業系統的主要目的是什麼
作業系統是一種軟體,它的主要目的有三種
* 管理計算機資源,這些資源包括 CPU、記憶體、磁碟驅動器、印表機等。
* 提供一種圖形介面,就像我們前面描述的那樣,它提供了使用者和計算機之間的橋樑。
* 為其他軟體提供服務,作業系統與軟體進行互動,以便為其分配執行所需的任何必要資源。
### 作業系統的種類有哪些
作業系統通常預裝在你購買計算機之前。大部分使用者都會使用預設的作業系統,但是你也可以升級甚至更改作業系統。但是一般常見的作業系統只有三種:**Windows、macOS 和 Linux**。
### 為什麼 Linux 系統下的應用程式不能直接在 Windows 下執行
這是一個老生常談的問題了,在這裡給出具體的回答。
其中一點是因為 Linux 系統和 Windows 系統的格式不同,**格式就是協議**,就是在固定位置有意義的資料。Linux 下的可執行程式檔案格式是 `elf`,可以使用 `readelf` 命令檢視 elf 檔案頭。
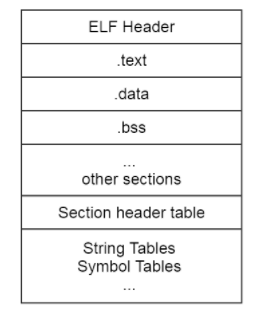
而 Windows 下的可執行程式是 `PE` 格式,它是一種可移植的可執行檔案。
還有一點是因為 Linux 系統和 Windows 系統的 `API` 不同,這個 API 指的就是作業系統的 API,Linux 中的 API 被稱為`系統呼叫`,是通過 `int 0x80` 這個軟中斷實現的。而 Windows 中的 API 是放在動態連結庫檔案中的,也就是 Windows 開發人員所說的 `DLL` ,這是一個庫,裡面包含程式碼和資料。Linux 中的可執行程式獲得系統資源的方法和 Windows 不一樣,所以顯然是不能在 Windows 中執行的。
### 作業系統結構
#### 單體系統
在大多數系統中,整個系統在核心態以單一程式的方式執行。整個作業系統是以程式集合來編寫的,連結在一塊形成一個大的二進位制可執行程式,這種系統稱為單體系統。
在單體系統中構造實際目標程式時,會首先編譯所有單個過程(或包含這些過程的檔案),然後使用系統連結器將它們全部繫結到一個可執行檔案中
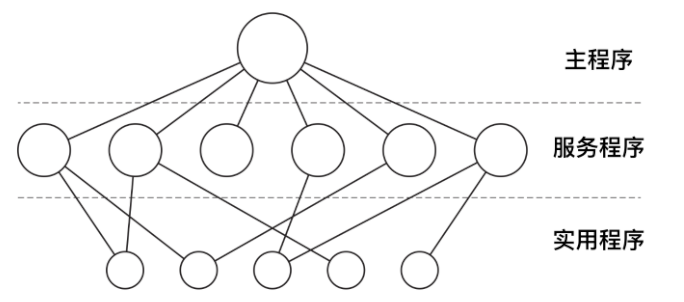
在單體系統中,對於每個系統呼叫都會有一個服務程式來保障和執行。需要一組實用程式來彌補服務程式需要的功能,例如從使用者程式中獲取資料。可將各種過程劃分為一個三層模型
除了在計算機初啟動時所裝載的核心作業系統外,許多作業系統還支援額外的擴充套件。比如 I/O 裝置驅動和檔案系統。這些部件可以按需裝載。在 UNIX 中把它們叫做 `共享庫(shared library)`,在 Windows 中則被稱為 `動態連結庫(Dynamic Link Library,DLL)`。他們的副檔名為 `.dll`,在 `C:\Windows\system32` 目錄下存在 1000 多個 DLL 檔案,所以不要輕易刪除 C 盤檔案,否則可能就炸了哦。
#### 分層系統
分層系統使用層來分隔不同的功能單元。每一層只與該層的上層和下層通訊。每一層都使用下面的層來執行其功能。層之間的通訊通過預定義的固定介面通訊。
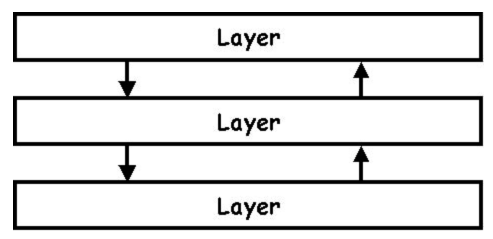
#### 微核心
為了實現高可靠性,將作業系統劃分成小的、層級之間能夠更好定義的模組是很有必要的,只有一個模組 --- 微核心 --- 執行在核心態,其餘模組可以作為普通使用者程序執行。由於把每個裝置驅動和檔案系統分別作為普通使用者程序,這些模組中的錯誤雖然會使這些模組崩潰,但是不會使整個系統宕機。
`MINIX 3` 是微核心的代表作,它的具體結構如下
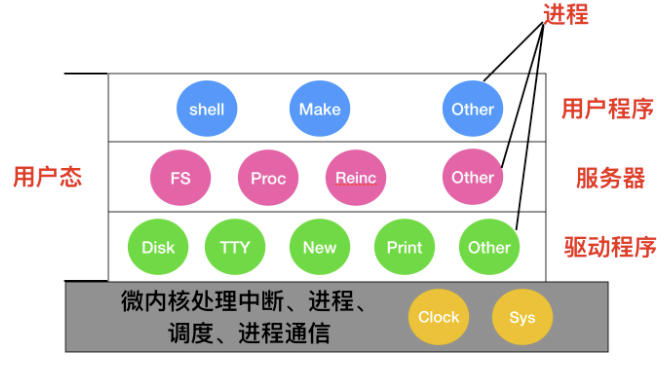
在核心的外部,系統的構造有三層,它們都在使用者態下執行,最底層是裝置驅動器。由於它們都在使用者態下執行,所以不能物理的訪問 I/O 埠空間,也不能直接發出 I/O 命令。相反,為了能夠對 I/O 裝置程式設計,驅動器構建一個結構,指明哪個引數值寫到哪個 I/O 埠,並聲稱一個核心呼叫,這樣就完成了一次呼叫過程。
#### 客戶-伺服器模式
微核心思想的策略是把程序劃分為兩類:`伺服器`,每個伺服器用來提供服務;`客戶端`,使用這些服務。這個模式就是所謂的 `客戶-伺服器`模式。
客戶-伺服器模式會有兩種載體,一種情況是一臺計算機既是客戶又是伺服器,在這種方式下,作業系統會有某種優化;但是普遍情況下是客戶端和伺服器在不同的機器上,它們通過區域網或廣域網連線。
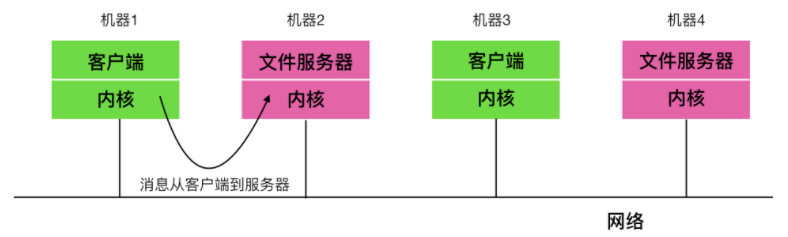
客戶通過傳送訊息與伺服器通訊,客戶端並不需要知道這些訊息是在本地機器上處理,還是通過網路被送到遠端機器上處理。對於客戶端而言,這兩種情形是一樣的:都是傳送請求並得到迴應。
### 為什麼稱為陷入核心
如果把軟體結構進行分層說明的話,應該是這個樣子的,最外層是應用程式,裡面是作業系統核心。
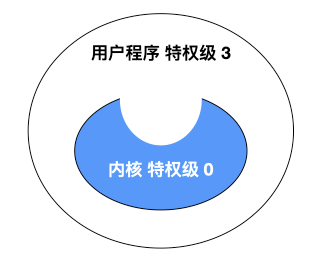
應用程式處於特權級 3,作業系統核心處於特權級 0 。如果使用者程式想要訪問作業系統資源時,會發起系統呼叫,陷入核心,這樣 CPU 就進入了核心態,執行核心程式碼。至於為什麼是陷入,我們看圖,核心是一個凹陷的構造,有陷下去的感覺,所以稱為陷入。
### 什麼是使用者態和核心態
使用者態和核心態是作業系統的兩種執行狀態。
* `核心態`:處於核心態的 CPU 可以訪問任意的資料,包括外圍裝置,比如網絡卡、硬碟等,處於核心態的 CPU 可以從一個程式切換到另外一個程式,並且佔用 CPU 不會發生搶佔情況,一般處於特權級 0 的狀態我們稱之為核心態。
* `使用者態`:處於使用者態的 CPU 只能受限的訪問記憶體,並且不允許訪問外圍裝置,使用者態下的 CPU 不允許獨佔,也就是說 CPU 能夠被其他程式獲取。
>那麼為什麼要有使用者態和核心態呢?
