
redis基礎:redis下載安裝與配置,redis資料型別使用,redis常用指令,jedis使用,RDB和AOF持久化
知識點梳理
課堂講義
課程計劃
| 1. REDIS 入 門 | (瞭解) | (操作) | |
|---|---|---|---|
| 2. 資料型別 | (重點) | (操作) | (理解) |
| 3. 常用指令 | (操作) | ||
| 4. Jedis | (重點) | (操作) | |
| 5. 持 久 化 | (重點) | (理解) | |
| 6. 資料刪除與淘汰策略 | (理解) | ||
| 7. 主從複製 | (重點) | (操作) | (理解) |
| 8. 哨 兵 | (重點) | (操作) | (理解) |
| 9. Cluster叢集方案 | (重點) | (操作) | (理解) |
| 10. 企業級快取解決方案 | (重點) | (理解) | |
| 11. 效能指標監控 | (瞭解) |
1. Redis 簡介
在這個部分,我們將學習以下3個部分的內容,分別是:
◆ Redis 簡介(NoSQL概念、Redis概念)
◆ Redis 的下載與安裝
◆ Redis 的基本操作
1.1 NoSQL概念
1.1.1 問題現象
在講解NoSQL的概念之前呢,我們先來看一個現象:
(1)問題現象
每年到了過年期間,大家都會自覺自發的組織一場活動,叫做春運!以前我們買票都是到火車站排隊,後來呢有了12306,有了他以後就更方便了,我們可以在網上買票,但是帶來的問題,大家也很清楚,春節期間買票進不去,進去了刷不著票。什麼原因呢,人太多了!

除了這種做鐵路的,它系統做的不專業以外,還有馬爸爸做的淘寶,它面臨一樣的問題。淘寶也崩,也是使用者量太大!作為我們整個電商界的東哥來說,他第一次做圖書促銷的時候,也遇到了伺服器崩掉的這樣一個現象,原因同樣是因為使用者量太大!

