
MySQL深入研究--學習總結(1)
阿新 • • 發佈:2021-03-01
#前言
本文是筆者學習“林曉斌”老師的《MySQL實戰45講》過程中的,對知識點的總結歸納以及對問題的思考記錄,課程18年11月就出了,當時連載形式,我就上班途中一邊開車一邊聽,學的比較糙,時隔兩年現在再回頭仔細回顧總結下。《MySQL實戰45講》是極客時間的收費課程,價格幾十塊並不貴,但是絕對是一個好課程,筆者收益頗深,推薦大家閱讀。
#第一章《一條查詢SQL是如何執行的》總結
在第一篇文章中,作者主要通過一條查詢SQL是如何執行的為出發點,介紹了MySQL的組成部分,每個部分做哪些事:
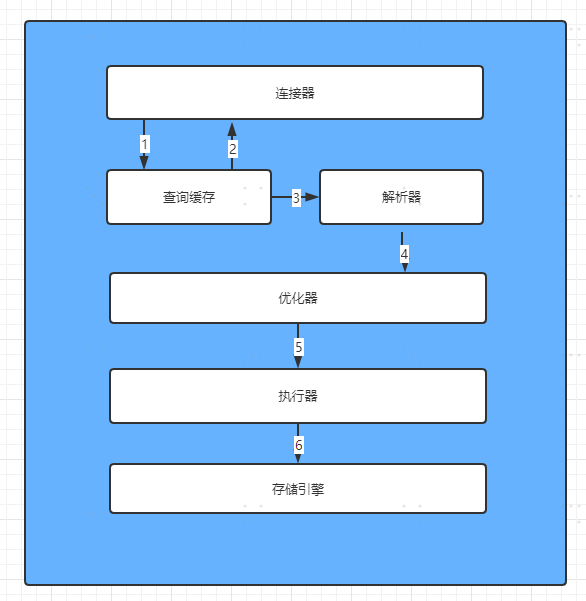
##名詞解釋
聯結器:主要管理與客戶端的連線,鑑權以及安全性的校驗工作。
查詢快取:MySQL為了提高查詢效率,可能會將熱點資料放入記憶體中,以便下次查詢直接從查詢快取中返回資料。
分析器:當快取中沒有命中,就會想通過分析器,對SQL進行語法分析,是否合法等。
優化器:主要工作就是查詢動作的優化,比如是否走索引,選擇哪一個索引等。
執行器:負責執行SQL的部分,通過介面與儲存引擎互動,獲取查詢結果並返回。
儲存引擎:負責MySQL的資料儲存和提取,索引結構都是有儲存引擎定義的,並且是可拔插式的,使用者可以根據自己需求選擇不同的儲存引擎,主要有InnoDB和MyISMA,MySQL5.5.5之後預設使用的是InnoDB。
##執行步驟
那麼一條查詢SQL時如何通過這些元件執行的呢?
1、首先客戶端需要連線到MySQL服務端,這時就需要聯結器來驗證使用者名稱和密碼,建立TCP連線了。連線後如果連線長期處理空閒狀態,聯結器就會自動斷開他,預設是8小時,可以通過wait_timeout設定。
2、連線成功後,客戶端向MySQL傳送執行命令,比如傳送一條查詢語句:SELECT * FROM user WHERE id = 1;首先MySQL會在查詢快取中看是否存在該條資料的快取,如果有就直接返回。沒有則進入下一步。其實查詢快取在8.0版本後就移除了,因為查詢快取會在更新時全部清空,所以對於更新頻率較高的場景,查詢快取會變得費力不討好了,也可以通過query_cash_type設定成DEMAND禁用查詢快取。
3、先經過分析器,對改條SQL進行語法分析,是否符合語法規範,是查詢語句還是更新語句等,是需要對哪張表進行操作。
4、之後通過優化器,發現id是主鍵,可以使用主鍵索引。
5、通過執行器,執行該條SQL之前會先校驗有沒有執行許可權,如果有,執行器會通過該表儲存引擎提供的介面,儲存引擎通過索引樹找出id=1的資料後,MySQL返回給客戶端。
#第二章《一條更新SQL是如何執行的》總結
上一章我們通過查詢流程瞭解了MySQL各模組的功能,其實更新時也查不多,只不過為了保證資料的可恢復性引入了兩個日誌:redo_log和bin_log。那麼為什麼需要有這兩個日誌呢?