這個主要是訪問能力的限制的考量,計算機中有一些比較危險的操作,比如設定時鐘、記憶體清理,這些都需要在核心態下完成,如果隨意進行這些操作,那你的系統得崩潰多少次。
### 使用者態和核心態是如何切換的?
所有的使用者程序都是執行在使用者態的,但是我們上面也說了,使用者程式的訪問能力有限,一些比較重要的比如從硬碟讀取資料,從鍵盤獲取資料的操作則是核心態才能做的事情,而這些資料卻又對使用者程式來說非常重要。所以就涉及到兩種模式下的轉換,即**使用者態 -> 核心態 -> 使用者態**,而唯一能夠做這些操作的只有 `系統呼叫`,而能夠執行系統呼叫的就只有 `作業系統`。
一般使用者態 -> 核心態的轉換我們都稱之為 trap 進核心,也被稱之為 `陷阱指令(trap instruction)`。
他們的工作流程如下:
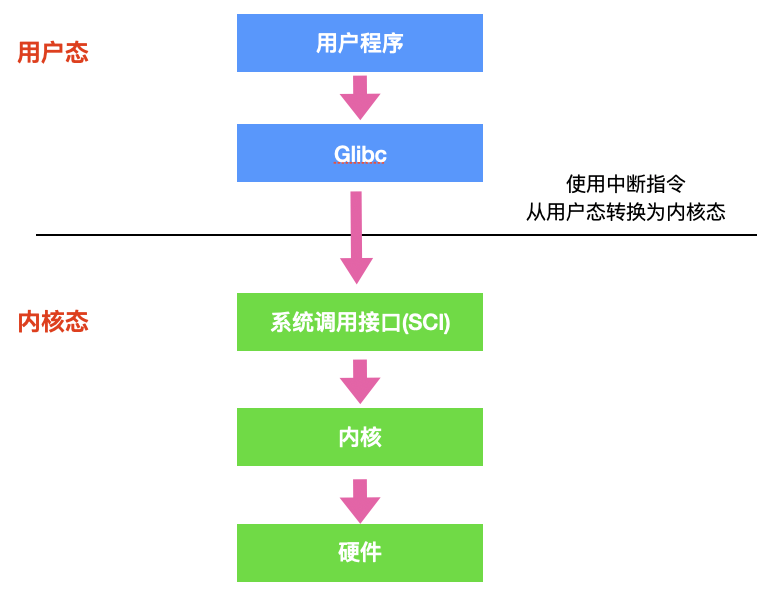
* 首先使用者程式會呼叫 `glibc` 庫,glibc 是一個標準庫,同時也是一套核心庫,庫中定義了很多關鍵 API。
* glibc 庫知道針對不同體系結構呼叫`系統呼叫`的正確方法,它會根據體系結構應用程式的二進位制介面設定使用者程序傳遞的引數,來準備系統呼叫。
* 然後,glibc 庫呼叫`軟體中斷指令(SWI)` ,這個指令通過更新 `CPSR` 暫存器將模式改為超級使用者模式,然後跳轉到地址 `0x08` 處。
* 到目前為止,整個過程仍處於使用者態下,在執行 SWI 指令後,允許程序執行核心程式碼,MMU 現在允許核心虛擬記憶體訪問
* 從地址 0x08 開始,程序執行載入並跳轉到中斷處理程式,這個程式就是 ARM 中的 `vector_swi()`。
* 在 vector_swi() 處,從 SWI 指令中提取系統呼叫號 SCNO,然後使用 SCNO 作為系統呼叫表 `sys_call_table` 的索引,調轉到系統呼叫函式。
* 執行系統呼叫完成後,將還原使用者模式暫存器,然後再以使用者模式執行。
### 什麼是核心
**在計算機中,核心是一個計算機程式,它是作業系統的核心,可以控制作業系統中所有的內容**。核心通常是在 boot loader 裝載程式之前載入的第一個程式。
這裡還需要了解一下什麼是 `boot loader`。
>boot loader 又被稱為引導載入程式,能夠將計算機的作業系統放入記憶體中。在電源通電或者計算機重啟時,BIOS 會執行一些初始測試,然後將控制權轉移到引導載入程式所在的`主引導記錄(MBR)` 。
### 什麼是實時系統
實時作業系統對時間做出了嚴格的要求,實時作業系統分為兩種:**硬實時和軟實時**
`硬實時作業系統`規定某個動作必須在規定的時刻內完成或發生,比如汽車生產車間,焊接機器必須在某一時刻內完成焊接,焊接的太早或者太晚都會對汽車造成永久性傷害。
`軟實時作業系統`雖然不希望偶爾違反最終的時限要求,但是仍然可以接受。並且不會引起任何永久性傷害。比如數字音訊、多媒體、手機都是屬於軟實時作業系統。
你可以簡單理解硬實時和軟實時的兩個指標:**是否在時刻內必須完成以及是否造成嚴重損害**。
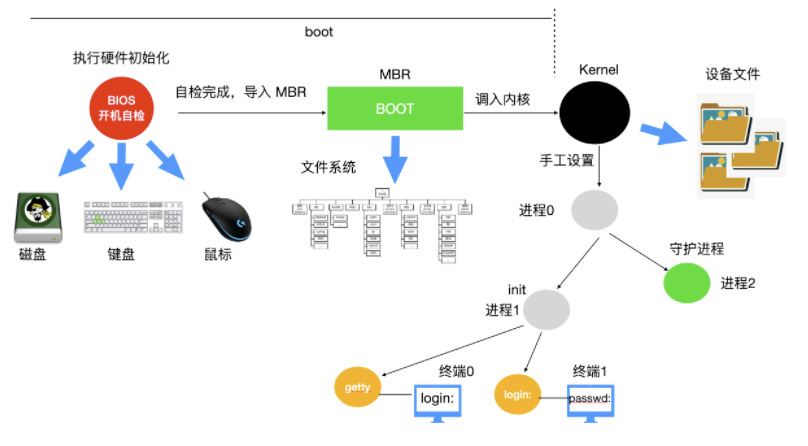
### Linux 作業系統的啟動過程
當計算機電源通電後,`BIOS`會進行`開機自檢(Power-On-Self-Test, POST)`,對硬體進行檢測和初始化。因為作業系統的啟動會使用到磁碟、螢幕、鍵盤、滑鼠等裝置。下一步,磁碟中的第一個分割槽,也被稱為 `MBR(Master Boot Record)` 主引導記錄,被讀入到一個固定的記憶體區域並執行。這個分割槽中有一個非常小的,只有 512 位元組的程式。程式從磁碟中調入 boot 獨立程式,boot 程式將自身複製到高位地址的記憶體從而為作業系統釋放低位地址的記憶體。
複製完成後,boot 程式讀取啟動裝置的根目錄。boot 程式要理解檔案系統和目錄格式。然後 boot 程式被調入核心,把控制權移交給核心。直到這裡,boot 完成了它的工作。系統核心開始執行。
核心啟動程式碼是使用`組合語言`完成的,主要包括建立核心堆疊、識別 CPU 型別、計算記憶體、禁用中斷、啟動記憶體管理單元等,然後呼叫 C 語言的 main 函式執行作業系統部分。
這部分也會做很多事情,首先會分配一個訊息緩衝區來存放調試出現的問題,除錯資訊會寫入緩衝區。如果調試出現錯誤,這些資訊可以通過診斷程式調出來。
然後作業系統會進行自動配置,檢測裝置,載入配置檔案,被檢測裝置如果做出響應,就會被新增到已連結的裝置表中,如果沒有相應,就歸為未連線直接忽略。
配置完所有硬體後,接下來要做的就是仔細手工處理程序0,設定其堆疊,然後執行它,執行初始化、配置時鐘、掛載檔案系統。建立 `init 程序(程序 1 )` 和 `守護程序(程序 2)`。
init 程序會檢測它的標誌以確定它是否為單使用者還是多使用者服務。在前一種情況中,它會呼叫 fork 函式建立一個 shell 程序,並且等待這個程序結束。後一種情況呼叫 fork 函式建立一個執行系統初始化的 shell 指令碼(即 /etc/rc)的程序,這個程序可以進行檔案系統一致性檢測、掛載檔案系統、開啟守護程序等。
然後 /etc/rc 這個程序會從 /etc/ttys 中讀取資料,/etc/ttys 列出了所有的終端和屬性。對於每一個啟用的終端,這個程序呼叫 fork 函式建立一個自身的副本,進行內部處理並執行一個名為 `getty` 的程式。
getty 程式會在終端上輸入
```shell
login:
```
等待使用者輸入使用者名稱,在輸入使用者名稱後,getty 程式結束,登陸程式 `/bin/login` 開始執行。login 程式需要輸入密碼,並與儲存在 `/etc/passwd` 中的密碼進行對比,如果輸入正確,login 程式以使用者 shell 程式替換自身,等待第一個命令。如果不正確,login 程式要求輸入另一個使用者名稱。
整個系統啟動過程如下
## 程序和執行緒篇
### 多處理系統的優勢
隨著處理器的不斷增加,我們的計算機系統由單機系統變為了多處理系統,多處理系統的吞吐量比較高,多處理系統擁有多個並行的處理器,這些處理器共享時鐘、記憶體、匯流排、外圍裝置等。
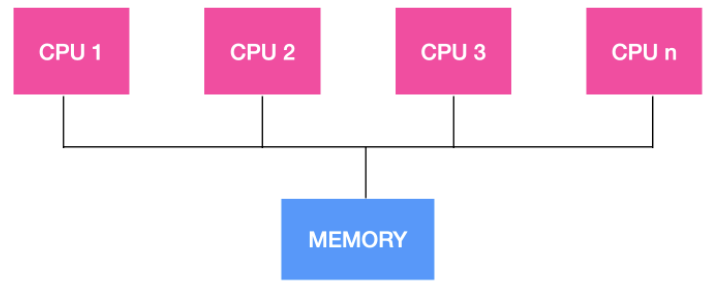
多處理系統由於可以共享資源,因此可以開源節流,省錢。整個系統的可靠性也隨之提高。
### 什麼是程序和程序表
`程序`就是正在執行程式的例項,比如說 Web 程式就是一個程序,shell 也是一個程序,文章編輯器 typora 也是一個程序。
作業系統負責管理所有正在執行的程序,作業系統會為每個程序分配特定的時間來佔用 CPU,作業系統還會為每個程序分配特定的資源。
作業系統為了跟蹤每個程序的活動狀態,維護了一個`程序表`。在程序表的內部,列出了每個程序的狀態以及每個程序使用的資源等。
### 什麼是執行緒,執行緒和程序的區別
這又是一道老生常談的問題了,從作業系統的角度來回答一下吧。