(2)現象特徵
再來看這幾個現象,有兩個非常相似的特徵:
第一,使用者比較多,海量使用者
第二,高併發
這兩個現象出現以後,對應的就會造成我們的伺服器癱瘓。核心本質是什麼呢?其實並不是我們的應用伺服器,而是我們的關係型資料庫。關係型資料庫才是最終的罪魁禍首!
(3)造成原因
什麼樣的原因導致的整個系統崩掉的呢:
1.效能瓶頸:磁碟IO效能低下
關係型資料庫菜存取資料的時候和讀取資料的時候他要走磁碟IO。磁碟這個效能本身是比較低的。
2.擴充套件瓶頸:資料關係複雜,擴充套件性差,不便於大規模叢集
我們說關係型資料庫,它裡面表與表之間的關係非常複雜,不知道大家能不能想象一點,就是一張表,通過它的外來鍵關聯了七八張表,這七八張表又通過她的外來鍵,每張又關聯了四五張表。你想想,查詢一下,你要想拿到資料,你就要從A到B、B到C、C到D的一直這麼關聯下去,最終非常影響查詢的效率。同時,你想擴充套件下,也很難!
(4)解決思路
面對這樣的現象,我們要想解決怎麼版呢。兩方面:
一,降低磁碟IO次數,越低越好。
二,去除資料間關係,越簡單越好。
降低磁碟IO次數,越低越好,怎麼搞?我不用你磁碟不就行了嗎?於是,記憶體儲存的思想就提出來了,我資料不放到你磁盤裡邊,放記憶體裡,這樣是不是效率就高了。
第二,你的資料關係很複雜,那怎麼辦呢?乾脆簡單點,我斷開你的關係,我不存關係了,我只存資料,這樣不就沒這事了嗎?
把這兩個特徵一合併一起,就出來了一個新的概念:NoSQL
1.1.2 NoSQL的概念
(1)概念
NoSQL:即 Not-Only SQL( 泛指非關係型的資料庫),作為關係型資料庫的補充。 作用:應對基於海量使用者和海量資料前提下的資料處理問題。
他說這句話說的非常客氣,什麼意思呢?就是我們資料儲存要用SQL,但是呢可以不僅僅用SQL,還可以用別的東西,那別的東西叫什麼呢?於是他定義了一句話叫做NoSQL。這個意思就是說我們儲存資料,可以不光使用SQL,我們還可以使用非SQL的這種儲存方案,這就是所謂的NoSQL。
(2)特徵
可擴容,可伸縮。SQL資料關係過於複雜,你擴容一下難度很高,那我們Nosql 這種的,不存關係,所以它的擴容就簡單一些。
大資料量下高效能。包資料非常多的時候,它的效能高,因為你不走磁碟IO,你走的是記憶體,效能肯定要比磁碟IO的效能快一些。
靈活的資料模型、高可用。他設計了自己的一些資料儲存格式,這樣能保證效率上來說是比較高的,最後一個高可用,我們等到叢集內部分再去它!
(3)常見 Nosql 資料庫
目前市面上常見的Nosql產品:Redis、memcache、HBase、MongoDB
(4)應用場景-電商為例
我們以電商為例,來看一看他在這裡邊起到的作用。
第一類,在電商中我們的基礎資料一定要儲存起來,比如說商品名稱,價格,生產廠商,這些都屬於基礎資料,這些資料放在MySQL資料庫。
第二類,我們商品的附加資訊,比如說,你買了一個商品評價了一下,這個評價它不屬於商品本身。就像你買一個蘋果,“這個蘋果很好吃”就是評論,但是你能說很好吃是這個商品的屬性嘛?不能這麼說,那只是一個人對他的評論而已。這一類資料呢,我們放在另外一個地方,我們放到MongoDB。它也可以用來加快我們的訪問,他屬於NoSQL的一種。
第三,圖片內的資訊。注意這種資訊相對來說比較固定,他有專用的儲存區,我們一般用檔案系統來儲存。至於是不是分散式,要看你的系統的一個整個 瓶頸 了?如果說你發現你需要做分散式,那就做,不需要的話,一臺主機就搞定了。
第四,搜尋關鍵字。為了加快搜索,我們會用到一些技術,有些人可能瞭解過,像分ES、Lucene、solr都屬於搜尋技術。那說的這麼熱鬧,我們的電商解決方案中還沒出現我們的redis啊!注意第五類資訊。
第五,熱點資訊。訪問頻度比較高的資訊,這種東西的第二特徵就是它具有波段性。換句話說他不是穩定的,它具有一個時效性的。那麼這類資訊放哪兒了,放到我們的redis這個解決方案中來進行儲存。
具體的我們從我們的整個資料儲存結構的設計上來看一下。

我們的基礎資料都存MySQL,在它的基礎之上,我們把它連在一塊兒,同時對外提供服務。向上走,有一些資訊載入完以後,要放到我們的MongoDB中。還有一類資訊,我們放到我們專用的檔案系統中(比如圖片),就放到我們的這個搜尋專用的,如Lucene、solr及叢集裡邊,或者用ES的這種技術裡邊。那麼剩下來的熱點資訊,放到我們的redis裡面。
1.2 Redis概念
1.2.1 redis概念
概念:Redis (Remote Dictionary Server:遠端詞典伺服器) 是用 C 語言開發的一個開源的高效能(記憶體型)鍵值對(key-value)資料庫。
特徵:
(1)資料間沒有必然的關聯關係;
(2)內部採用單執行緒機制進行工作;
(3)高效能。官方提供測試資料,50個併發執行100000 個請求,讀的速度是110000 次/s,寫的速度是81000次/s。
(4)多資料型別支援
字串型別,string
列表型別,list
hash set
雜湊型別,zset/sorted_set
集合型別
有序集合型別
(5)支援持久化,可以進行資料災難恢復
1.2.2 redis的應用場景
(1)為熱點資料加速查詢(主要場景)。如熱點商品、熱點新聞、熱點資訊、推廣類等高訪問量資訊等。
(2)即時資訊查詢。如各位排行榜、各類網站訪問統計、公交到站資訊、線上人數資訊(聊天室、網站)、裝置訊號等。
(3)時效性資訊控制。如驗證碼控制、投票控制等。
(4)分散式資料共享。如分散式叢集架構中的 session 分離 (5)訊息佇列
1.3 Redis 的下載與安裝
後期所有資料分4中不同色塊顯示,詳情如下:

1.3.1 Redis 的下載與安裝
本課程所示,均基於Center OS7安裝Redis。
安裝的時候可能還會需要安裝gcc環境:所以可以參照:
http://blog.sina.com.cn/s/blog_ae829c5c0102z27v.html
(1)下載並安裝Redis
下載安裝包:
wget http://download.redis.io/releases/redis-5.0.0.tar.gz
解壓安裝包:
tar –xvf redis-5.0.0.tar.gz
編譯(在解壓的目錄中執行):
make
安裝(在解壓的目錄中執行):
make install
(2)redis相關命令
redis-server,伺服器啟動命令 客戶端啟動命令
redis-cli,redis核心配置檔案
redis.conf,RDB檔案檢查工具(快照持久化檔案)
redis-check-dump,AOF檔案修復工具
redis-check-aof
1.3.2 window版本的redis安裝
-
資料中找到“Redis-x64-3.2.100.msi”
-
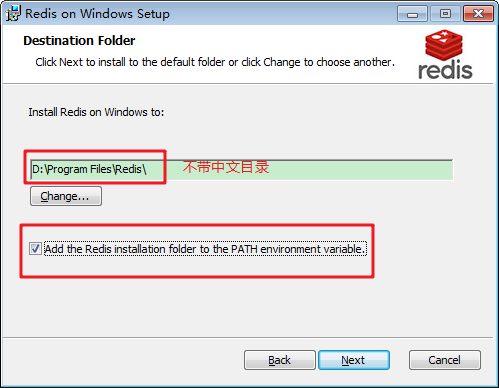
雙擊進行安裝:選擇目錄,勾選新增環境變數
-
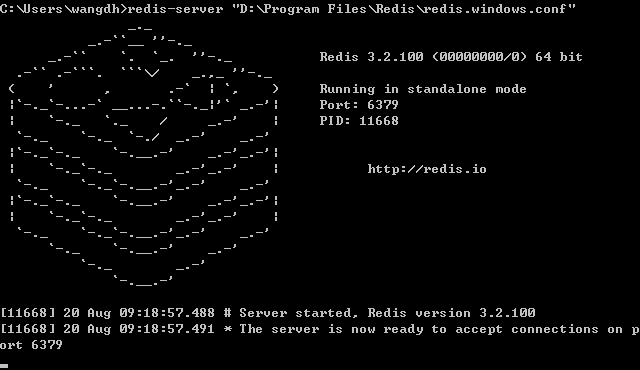
開啟cmd:執行redis-server "D:\Program Files\Redis\redis.windows.conf"
-
出現Server started即可
-
注意:這個視窗不可關閉,一旦關閉redis服務將停止
-
-
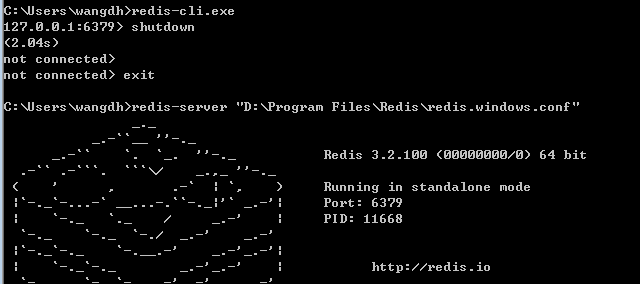
沒有出現上述圖片,而是報錯:“ listening socket 127.0.0.1:6379: bind: No error ”