## redo_log
首先redo_log是innoDB引擎提供的。當有資料更新或者插入時,innoDB並不是直接持久到磁碟,而是先修改緩衝池中的資料,成功後直接返回成功,再選擇“合適的時機”刷入磁碟中。
那麼有的同學就會問了,那如果記憶體中的資料還沒來及刷到磁碟就crash(宕機)了,資料不就是丟失了嗎?
是的,為了解決這個問題,innoDB引入了redo_log來解決這個問題。
當有插入更新請求時,innoDB先將結果寫入的redo_log日誌檔案中,再修改緩衝池資料頁,最後再適當的時候重新整理到磁碟。這樣即使宕機時,也可以通過redo_log恢復丟失的資料,這就是所謂的WAL技術 write-ahead-logging。
redo log在innoDB中是固定大小的,由4個1G的檔案組成,所以redo log 是迴圈寫的。
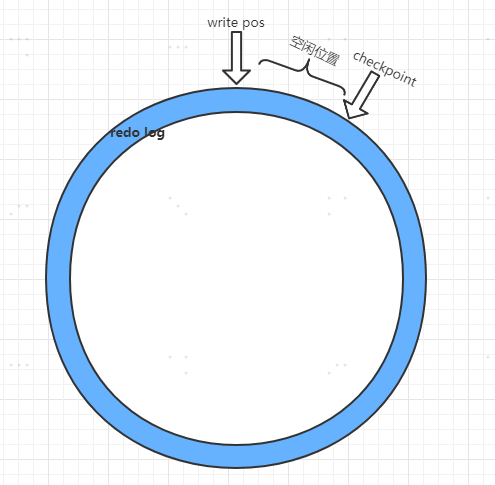
可以把染色環裝理解為由4個redo log 檔案組成的。
checkpoint:當前資料擦除的位置,擦除前要把記錄更新到資料檔案。
write pos:當前記錄的位置。
checkpoint與write pos之間就是空閒部分,可以持續往後寫,當write pos追上checkpoint時,說明檔案都沒寫滿,如果繼續寫,就需要停下來擦除一些資料,把checkpoint繼續往前移。
有了redo log,innoDB就可以保證即使資料庫發生異常重啟,之前提交的記錄都不會丟失,這個能力稱為crash-safe。
**這裡做個擴充套件:**當資料庫寫物理頁時,如果宕機了,那麼可能會導致物理頁的一致性被破壞。
可能有人會說,重做日誌不是可以恢復物理頁嗎?實際上是的,但是要求是在物理頁一致的情況下。
也就是說,如果物理頁完全是未寫之前的狀態,則可以用重做日誌恢復。如果物理頁已經完全寫完了,那麼也可以用重做日誌恢復。但是如果物理頁前面2K寫了新的資料,但是後面2K還是舊的資料,則種情況下就無法使用重做日誌恢復了。
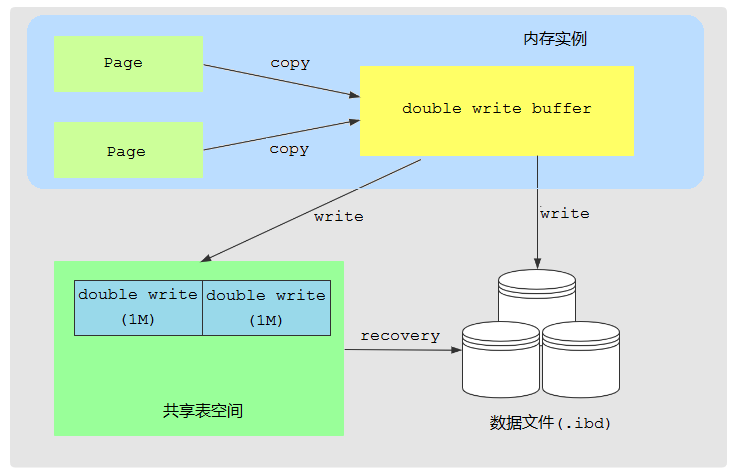
這裡的兩次寫就是保證了物理頁的一致性,使得即使宕機,也可以用重做日誌恢復。
在寫物理頁時,並不是直接寫到真正的物理頁上去,而是先寫到一個臨時頁上去,臨時頁寫完後,再寫物理頁。這樣一來:
A. 如果寫臨時頁時宕機了,物理頁還是完全未寫之前的狀態,可以用重做日誌恢復
B. 如果寫物理頁時宕機了,則可以使用臨時頁來恢復物理頁
InnoDB中共享表空間中劃了2M的空間,叫做double write,專門存放臨時頁。
InnoDB還從記憶體中劃出了2M的快取空間,叫做double write buffer,專門快取臨時頁。
每次寫物理頁時,先寫到double write buffer中,然後從double write buffer寫到double write上去。最後再從double write buffer寫到物理頁上去。