我們上面說到程序是正在執行的程式的例項,而執行緒其實就是程序中的單條流向,因為執行緒具有程序中的某些屬性,所以執行緒又被稱為輕量級的程序。瀏覽器如果是一個程序的話,那麼瀏覽器下面的每個 tab 頁可以看作是一個個的執行緒。
下面是執行緒和程序持有資源的區別

執行緒不像程序那樣具有很強的獨立性,執行緒之間會共享資料
建立執行緒的開銷要比程序小很多,因為建立執行緒僅僅需要`堆疊指標`和`程式計數器`就可以了,而建立程序需要作業系統分配新的地址空間,資料資源等,這個開銷比較大。
### 什麼是上下文切換
對於單核單執行緒 CPU 而言,在某一時刻只能執行一條 CPU 指令。上下文切換 (Context Switch) 是一種 **將 CPU 資源從一個程序分配給另一個程序的機制**。從使用者角度看,計算機能夠並行執行多個程序,這恰恰是作業系統通過快速上下文切換造成的結果。在切換的過程中,作業系統需要先儲存當前程序的狀態 (包括記憶體空間的指標,當前執行完的指令等等),再讀入下一個程序的狀態,然後執行此程序。
### 使用多執行緒的好處是什麼
多執行緒是程式設計師不得不知的基本素養之一,所以,下面我們給出一些多執行緒程式設計的好處
* 能夠提高對使用者的響應順序
* 在流程中的資源共享
* 比較經濟適用
* 能夠對多執行緒架構有深入的理解
### 程序終止的方式
#### 程序的終止
程序在建立之後,它就開始執行並做完成任務。然而,沒有什麼事兒是永不停歇的,包括程序也一樣。程序早晚會發生終止,但是通常是由於以下情況觸發的
* `正常退出(自願的)`
* `錯誤退出(自願的)`
* `嚴重錯誤(非自願的)`
* `被其他程序殺死(非自願的)`
#### 正常退出
多數程序是由於完成了工作而終止。當編譯器完成了所給定程式的編譯之後,編譯器會執行一個系統呼叫告訴作業系統它完成了工作。這個呼叫在 UNIX 中是 `exit` ,在 Windows 中是 `ExitProcess`。面向螢幕中的軟體也支援自願終止操作。字處理軟體、Internet 瀏覽器和類似的程式中總有一個供使用者點選的圖示或選單項,用來通知程序刪除它鎖開啟的任何臨時檔案,然後終止。
#### 錯誤退出
程序發生終止的第二個原因是發現嚴重錯誤,例如,如果使用者執行如下命令
```c
cc foo.c
```
為了能夠編譯 foo.c 但是該檔案不存在,於是編譯器就會發出聲明並退出。在給出了錯誤引數時,面向螢幕的互動式程序通常並不會直接退出,因為這從使用者的角度來說並不合理,使用者需要知道發生了什麼並想要進行重試,所以這時候應用程式通常會彈出一個對話方塊告知使用者發生了系統錯誤,是需要重試還是退出。
#### 嚴重錯誤
程序終止的第三個原因是由程序引起的錯誤,通常是由於程式中的錯誤所導致的。例如,執行了一條非法指令,引用不存在的記憶體,或者除數是 0 等。在有些系統比如 UNIX 中,程序可以通知作業系統,它希望自行處理某種型別的錯誤,在這類錯誤中,程序會收到訊號(中斷),而不是在這類錯誤出現時直接終止程序。
#### 被其他程序殺死
第四個終止程序的原因是,某個程序執行系統呼叫告訴作業系統殺死某個程序。在 UNIX 中,這個系統呼叫是 kill。在 Win32 中對應的函式是 `TerminateProcess`(注意不是系統呼叫)。
### 程序間的通訊方式
程序間的通訊方式比較多,首先你需要理解下面這幾個概念
* 競態條件:即兩個或多個執行緒同時對一共享資料進行修改,從而影響程式執行的正確性時,這種就被稱為`競態條件(race condition)`。
* 臨界區:不僅`共享資源`會造成競態條件,事實上共享檔案、共享記憶體也會造成競態條件、那麼該如何避免呢?或許一句話可以概括說明:**禁止一個或多個程序在同一時刻對共享資源(包括共享記憶體、共享檔案等)進行讀寫**。換句話說,我們需要一種 `互斥(mutual exclusion)` 條件,這也就是說,如果一個程序在某種方式下使用共享變數和檔案的話,除該程序之外的其他程序就禁止做這種事(訪問統一資源)。
一個好的解決方案,應該包含下面四種條件
1. 任何時候兩個程序不能同時處於臨界區
2. 不應對 CPU 的速度和數量做任何假設
3. 位於臨界區外的程序不得阻塞其他程序
4. 不能使任何程序無限等待進入臨界區
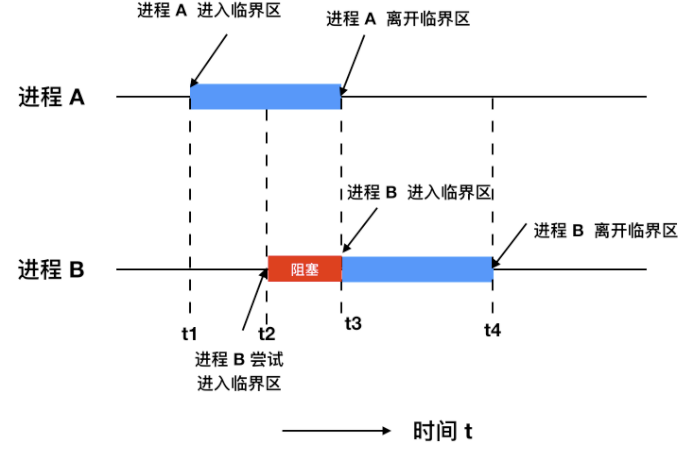
* 忙等互斥:當一個程序在對資源進行修改時,其他程序必須進行等待,程序之間要具有互斥性,我們討論的解決方案其實都是基於忙等互斥提出的。
程序間的通訊用專業一點的術語來表示就是 `Inter Process Communication,IPC`,它主要有下面 7。種通訊方式
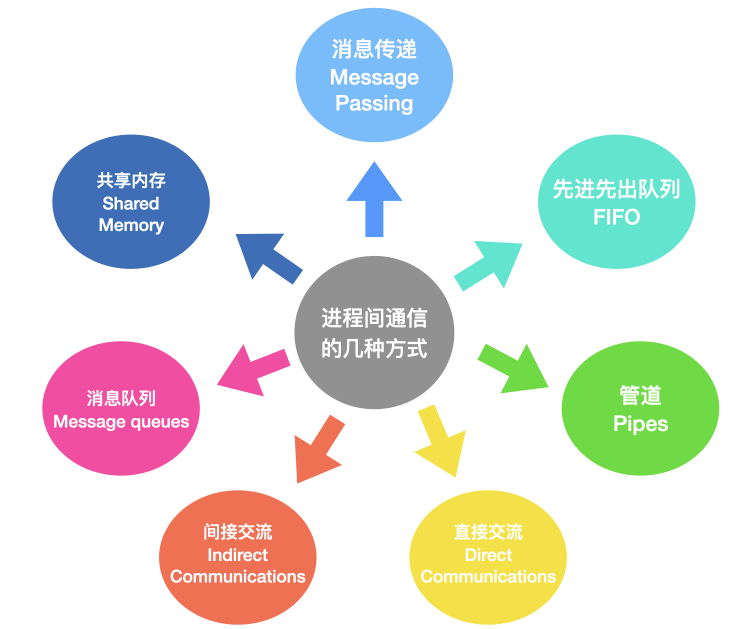
* `訊息傳遞`:訊息傳遞是程序間實現通訊和同步等待的機制,使用訊息傳遞,程序間的交流不需要共享變數,直接就可以進行通訊;訊息傳遞分為傳送方和接收方
* `先進先出佇列`:先進先出佇列指的是兩個不相關聯程序間的通訊,兩個程序之間可以彼此相互程序通訊,這是一種全雙工通訊方式
* `管道`:管道用於兩個相關程序之間的通訊,這是一種半雙工的通訊方式,如果需要全雙工,需要另外一個管道。
* `直接通訊`:在這種程序通訊的方式中,程序與程序之間只存在一條連結,程序間要明確通訊雙方的命名。
* `間接通訊`:間接通訊是通訊雙方不會直接建立連線,而是找到一箇中介者,這個中介者可能是個物件等等,程序可以在其中放置訊息,並且可以從中刪除訊息,以此達到程序間通訊的目的。
* `訊息佇列`:訊息佇列是核心中儲存訊息的連結串列,它由訊息佇列識別符號進行標識,這種方式能夠在不同的程序之間提供全雙工的通訊連線。
* `共享記憶體`:共享記憶體是使用所有程序之間的記憶體來建立連線,這種型別需要同步程序訪問來相互保護。
### 程序間狀態模型
#### 程序的三態模型
當一個程序開始執行時,它可能會經歷下面這幾種狀態
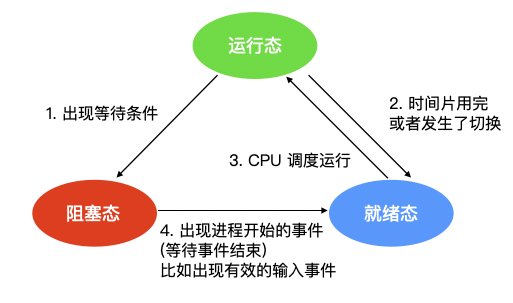
圖中會涉及三種狀態
1. `執行態`:執行態指的就是程序實際佔用 CPU 時間片執行時
2. `就緒態`:就緒態指的是可執行,但因為其他程序正在執行而處於就緒狀態
3. `阻塞態`:阻塞態又被稱為睡眠態,它指的是程序不具備執行條件,正在等待被 CPU 排程。
邏輯上來說,執行態和就緒態是很相似的。這兩種情況下都表示程序`可執行`,但是第二種情況沒有獲得 CPU 時間分片。第三種狀態與前兩種狀態不同的原因是這個程序不能執行,CPU 空閒時也不能執行。
三種狀態會涉及四種狀態間的切換,在作業系統發現程序不能繼續執行時會發生`狀態1`的輪轉,在某些系統中程序執行系統呼叫,例如 `pause`,來獲取一個阻塞的狀態。在其他系統中包括 UNIX,當程序從管道或特殊檔案(例如終端)中讀取沒有可用的輸入時,該程序會被自動終止。