-
解決
-
客戶端連線redis服務:如能出現如下效果即說明redis服務真正啟動成功

1.3.3 通過圖形化客戶端連線
-
找到資料:“redis-desktop-manager-0.8.8.384.exe”
-
雙擊安裝,預設安裝即可
-
雙擊桌面“RedisDesktopManager”圖示,開啟redis桌面管理工具
-
建立連線

-
輸入連線內容:
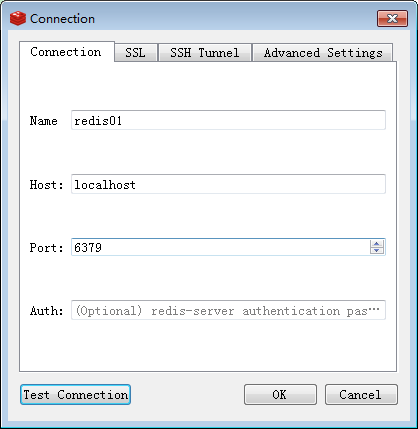
-
左側出現連線

-
雙擊連線:出現redis預設的15個庫
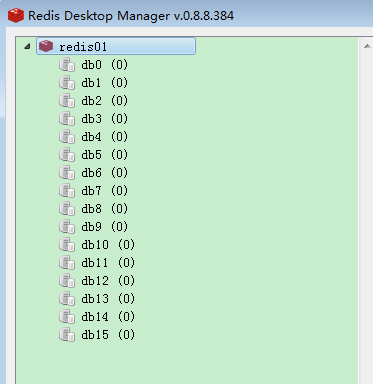
-
到此為止,說明圖形化客戶端連線redis服務成功
1.4 Redis伺服器啟動
1.4.1 Redis伺服器啟動
啟動伺服器——引數啟動
redis-server [--port port]
範例
redis-server --port 6379
啟動伺服器——配置檔案啟動
redis-server config_file_name
範例
redis-server redis.conf
1.4.2 Redis客戶端啟動
啟動客戶端
redis-cli [-h host] [-p port]
範例
redis-cli –h 61.129.65.248 –p 6384
注意:伺服器啟動指定埠使用的是--port,客戶端啟動指定埠使用的是-p。-的數量也不同。
1.4.3 Redis基礎環境設定約定
建立配置檔案儲存目錄
mkdir conf
建立伺服器檔案儲存目錄(包含日誌、資料、臨時配置檔案等)
mkdir data
建立快速訪問連結
ln -s redis-5.0.0 redis
1.5 配置檔案啟動與常用配置
1.5.1 伺服器端設定
-
修改啟動配置檔案redis.conf/redis.windows.conf

-
配置項介紹:
-
設定伺服器以守護程序的方式執行,開啟後伺服器控制檯中將列印伺服器執行資訊(同日志內容相同)
daemonize yes|no # 改為yes就是後臺啟動,看不到之前的歡迎資訊,cmd視窗關閉也沒影響
#windows版本的redis不支援後臺啟動,配置也沒有用 -
繫結主機地址:bind ip
bind 127.0.0.1 #指定當前redis服務執行在哪個ip上(一般都指定為本機)
-
設定伺服器埠
port 6379 #6379是redis的預設埠
-
日誌檔案
logfile "日誌檔名"
-
設定伺服器檔案儲存地址:dir path
dir "/redis/data"
windows配置為:dir "./data"(需要在redis安裝的目錄新建data資料夾)
-
-
啟動