## bin_log
binlog是MySQL的server層提供的,是跨儲存引擎的,做歸檔用的。因為沒有crash-safa能力,所以innoDB自己引入了redolog。
這兩種日誌有以下三點不同。
1 . redolog是innoDB引擎特有的;binlogg是MySQL的Server 層實現的,所有引擎都可以使用。
2 . redolog是物理日誌,記錄的是“在某個資料頁上做了什麼修改”;binlogg是邏輯日誌,記錄的是這個語句的原始邏輯,比如“給ID= 2這一行的c 欄位加1 ”。
3 . redolog是迴圈寫的,空間固定會用完;binlogg是可以追加寫入的。“追加寫”是指binlogg檔案寫到一定大小後會切換到下一個,並不會覆蓋以前的日誌。
## 更新語句的執行流程
1、當MySQL接收到一條更新語句時update user name="老王" where id =1;,除了上面查詢的那些前期步驟,執行器呼叫儲存引擎介面獲取到id=1 的資料。
2、執行器獲取資料後,先將name改為老王的資料,呼叫引擎介面,將資料寫入到redolog中,並處於prepared狀態。
3、redolog寫完後,修改緩衝池的資料。並返回給執行器。
4、執行器獲得結果後,記錄到binlog中,並修改redolog該條記錄改為commit狀態,更新完成。
之所以分兩次修改redolog是為了與binlog保證資料一致。
#第三章《事務隔離》
##事務基本概念
這章節沒什麼好說的,主要介紹了事務的特性,隔離級別以及事務的實現。
說到事務,大家都知道ACID,即原子性,一致性,隔離性,永續性。
多個事務操作同一資料,可能出現的問題:
髒讀:一個事務讀取到的另一個事務沒有提交的資料。
不可重複讀:在一個事務中兩次讀取同一資料結果不一致。
幻讀:在一個事務中兩次讀取資料的數量不一致。
隔離級別
讀未提交:可以讀到另一個事務中沒有提交的資料。
讀已提交:可以讀到另一個事務已提交的資料。
可重複讀:在一個事務中,即使另一個事務已提交了,在本事務中多次讀取資料都是跟事務啟動時讀取的一致的。
序列化:最高的隔離級別,對同一行資料,讀會加讀鎖,寫會加寫鎖,最安全但效率也最低。
##事務的實現
在事務開啟時,生成一張檢視,在事務執行期間讀取的資料都是基於這張檢視的,這是靜態的並不受其他事務影響。
本質上,在MySQL中,當資料發生更新時,都會生成一條回滾操作,通過回滾操作可以獲得操作前的狀態,在事務中,每次操作都會被記錄,直至事務被提交,回滾段才會被清理。所以在未提交之前,都可以通過回滾日誌undo log,逐步將資料恢復到事務開啟前的狀態。
在5.5版本之前,回滾日誌是儲存在ibdata檔案中的,日誌回滾段被清理,檔案大小也不會變,所以日常開發中,我們應該儘量避免長事務,應該在長事務中會保留很老的