轉換 2 和轉換 3 都是由程序排程程式(作業系統的一部分)引起的,程序本身不知道排程程式的存在。轉換 2 的出現說明程序排程器認定當前程序已經運行了足夠長的時間,是時候讓其他程序執行 CPU 時間片了。當所有其他程序都執行過後,這時候該是讓第一個程序重新獲得 CPU 時間片的時候了,就會發生轉換 3。
>**程式排程指的是,決定哪個程序優先被執行和執行多久,這是很重要的一點**。已經設計出許多演算法來嘗試平衡系統整體效率與各個流程之間的競爭需求。
當程序等待的一個外部事件發生時(如從外部輸入一些資料後),則發生轉換 4。如果此時沒有其他程序在執行,則立刻觸發轉換 3,該程序便開始執行,否則該程序會處於就緒階段,等待 CPU 空閒後再輪到它執行。
#### 程序的五態模型
在三態模型的基礎上,增加了兩個狀態,即 `新建` 和 `終止` 狀態。
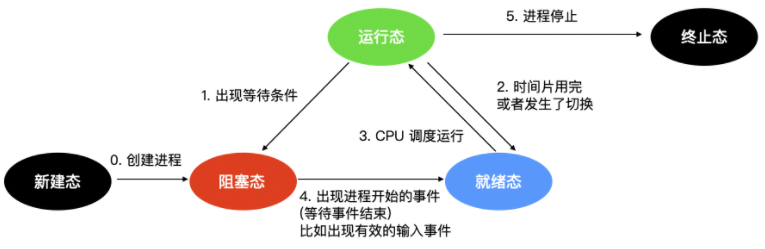
* 新建態:程序的新建態就是程序剛創建出來的時候
>建立程序需要兩個步驟:即為新程序分配所需要的資源和空間,設定程序為就緒態,並等待排程執行。
* 終止態:程序的終止態就是指程序執行完畢,到達結束點,或者因為錯誤而不得不中止程序。
>終止一個程序需要兩個步驟:
>
>1. 先等待作業系統或相關的程序進行善後處理。
>
>2. 然後回收佔用的資源並被系統刪除。
### 排程演算法都有哪些
排程演算法分為三大類:批處理中的排程、互動系統中的排程、實時系統中的排程
#### 批處理中的排程
#### 先來先服務
很像是先到先得。。。可能最簡單的非搶佔式排程演算法的設計就是 `先來先服務(first-come,first-serverd)`。使用此演算法,將按照請求順序為程序分配 CPU。最基本的,會有一個就緒程序的等待佇列。當第一個任務從外部進入系統時,將會立即啟動並允許執行任意長的時間。它不會因為執行時間太長而中斷。當其他作業進入時,它們排到就緒佇列尾部。當正在執行的程序阻塞,處於等待佇列的第一個程序就開始執行。當一個阻塞的程序重新處於就緒態時,它會像一個新到達的任務,會排在佇列的末尾,即排在所有程序最後。
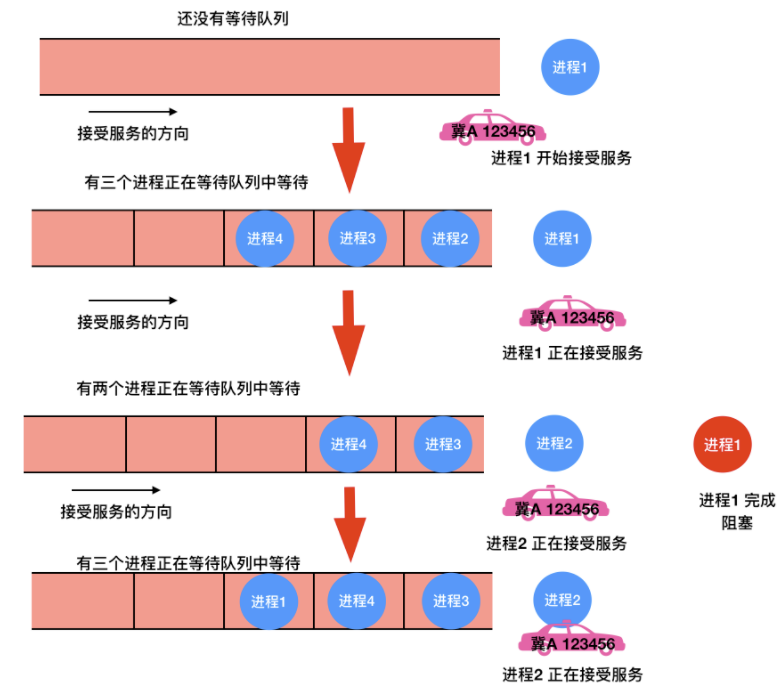
這個演算法的強大之處在於易於理解和程式設計,在這個演算法中,一個單鏈表記錄了所有就緒程序。要選取一個程序執行,只要從該佇列的頭部移走一個程序即可;要新增一個新的作業或者阻塞一個程序,只要把這個作業或程序附加在佇列的末尾即可。這是很簡單的一種實現。
不過,先來先服務也是有缺點的,那就是沒有優先順序的關係,試想一下,如果有 100 個 I/O 程序正在排隊,第 101 個是一個 CPU 密集型程序,那豈不是需要等 100 個 I/O 程序執行完畢才會等到一個 CPU 密集型程序執行,這在實際情況下根本不可能,所以需要優先順序或者搶佔式程序的出現來優先選擇重要的程序執行。
#### 最短作業優先
批處理中,第二種排程演算法是 `最短作業優先(Shortest Job First)`,我們假設執行時間已知。例如,一家保險公司,因為每天要做類似的工作,所以人們可以相當精確地預測處理 1000 個索賠的一批作業需要多長時間。當輸入佇列中有若干個同等重要的作業被啟動時,排程程式應使用最短優先作業演算法
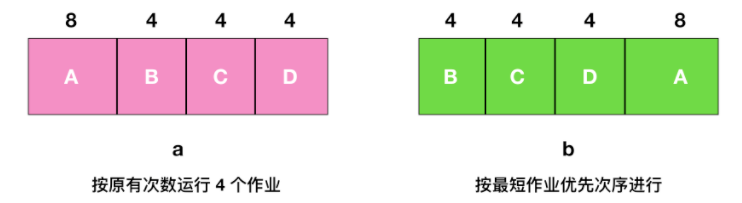
如上圖 a 所示,這裡有 4 個作業 A、B、C、D ,執行時間分別為 8、4、4、4 分鐘。若按圖中的次序執行,則 A 的週轉時間為 8 分鐘,B 為 12 分鐘,C 為 16 分鐘,D 為 20 分鐘,平均時間內為 14 分鐘。
現在考慮使用最短作業優先演算法執行 4 個作業,如上圖 b 所示,目前的週轉時間分別為 4、8、12、20,平均為 11 分鐘,可以證明最短作業優先是最優的。考慮有 4 個作業的情況,其執行時間分別為 a、b、c、d。第一個作業在時間 a 結束,第二個在時間 a + b 結束,以此類推。平均週轉時間為 (4a + 3b + 2c + d) / 4 。顯然 a 對平均值的影響最大,所以 a 應該是最短優先作業,其次是 b,然後是 c ,最後是 d 它就只能影響自己的週轉時間了。
>需要注意的是,在所有的程序都可以執行的情況下,最短作業優先的演算法才是最優的。
#### 最短剩餘時間優先
最短作業優先的搶佔式版本被稱作為 `最短剩餘時間優先(Shortest Remaining Time Next)` 演算法。使用這個演算法,排程程式總是選擇剩餘執行時間最短的那個程序執行。當一個新作業到達時,其整個時間同當前程序的剩餘時間做比較。如果新的程序比當前執行程序需要更少的時間,當前程序就被掛起,而執行新的程序。這種方式能夠使短期作業獲得良好的服務。
### 互動式系統中的排程
互動式系統中在個人計算機、伺服器和其他系統中都是很常用的,所以有必要來探討一下互動式排程
#### 輪詢排程
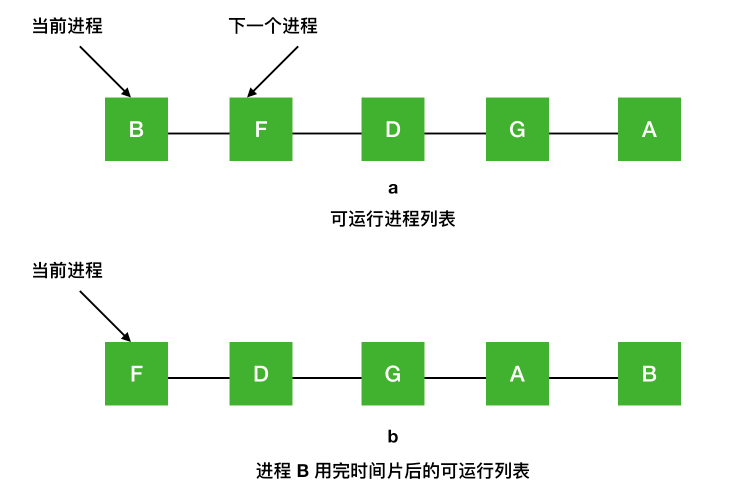
一種最古老、最簡單、最公平並且最廣泛使用的演算法就是 `輪詢演算法(round-robin)`。每個程序都會被分配一個時間段,稱為`時間片(quantum)`,在這個時間片內允許程序執行。如果時間片結束時程序還在執行的話,則搶佔一個 CPU 並將其分配給另一個程序。如果程序在時間片結束前阻塞或結束,則 CPU 立即進行切換。輪詢演算法比較容易實現。排程程式所做的就是維護一個可執行程序的列表,就像下圖中的 a,當一個程序用完時間片後就被移到佇列的末尾,就像下圖的 b。
#### 優先順序排程
事實情況是不是所有的程序都是優先順序相等的。例如,在一所大學中的等級制度,首先是院長,然後是教授、祕書、後勤人員,最後是學生。這種將外部情況考慮在內就實現了`優先順序排程(priority scheduling)`

它的基本思想很明確,每個程序都被賦予一個優先順序,優先順序高的程序優先執行。
但是也不意味著高優先順序的程序能夠永遠一直執行下去,排程程式會在每個時鐘中斷期間降低當前執行程序的優先順序。如果此操作導致其優先順序降低到下一個最高程序的優先順序以下,則會發生程序切換。或者,可以為每個程序分配允許執行的最大時間間隔。當時間間隔用完後,下一個高優先順序的程序會得到執行的機會。
#### 最短程序優先
對於批處理系統而言,由於最短作業優先常常伴隨著最短響應時間,一種方式是根據程序過去的行為進行推測,並執行估計執行時間最短的那一個。假設每個終端上每條命令的預估執行時間為 `T0`,現在假設測量到其下一次執行時間為 `T1`,可以用兩個值的加權來改進估計時間,即`aT0+ (1- 1)T1`。通過選擇 a 的值,可以決定是儘快忘掉老的執行時間,還是在一段長時間內始終記住它們。當 a = 1/2 時,可以得到下面這個序列
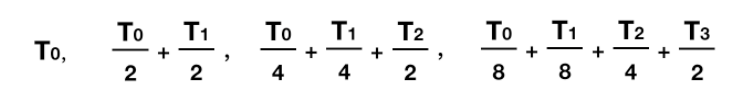
可以看到,在三輪過後,T0 在新的估計值中所佔比重下降至 1/8。
有時把這種通過當前測量值和先前估計值進行加權平均從而得到下一個估計值的技術稱作 `老化(aging)`。這種方法會使用很多預測值基於當前值的情況。