-
配置為後臺啟動之後,可以通過ps檢視是否啟動
-
-
開發的時候,我們還是通過前臺啟動,因為檢視日誌方便
-
殺掉程序:kill 9 6457
-
重新配置daemonize no
-
遮蔽logfile (如果不遮蔽,日誌還是會寫入日誌檔案,不會直接在cmd視窗顯示)
-
1.5.2 客戶端配置(瞭解,還是redis.conf配置檔案中的配置項)
伺服器允許客戶端連線最大數量,預設0,表示無限制。當客戶端連線到達上限後,Redis會拒絕新的連線
maxclients count
客戶端閒置等待最大時長,達到最大值後關閉對應連線。如需關閉該功能,設定為 0
timeout seconds
1.5.3 日誌配置
設定伺服器以指定日誌記錄級別
loglevel debug|verbose|notice|warning
日誌記錄檔名
logfile filename
注意:日誌級別開發期設定為verbose即可,生產環境中配置為notice,簡化日誌輸出量,降低寫日誌IO的頻度。
1.6 Redis基本操作
1.6.1 命令列模式工具使用思考
我們需要會以下操作:
-
功能性命令
-
幫助資訊查閱
-
退出指令
-
清除螢幕資訊
1.6.2 資訊讀寫
設定 key,value 資料
set key value
範例
set name itheima
根據 key 查詢對應的 value,如果不存在,返回空(nil)
get key
範例
get name
1.6.3 幫助資訊
獲取命令幫助文件
help [command]
範例
help set
獲取組中所有命令資訊名稱
help [@group-name]
範例
help @string
1.6.4 退出命令列客戶端模式
退出客戶端
quit 或 exit
快捷鍵
Ctrl+C
1.6.4 redis入門總結
到這裡,Redis 入門的相關知識,我們就全部學習完了,再來回顧一下,這個部分我們主要講解了哪些內容呢?
-
首先,我們對Redis進行了一個簡單介紹,包括NoSQL的概念、Redis的概念等
-
然後,我們介紹了Redis 的下載與安裝。包括下載與安裝、伺服器與客戶端啟動、以及相關配置檔案(3類)
-
最後,我們介紹了Redis 的基本操作。包括資料讀寫、退出與幫助資訊獲取
2. 資料型別
在這個部分,我們將學習一共要學習三大塊內容:
-
首先需要了解一下資料型別
-
接下來將針對著我們要學習的資料型別進行逐一的講解,如string、hash、list、set等
-
最後我們通過一個案例來總結前面的資料型別的使用場景
2.1 資料儲存型別介紹
2.1.1 業務資料的特殊性
在講解資料型別之前,我們得先思考一個問題,資料型別既然是用來描述資料的儲存格式的,如果你不知道哪些資料未來會進入到我們來的redis中,那麼對應的資料型別的選擇,你就會出現問題,我們一塊來看一下:
(1)原始業務功能設計
秒殺。他這個裡邊資料變化速度特別的快,訪問量也特別的高,使用者大量湧入以後都會針對著一部分資料進行操作,這一類要記住。
618活動。對於我們京東的618活動、以及天貓的雙11活動,相信大家不用說都知道這些資料一定要進去,因為他們的訪問頻度實在太高了。
排隊購票。我們12306的票務資訊。這些資訊在原始設計的時候,他們就註定了要進redis。
(2)運營平臺監控到的突發高頻訪問資料
此類平臺臨時監控到的這些資料,比如說現在出來的一個八卦的資訊,這個新聞一旦出現以後呢,順速的被圍觀了,那麼這個時候,這個資料就會變得訪量特別高,那麼這類資訊也要進入進去。
(3)高頻、複雜的統計資料
線上人數。比如說直播現在很火,直播裡邊有很多資料,例如線上人數。進一個人出一個人,這個資料就要跳動,那麼這個訪問速度非常的快,而且訪量很高,並且它裡邊有一個複雜的資料統計,在這裡這種資訊也要進入到我們的redis中。
投票排行榜。投票投票類的資訊他的變化速度也比較快,為了追求一個更快的一個即時投票的名次變化,這種資料最好也放到redis中。
2.1.2 Redis 資料型別(5種常用)
基於以上資料特徵我們進行分析,最終得出來我們的Redis中要設計5種 資料型別:
string、hash、list、set、sorted_set/zset(應用性較低)
2.2 string資料型別
在學習第一個資料型別之前,先給大家介紹一下,在隨後這部分內容的學習過程中,我們每一種資料型別都分成三塊來講:
-
首先是講下它的基本操作
-
接下來講一些它的擴充套件操作
-
最後我們會去做一個小的案例分析
2.2.1Redis 資料儲存格式
-
在學習string這個資料形式之前,我們先要明白string到底是修飾什麼的
-
我們知道redis 自身是一個 Map,其中所有的資料都是採用 key : value 的形式儲存
-
對於這種結構來說,我們用來儲存資料一定是一個值前面對應一個名稱,我們通過名稱來訪問後面的值。
-
前面這一部分我們稱為key,後面的一部分稱為value,而我們的資料型別,他一定是修飾value的。