#### 彩票排程
有一種既可以給出預測結果而又有一種比較簡單的實現方式的演算法,就是 `彩票排程(lottery scheduling)`演算法。他的基本思想為程序提供各種系統資源的`彩票`。當做出一個排程決策的時候,就隨機抽出一張彩票,擁有彩票的程序將獲得資源。比如在 CPU 進行排程時,系統可以每秒持有 50 次抽獎,每個中獎程序會獲得額外執行時間的獎勵。
> 可以把彩票理解為 buff,這個 buff 有 15% 的機率能讓你產生 `速度之靴` 的效果。
#### 公平分享排程
如果使用者 1 啟動了 9 個程序,而使用者 2 啟動了一個程序,使用輪轉或相同優先順序排程演算法,那麼使用者 1 將得到 90 % 的 CPU 時間,而使用者 2 將之得到 10 % 的 CPU 時間。
為了阻止這種情況的出現,一些系統在排程前會把程序的擁有者考慮在內。在這種模型下,每個使用者都會分配一些CPU 時間,而排程程式會選擇程序並強制執行。因此如果兩個使用者每個都會有 50% 的 CPU 時間片保證,那麼無論一個使用者有多少個程序,都將獲得相同的 CPU 份額。
### 影響排程程式的指標是什麼
會有下面幾個因素決定排程程式的好壞
* CPU 使用率:
CPU 正在執行任務(即不處於空閒狀態)的時間百分比。
* 等待時間
這是程序輪流執行的時間,也就是程序切換的時間
* 吞吐量
單位時間內完成程序的數量
* 響應時間
這是從提交流程到獲得有用輸出所經過的時間。
* 週轉時間
從提交流程到完成流程所經過的時間。
### 什麼是 RR 排程演算法
`RR(round-robin)` 排程演算法主要針對分時系統,RR 的排程演算法會把時間片以相同的部分並迴圈的分配給每個程序,RR 排程演算法沒有優先順序的概念。這種演算法的實現比較簡單,而且每個執行緒都會佔有時間片,並不存線上程飢餓的問題。
## 記憶體管理篇
### 什麼是按需分頁
在作業系統中,程序是以頁為單位載入到記憶體中的,按需分頁是一種`虛擬記憶體`的管理方式。在使用請求分頁的系統中,只有在嘗試訪問頁面所在的磁碟並且該頁面尚未在記憶體中時,也就發生了`缺頁異常`,作業系統才會將磁碟頁面複製到記憶體中。
### 什麼是虛擬記憶體
`虛擬記憶體`是一種記憶體分配方案,是一項可以用來輔助記憶體分配的機制。我們知道,應用程式是按頁裝載進記憶體中的。但並不是所有的頁都會裝載到記憶體中,計算機中的硬體和軟體會將資料從 RAM 臨時傳輸到磁碟中來彌補記憶體的不足。如果沒有虛擬記憶體的話,一旦你將計算機記憶體填滿後,計算機會對你說

呃,不,**對不起,您無法再載入任何應用程式,請關閉另一個應用程式以載入新的應用程式**。對於虛擬記憶體,計算機可以執行操作是檢視記憶體中最近未使用過的區域,然後將其複製到硬碟上。虛擬記憶體通過複製技術實現了 **妹子,你快來看哥哥能裝這麼多程式** 的資本。複製是自動進行的,你無法感知到它的存在。
### 虛擬記憶體的實現方式
虛擬記憶體中,允許將一個作業分多次調入記憶體。釆用連續分配方式時,會使相當一部分記憶體空間都處於暫時或`永久`的空閒狀態,造成記憶體資源的嚴重浪費,而且也無法從邏輯上擴大記憶體容量。因此,虛擬記憶體的實需要建立在離散分配的記憶體管理方式的基礎上。虛擬記憶體的實現有以下三種方式:
- 請求分頁儲存管理。
- 請求分段儲存管理。
- 請求段頁式儲存管理。
不管哪種方式,都需要有一定的硬體支援。一般需要的支援有以下幾個方面:
- 一定容量的記憶體和外存。
- 頁表機制(或段表機制),作為主要的資料結構。
- 中斷機構,當用戶程式要訪問的部分尚未調入記憶體,則產生中斷。
- 地址變換機構,邏輯地址到實體地址的變換。
### 記憶體為什麼要分段
記憶體是隨機訪問裝置,對於記憶體來說,不需要從頭開始查詢,只需要直接給出地址即可。記憶體的分段是從 `8086 CPU` 開始的,8086 的 CPU 還是 16 位的暫存器寬,16 位的暫存器可以儲存的數字範圍是 2 的 16 次方,即 64 KB,8086 的 CPU 還沒有 `虛擬地址`,只有實體地址,也就是說,如果兩個相同的程式編譯出來的地址相同,那麼這兩個程式是無法同時執行的。為了解決這個問題,作業系統設計人員提出了讓 CPU 使用 `段基址 + 段內偏移` 的方式來訪問任意記憶體。這樣的好處是讓程式可以 `重定位`,**這也是記憶體為什麼要分段的第一個原因**。
>那麼什麼是重定位呢?
簡單來說就是將程式中的指令地址改為另一個地址,地址處儲存的內容還是原來的。
CPU 採用段基址 + 段內偏移地址的形式訪問記憶體,就需要提供專門的暫存器,這些專門的暫存器就是 **CS、DS、ES 等**,如果你對暫存器不熟悉,可以看我的這一篇文章。
[愛了愛了,這篇暫存器講的有點意思](https://mp.weixin.qq.com/s?__biz=MzI0ODk2NDIyMQ==&mid=2247486191&idx=1&sn=ae26d8c42dc4317659232345e576ebaa&chksm=e999fffddeee76eb05ba3bcda5e6fd9c6c170a77cab414ae23e7879d7c3e18104e006a2af4e2&token=620789124&lang=zh_CN#rd)
也就是說,程式中需要用到哪塊記憶體,就需要先載入合適的段到段基址暫存器中,再給出相對於該段基址的段偏移地址即可。CPU 中的地址加法器會將這兩個地址進行合併,從地址匯流排送入記憶體。
8086 的 CPU 有 20 根地址匯流排,最大的定址能力是 1MB,而段基址所在的暫存器寬度只有 16 位,最大為你 64 KB 的定址能力,64 KB 顯然不能滿足 1MB 的最大定址範圍,所以就要把記憶體分段,每個段的最大定址能力是 64KB,但是仍舊不能達到最大 1 MB 的定址能力,所以這時候就需要 `偏移地址`的輔助,偏移地址也存入暫存器,同樣為 64 KB 的定址能力,這麼一看還是不能滿足 1MB 的定址,所以 CPU 的設計者對地址單元動了手腳,將段基址左移 4 位,然後再和 16 位的段內偏移地址相加,就達到了 1MB 的定址能力。**所以記憶體分段的第二個目的就是能夠訪問到所有記憶體**。
### 實體地址、邏輯地址、有效地址、線性地址、虛擬地址的區別
實體地址就是記憶體中真正的地址,它就相當於是你家的門牌號,你家就肯定有這個門牌號,具有唯一性。**不管哪種地址,最終都會對映為實體地址**。
在`真實模式`下,段基址 + 段內偏移經過地址加法器的處理,經過地址匯流排傳輸,最終也會轉換為`實體地址`。
但是在`保護模式`下,段基址 + 段內偏移被稱為`線性地址`,不過此時的段基址不能稱為真正的地址,而是會被稱作為一個`選擇子`的東西,選擇子就是個索引,相當於陣列的下標,通過這個索引能夠在 GDT 中找到相應的段描述符,段描述符記錄了**段的起始、段的大小**等資訊,這樣便得到了基地址。如果此時沒有開啟記憶體分頁功能,那麼這個線性地址可以直接當做實體地址來使用,直接訪問記憶體。如果開啟了分頁功能,那麼這個線性地址又多了一個名字,這個名字就是`虛擬地址`。
不論在真實模式還是保護模式下,段內偏移地址都叫做`有效地址`。有效抵制也是邏輯地址。
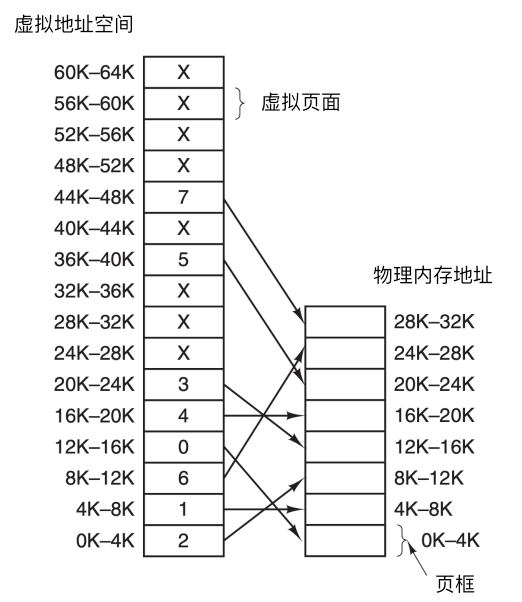
線性地址可以看作是`虛擬地址`,虛擬地址不是真正的實體地址,但是虛擬地址會最終被對映為實體地址。下面是虛擬地址 -> 實體地址的對映。
### 空閒記憶體管理的方式
作業系統在動態分配記憶體時(malloc,new),需要對空間記憶體進行管理。一般採用了兩種方式:點陣圖和空閒連結串列。
#### 使用點陣圖進行管理
使用點陣圖方法時,記憶體可能被劃分為小到幾個字或大到幾千位元組的分配單元。每個分配單元對應於點陣圖中的一位,0 表示空閒, 1 表示佔用(或者相反)。一塊記憶體區域和其對應的點陣圖如下
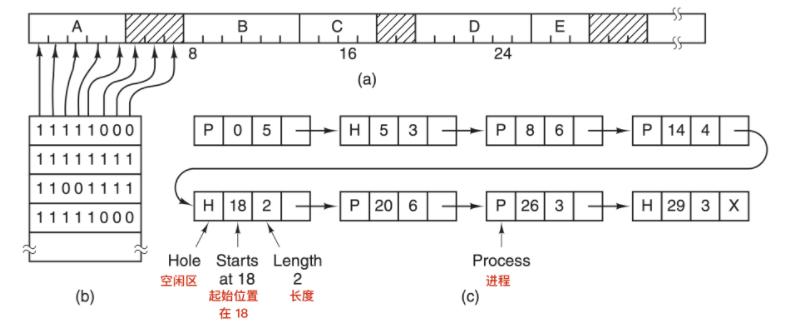
> 圖 a 表示一段有 5 個程序和 3 個空閒區的記憶體,刻度為記憶體分配單元,陰影區表示空閒(在點陣圖中用 0 表示);圖 b 表示對應的點陣圖;圖 c 表示用連結串列表示同樣的資訊
分配單元的大小是一個重要的設計因素,分配單位越小,點陣圖越大。然而,即使只有 4 位元組的分配單元,32 位的記憶體也僅僅只需要點陣圖中的 1 位。`32n` 位的記憶體需要 n 位的點陣圖,所以**1 個位圖只佔用了 1/32 的記憶體**。如果選擇更大的記憶體單元,點陣圖應該要更小。如果程序的大小不是分配單元的整數倍,那麼在最後一個分配單元中會有大量的記憶體被浪費。
`點陣圖`提供了一種簡單的方法在固定大小的記憶體中跟蹤記憶體的使用情況,因為**點陣圖的大小取決於記憶體和分配單元的大小**。這種方法有一個問題,當決定為把具有 k 個分配單元的程序放入記憶體時,`內容管理器(memory manager)` 必須搜尋點陣圖,在點陣圖中找出能夠執行 k 個連續 0 位的串。在點陣圖中找出制定長度的連續 0 串是一個很耗時的操作,這是點陣圖的缺點。(可以簡單理解為在雜亂無章的陣列中,找出具有一大長串空閒的陣列單元)
#### 使用空閒連結串列
另一種記錄記憶體使用情況的方法是,維護一個記錄已分配記憶體段和空閒記憶體段的連結串列,段會包含程序或者是兩個程序的空閒區域。可用上面的圖 c **來表示記憶體的使用情況**。連結串列中的每一項都可以代表一個 `空閒區(H)` 或者是`程序(P)`的起始標誌,長度和下一個連結串列項的位置。
在這個例子中,`段連結串列(segment list)`是按照地址排序的。這種方式的優點是,當程序終止或被交換時,更新列表很簡單。一個終止程序通常有兩個鄰居(除了記憶體的頂部和底部外)。相鄰的可能是程序也可能是空閒區,它們有四種組合方式。
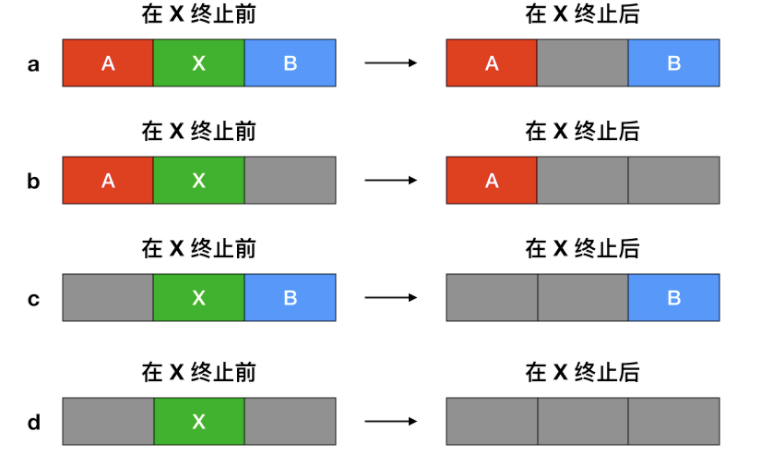
當按照地址順序在連結串列中存放程序和空閒區時,有幾種演算法可以為建立的程序(或者從磁碟中換入的程序)分配記憶體。
* 首次適配演算法:在連結串列中進行搜尋,直到找到最初的一個足夠大的空閒區,將其分配。除非程序大小和空間區大小恰好相同,否則會將空閒區分為兩部分,一部分為程序使用,一部分成為新的空閒區。該方法是速度很快的演算法,因為索引連結串列結點的個數較少。
* 下次適配演算法:工作方式與首次適配演算法相同,但每次找到新的空閒區位置後都記錄當前位置,下次尋找空閒區從上次結束的地方開始搜尋,而不是與首次適配放一樣從頭開始;
* 最佳適配演算法:搜尋整個連結串列,找出能夠容納程序分配的最小的空閒區。這樣存在的問題是,儘管可以保證為程序找到一個最為合適的空閒區進行分配,但大多數情況下,這樣的空閒區被分為兩部分,一部分用於程序分配,一部分會生成很小的空閒區,而這樣的空閒區很難再被進行利用。
* 最差適配演算法:與最佳適配演算法相反,每次分配搜尋最大的空閒區進行分配,從而可以使得空閒區拆分得到的新的空閒區可以更好的被進行利用。
### 頁面置換演算法都有哪些
在地址對映過程中,如果在頁面中發現所要訪問的頁面不在記憶體中,那麼就會產生一條缺頁中斷。當發生缺頁中斷時,如果作業系統記憶體中沒有空閒頁面,那麼作業系統必須在記憶體選擇一個頁面將其移出記憶體,以便為即將調入的頁面讓出空間。而用來選擇淘汰哪一頁的規則叫做頁面置換演算法。
下面我彙總的這些頁面置換演算法比較齊全,只給出簡單介紹,演算法具體的實現和原理讀者可以自行了解。
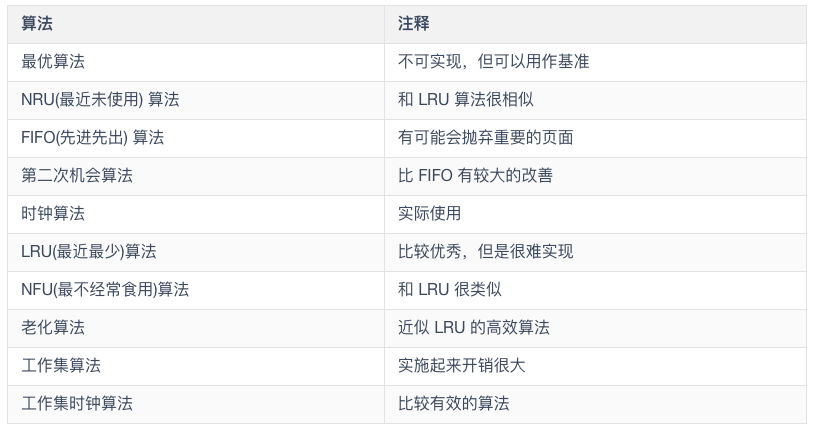
- `最優演算法`在當前頁面中置換最後要訪問的頁面。不幸的是,沒有辦法來判定哪個頁面是最後一個要訪問的,`因此實際上該演算法不能使用`。然而,它可以作為衡量其他演算法的標準。
- `NRU` 演算法根據 R 位和 M 位的狀態將頁面氛圍四類。從編號最小的類別中隨機選擇一個頁面。NRU 演算法易於實現,但是效能不是很好。存在更好的演算法。
- `FIFO` 會跟蹤頁面載入進入記憶體中的順序,並把頁面放入一個連結串列中。有可能刪除存在時間最長但是還在使用的頁面,因此這個演算法也不是一個很好的選擇。
- `第二次機會`演算法是對 FIFO 的一個修改,它會在刪除頁面之前檢查這個頁面是否仍在使用。如果頁面正在使用,就會進行保留。這個改進大大提高了效能。
- `時鐘` 演算法是第二次機會演算法的另外一種實現形式,時鐘演算法和第二次演算法的效能差不多,但是會花費更少的時間來執行演算法。
- `LRU` 演算法是一個非常優秀的演算法,但是沒有`特殊的硬體(TLB)`很難實現。如果沒有硬體,就不能使用 LRU 演算法。
- `NFU` 演算法是一種近似於 LRU 的演算法,它的效能不是非常好。
- `老化` 演算法是一種更接近 LRU 演算法的實現,並且可以更好的實現,因此是一個很好的選擇
- 最後兩種演算法都使用了工作集演算法。工作集演算法提供了合理的效能開銷,但是它的實現比較複雜。`WSClock` 是另外一種變體,它不僅能夠提供良好的效能,而且可以高效地實現。
**最好的演算法是老化演算法和WSClock演算法**。他們分別是基於 LRU 和工作集演算法。他們都具有良好的效能並且能夠被有效的實現。還存在其他一些好的演算法,但實際上這兩個可能是最重要的。
## 檔案系統篇
### 提高檔案系統性能的方式
訪問磁碟的效率要比記憶體慢很多,是時候又祭出這張圖了
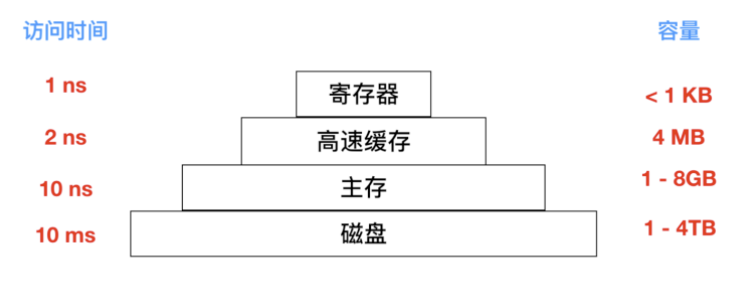
所以磁碟優化是很有必要的,下面我們會討論幾種優化方式
#### 快取記憶體
最常用的減少磁碟訪問次數的技術是使用 `塊快取記憶體(block cache)` 或者 `緩衝區快取記憶體(buffer cache)`。快取記憶體指的是一系列的塊,它們在邏輯上屬於磁碟,但實際上基於效能的考慮被儲存在記憶體中。
管理快取記憶體有不同的演算法,常用的演算法是:檢查全部的讀請求,檢視在快取記憶體中是否有所需要的塊。如果存在,可執行讀操作而無須訪問磁碟。如果檢查塊不再快取記憶體中,那麼首先把它讀入快取記憶體,再複製到所需的地方。之後,對同一個塊的請求都通過`快取記憶體`來完成。
快取記憶體的操作如下圖所示
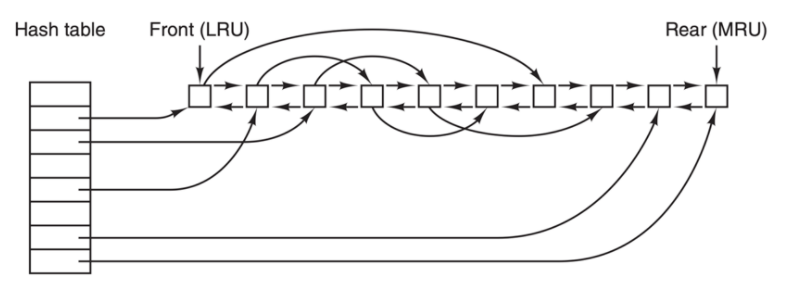
由於在快取記憶體中有許多塊,所以需要某種方法快速確定所需的塊是否存在。常用方法是將裝置和磁碟地址進行雜湊操作。然後在散列表中查詢結果。具有相同雜湊值的塊在一個連結串列中連線在一起(這個資料結構是不是很像 HashMap?),這樣就可以沿著衝突鏈查詢其他塊。
如果快取記憶體`已滿`,此時需要調入新的塊,則要把原來的某一塊調出快取記憶體,如果要調出的塊在上次調入後已經被修改過,則需要把它寫回磁碟。這種情況與分頁非常相似。
#### 塊提前讀
第二個明顯提高檔案系統的效能是**在需要用到塊之前試圖提前將其寫入快取記憶體從而提高命中率**。許多檔案都是`順序讀取`。如果請求檔案系統在某個檔案中生成塊 k,檔案系統執行相關操作並且在完成之後,會檢查快取記憶體,以便確定塊 k + 1 是否已經在快取記憶體。如果不在,檔案系統會為 k + 1 安排一個預讀取,因為檔案希望在用到該塊的時候能夠直接從快取記憶體中讀取。
當然,塊提前讀取策略只適用於實際順序讀取的檔案。對隨機訪問的檔案,提前讀絲毫不起作用。甚至還會造成阻礙。
#### 減少磁碟臂運動
快取記憶體和塊提前讀並不是提高檔案系統性能的唯一方法。另一種重要的技術是**把有可能順序訪問的塊放在一起,當然最好是在同一個柱面上,從而減少磁碟臂的移動次數**。當寫一個輸出檔案時,檔案系統就必須按照要求一次一次地分配磁碟塊。如果用點陣圖來記錄空閒塊,並且整個點陣圖在記憶體中,那麼選擇與前一塊最近的空閒塊是很容易的。如果用空閒表,並且連結串列的一部分存在磁碟上,要分配緊鄰的空閒塊就會困難很多。
不過,即使採用空閒表,也可以使用 `塊簇` 技術。即不用塊而用連續塊簇來跟蹤磁碟儲存區。如果一個扇區有 512 個位元組,有可能系統採用 1 KB 的塊(2 個扇區),但卻按每 2 塊(4 個扇區)一個單位來分配磁碟儲存區。這和 2 KB 的磁碟塊並不相同,因為在快取記憶體中它仍然使用 1 KB 的塊,磁碟與記憶體資料之間傳送也是以 1 KB 進行,但在一個空閒的系統上順序讀取這些檔案,尋道的次數可以減少一半,從而使檔案系統的效能大大改善。若考慮旋轉定位則可以得到這類方法的變體。在分配塊時,系統儘量把一個檔案中的連續塊存放在同一個柱面上。
在使用 inode 或任何類似 inode 的系統中,另一個性能瓶頸是,讀取一個很短的檔案也需要兩次磁碟訪問:**一次是訪問 inode,一次是訪問塊**。通常情況下,inode 的放置如下圖所示
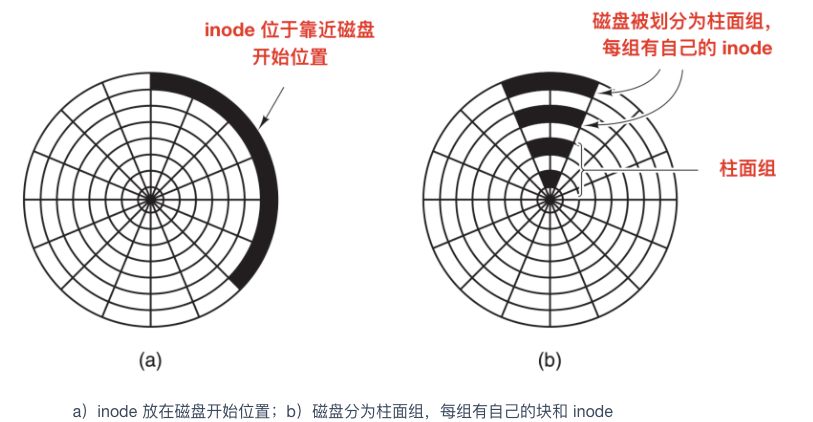
其中,全部 inode 放在靠近磁碟開始位置,所以 inode 和它所指向的塊之間的平均距離是柱面組的一半,這將會需要較長時間的尋道時間。
一個簡單的改進方法是,在磁碟中部而不是開始處存放 inode ,此時,在 inode 和第一個塊之間的尋道時間減為原來的一半。另一種做法是:將磁碟分成多個柱面組,每個柱面組有自己的 inode,資料塊和空閒表,如上圖 b 所示。
當然,只有在磁碟中裝有磁碟臂的情況下,討論尋道時間和旋轉時間才是有意義的。現在越來越多的電腦使用 `固態硬碟(SSD)`,對於這些硬碟,由於採用了和快閃記憶體同樣的製造技術,使得隨機訪問和順序訪問在傳輸速度上已經較為相近,傳統硬碟的許多問題就消失了。但是也引發了新的問題。
#### 磁碟碎片整理
在初始安裝作業系統後,檔案就會被不斷的建立和清除,於是磁碟會產生很多的碎片,在建立一個檔案時,它使用的塊會散佈在整個磁碟上,降低效能。刪除檔案後,回收磁碟塊,可能會造成空穴。
磁碟效能可以通過如下方式恢復:移動檔案使它們相互挨著,並把所有的至少是大部分的空閒空間放在一個或多個大的連續區域內。Windows 有一個程式 `defrag` 就是做這個事兒的。Windows 使用者會經常使用它,SSD 除外。
磁碟碎片整理程式會在讓檔案系統上很好地執行。Linux 檔案系統(特別是 ext2 和 ext3)由於其選擇磁碟塊的方式,在磁碟碎片整理上一般不會像 Windows 一樣困難,因此很少需要手動的磁碟碎片整理。而且,固態硬碟並不受磁碟碎片的影響,事實上,在固態硬碟上做磁碟碎片整理反倒是多此一舉,不僅沒有提高效能,反而磨損了固態硬碟。所以碎片整理只會縮短固態硬碟的壽命。
### 磁碟臂排程演算法
一般情況下,影響磁碟快讀寫的時間由下面幾個因素決定
* 尋道時間 - 尋道時間指的就是將磁碟臂移動到需要讀取磁碟塊上的時間
* 旋轉延遲 - 等待合適的扇區旋轉到磁頭下所需的時間
* 實際資料的讀取或者寫入時間
這三種時間引數也是磁碟尋道的過程。一般情況下,尋道時間對總時間的影響最大,所以,有效的降低尋道時間能夠提高磁碟的讀取速度。
如果磁碟驅動程式每次接收一個請求並按照接收順序完成請求,這種處理方式也就是 `先來先服務(First-Come, First-served, FCFS)` ,這種方式很難優化尋道時間。因為每次都會按照順序處理,不管順序如何,有可能這次讀完後需要等待一個磁碟旋轉一週才能繼續讀取,而其他柱面能夠馬上進行讀取,這種情況下每次請求也會排隊。
通常情況下,磁碟在進行尋道時,其他程序會產生其他的磁碟請求。磁碟驅動程式會維護一張表,表中會記錄著柱面號當作索引,每個柱面未完成的請求會形成連結串列,連結串列頭存放在表的相應表項中。
一種對先來先服務的演算法改良的方案是使用 `最短路徑優先(SSF)` 演算法,下面描述了這個演算法。
假如我們在對磁軌 6 號進行定址時,同時發生了對 11 , 2 , 4, 14, 8, 15, 3 的請求,如果採用先來先服務的原則,如下圖所示
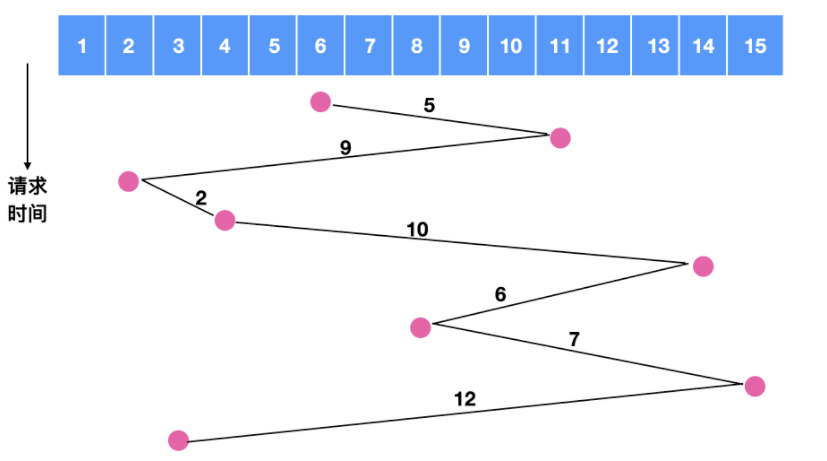
我們可以計算一下磁碟臂所跨越的磁碟數量為 5 + 9 + 2 + 10 + 6 + 7 + 12 = 51,相當於是跨越了 51 次盤面,如果使用最短路徑優先,我們來計算一下跨越的盤面
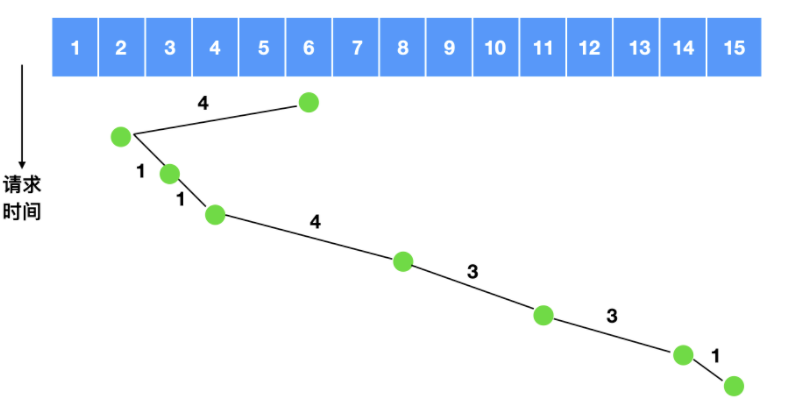
跨越的磁碟數量為 4 + 1 + 1 + 4 + 3 + 3 + 1 = 17 ,相比 51 足足省了兩倍的時間。
但是,最短路徑優先的演算法也不是完美無缺的,這種演算法照樣存在問題,那就是`優先順序` 問題,
這裡有一個原型可以參考就是我們日常生活中的電梯,電梯使用一種`電梯演算法(elevator algorithm)` 來進行排程,從而滿足協調效率和公平性這兩個相互衝突的目標。電梯一般會保持向一個方向移動,直到在那個方向上沒有請求為止,然後改變方向。
電梯演算法需要維護一個`二進位制位`,也就是當前的方向位:`UP(向上)`或者是 `DOWN(向下)`。當一個請求處理完成後,磁碟或電梯的驅動程式會檢查該位,如果此位是 UP 位,磁碟臂或者電梯倉移到下一個更高跌未完成的請求。如果高位沒有未完成的請求,則取相反方向。當方向位是 `DOWN `時,同時存在一個低位的請求,磁碟臂會轉向該點。如果不存在的話,那麼它只是停止並等待。
我們舉個例子來描述一下電梯演算法,比如各個柱面得到服務的順序是 4,7,10,14,9,6,3,1 ,那麼它的流程圖如下
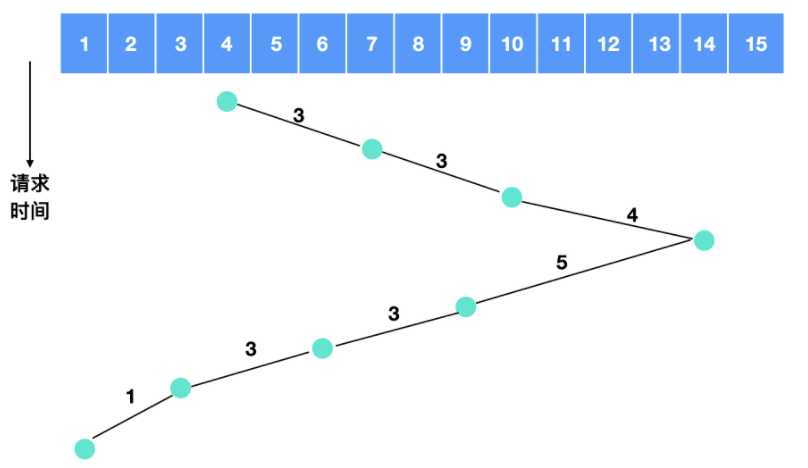
所以電梯演算法需要跨越的盤面數量是 3 + 3 + 4 + 5 + 3 + 3 + 1 = 22
電梯演算法通常情況下不如 SSF 演算法。
一些磁碟控制器為軟體提供了一種檢查磁頭下方當前扇區號的方法,使用這樣的控制器,能夠進行另一種優化。如果對一個相同的柱面有兩個或者多個請求正等待處理,驅動程式可以發出請求讀寫下一次要通過磁頭的扇區。
>這裡需要注意一點,當一個柱面有多條磁軌時,相繼的請求可能針對不同的磁軌,這種選擇沒有代價,因為選擇磁頭不需要移動磁碟臂也沒有旋轉延遲。
對於磁碟來說,最影響效能的就是尋道時間和旋轉延遲,所以一次只讀取一個或兩個扇區的效率是非常低的。出於這個原因,許多磁碟控制器總是讀出多個扇區並進行快取記憶體,即使只請求一個扇區時也是這樣。一般情況下讀取一個扇區的同時會讀取該扇區所在的磁軌或者是所有剩餘的扇區被讀出,讀出扇區的數量取決於控制器的快取記憶體中有多少可用的空間。
磁碟控制器的快取記憶體和作業系統的快取記憶體有一些不同,磁碟控制器的快取記憶體用於快取沒有實際被請求的塊,而作業系統維護的快取記憶體由顯示地讀出的塊組成,並且作業系統會認為這些塊在近期仍然會頻繁使用。
當同一個控制器上有多個驅動器時,作業系統應該為每個驅動器都單獨的維護一個未完成的請求表。一旦有某個驅動器閒置時,就應該發出一個尋道請求來將磁碟臂移到下一個被請求的柱面。如果下一個尋道請求到來時恰好沒有磁碟臂處於正確的位置,那麼驅動程式會在剛剛完成傳輸的驅動器上發出一個新的尋道命令並等待,等待下一次中斷到來時檢查哪個驅動器處於閒置狀態。
### RAID 的不同級別
RAID 稱為 `磁碟冗餘陣列`,簡稱 `磁碟陣列`。利用虛擬化技術把多個硬碟結合在一起,成為一個或多個磁碟陣列組,目的是提升效能或資料冗餘。
RAID 有不同的級別
* RAID 0 - 無容錯的條帶化磁碟陣列
* RAID 1 - 映象和雙工
* RAID 2 - 記憶體式糾錯碼
* RAID 3 - 位元交錯奇偶校驗
* RAID 4 - 塊交錯奇偶校驗
* RAID 5 - 塊交錯分散式奇偶校驗
* RAID 6 - P + Q冗餘
## IO 篇
### 作業系統中的時鐘是什麼
`時鐘(Clocks)` 也被稱為`定時器(timers)`,時鐘/定時器對任何程式系統來說都是必不可少的。時鐘負責維護時間、防止一個程序長期佔用 CPU 時間等其他功能。`時鐘軟體(clock software)` 也是一種裝置驅動的方式。下面我們就來對時鐘進行介紹,一般都是先討論硬體再介紹軟體,採用由下到上的方式,也是告訴你,底層是最重要的。
#### 時鐘硬體
在計算機中有兩種型別的時鐘,這些時鐘與現實生活中使用的時鐘完全不一樣。
* 比較簡單的一種時鐘被連線到 110 V 或 220 V 的電源線上,這樣每個`電壓週期`會產生一箇中斷,大概是 50 - 60 HZ。這些時鐘過去一直佔據支配地位。
* 另外的一種時鐘由晶體振盪器、計數器和暫存器組成,示意圖如下所示
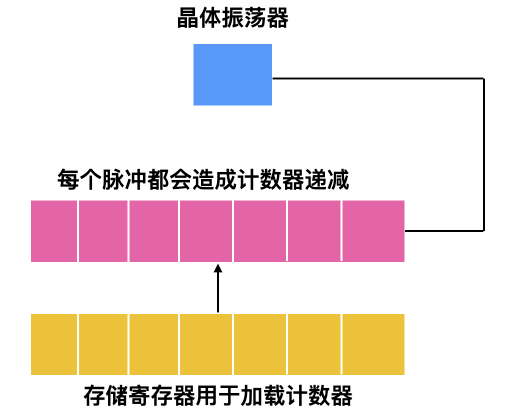
這種時鐘稱為`可程式設計時鐘` ,可程式設計時鐘有兩種模式,一種是 `一鍵式(one-shot mode)`,當時鍾啟動時,會把儲存器中的值複製到計數器中,然後,每次晶體的振盪器的脈衝都會使計數器 -1。當計數器變為 0 時,會產生一箇中斷,並停止工作,直到軟體再一次顯示啟動。還有一種模式時 `方波(square-wave mode)` 模式,在這種模式下,當計數器變為 0 併產生中斷後,儲存暫存器的值會自動複製到計數器中,這種週期性的中斷稱為一個時鐘週期。
### 裝置控制器的主要功能
裝置控制器是一個`可編址`的裝置,當它僅控制一個裝置時,它只有一個唯一的裝置地址;如果裝置控制器控制多個可連線裝置時,則應含有多個裝置地址,並使每一個裝置地址對應一個裝置。
裝置控制器主要分為兩種:字元裝置和塊裝置
裝置控制器的主要功能有下面這些
* 接收和識別命令:裝置控制器可以接受來自 CPU 的指令,並進行識別。裝置控制器內部也會有暫存器,用來存放指令和引數
* 進行資料交換:CPU、控制器和裝置之間會進行資料的交換,CPU 通過匯流排把指令傳送給控制器,或從控制器中並行地讀出資料;控制器將資料寫入指定裝置。
* 地址識別:每個硬體裝置都有自己的地址,裝置控制器能夠識別這些不同的地址,來達到控制硬體的目的,此外,為使 CPU 能向暫存器中寫入或者讀取資料,這些暫存器都應具有唯一的地址。
* 差錯檢測:裝置控制器還具有對裝置傳遞過來的資料進行檢測的功能。
### 中斷處理過程
中斷處理方案有很多種,下面是 《**ARM System Developer’s Guide**
**Designing and Optimizing System Software**》列出來的一些方案
* `非巢狀`的中斷處理程式按照順序處理各個中斷,非巢狀的中斷處理程式也是最簡單的中斷處理
* `巢狀`的中斷處理程式會處理多箇中斷而無需分配優先順序
* `可重入`的中斷處理程式可使用優先順序處理多箇中斷
* `簡單優先順序`中斷處理程式可處理簡單的中斷
* `標準優先順序`中斷處理程式比低優先順序的中斷處理程式在更短的時間能夠處理優先順序更高的中斷
* `高優先順序` 中斷處理程式在短時間能夠處理優先順序更高的任務,並直接進入特定的服務例程。
* `優先順序分組`中斷處理程式能夠處理不同優先順序的中斷任務
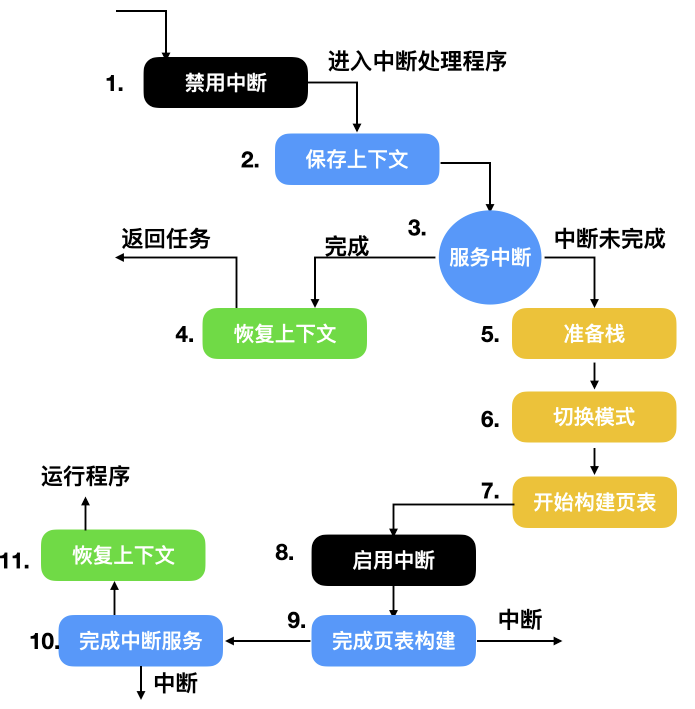
下面是一些通用的中斷處理程式的步驟,不同的作業系統實現細節不一樣
* 儲存所有沒有被中斷硬體儲存的暫存器
* 為中斷服務程式設定上下文環境,可能包括設定 `TLB`、`MMU` 和頁表,如果不太瞭解這三個概念,請參考另外一篇文章
* 為中斷服務程式設定棧
* 對中斷控制器作出響應,如果不存在集中的中斷控制器,則繼續響應中斷
* 把暫存器從儲存它的地方拷貝到程序表中
* 執行中斷服務程式,它會從發出中斷的裝置控制器的暫存器中提取資訊
* 作業系統會選擇一個合適的程序來執行。如果中斷造成了一些優先順序更高的程序變為就緒態,則選擇執行這些優先順序高的程序
* 為程序設定 MMU 上下文,可能也會需要 TLB,根據實際情況決定
* 載入程序的暫存器,包括 PSW 暫存器
* 開始執行新的程序
上面我們羅列了一些大致的中斷步驟,不同性質的作業系統和中斷處理程式能夠處理的中斷步驟和細節也不盡相同,下面是一個巢狀中斷的具體執行步驟
### 什麼是裝置驅動程式
在計算機中,裝置驅動程式是一種計算機程式,它能夠控制或者操作連線到計算機的特定裝置。驅動程式提供了與硬體進行互動的軟體介面,使作業系統和其他計算機程式能夠訪問特定裝置,不用需要了解其硬體的具體構造。
### 什麼是 DMA
DMA 的中文名稱是`直接記憶體訪