資料型別指的是儲存的資料的型別,也就是 value 部分的型別,key 部分永遠都是字串。
2.2.2 string 型別
(1)儲存的資料:單個數據,最簡單的資料儲存型別,也是最常用的資料儲存型別。
string,他就是存一個字串兒,注意是value那一部分是一個字串,它是redis中最基本、最簡單的儲存資料的格式。
(2)儲存資料的格式:一個儲存空間儲存一個數據
每一個空間中只能儲存一個字串資訊,這個資訊裡邊如果是存的純數字,他也能當數字使用,我們來看一下,這是我們的資料的儲存空間。
(3)儲存內容:通常使用字串,如果字串以整數的形式展示,可以作為數字操作使用.

一個key對一個value,而這個itheima就是我們所說的string型別,當然它也可以是一個純數字的格式。
2.2.3 string 型別資料的基本操作
(1)基礎指令
新增/修改資料新增/修改資料
set key value
獲取資料
get key
刪除資料
del key
判定性新增資料 (瞭解)
setnx key value #SET if Not eXists (大寫組成命令)
新增/修改多個數據
mset key1 value1 key2 value2 … #m:Multiple 多個 many
獲取多個數據
mget key1 key2 …
獲取資料字元個數(字串長度)
strlen key #STRing LENgth
追加資訊到原始資訊後部(如果原始資訊存在就追加,否則新建)
append key value
演示:


(2)單資料操作與多資料操作的選擇之惑
即set 與mset的關係。這對於這兩個操作來說,沒有什麼你應該選哪個,而是他們自己的特徵是什麼,你要根據這個特徵去比對你的業務,看看究竟適用於哪個。

假如說這是我們現在的伺服器,他要向redis要資料的話,它會發出一條指令。那麼當這條指令發過來的時候,比如說是這個set指令過來,那麼它會把這個結果返回給你,這個時候我們要思考這裡邊一共經過了多長時間。
首先,傳送set指令要時間,這是網路的一個時間,接下來redis要去執行這個指令要消耗時間,最終把這個結果返回給你又有一個時間,這個時間又是一個網路的時間,那我們可以理解為:一個指令傳送的過程中需要消耗這樣的時間.
但是如果說現在不是一條指令了,你要發3個set的話,還要多長時間呢?對應的傳送時間要乘3了,因為這是三個單條指令,而執行的操作時間呢,它也要乘3了,但最終返回的也要發3次,所以這邊也要乘3。
於是我們可以得到一個結論:單指令發3條它需要的時間,假定他們兩個一樣,是6個網路時間加3個處理時間,如果我們把它合成一個mset呢,我們想一想。
假如說用多指令發3個指令的話,其實只需要發一次就行了。這樣我們可以得到一個結論,多指令發3個指令的話,其實它是兩個網路時間加上3個redis的操作時間,為什麼這寫一個小加號呢,就是因為畢竟發的資訊量變大了,所以網路時間有可能會變長。
那麼通過這張圖,你就可以得到一個結論,我們單指令和多指令他們的差別就在於你傳送的次數是多還是少。當你影響的資料比較少的時候,你可以用單指令,也可以用多指令。但是一旦這個量大了,你就要選擇多指令了,他的效率會高一些。
2.3 string 型別資料的擴充套件操作
2.3.1 string 型別資料的擴充套件操作
下面我們來看一string的擴充套件操作,分成兩大塊:一塊是對數字進行操作的,第二塊是對我們的key的時間進行操作的。
設定數值資料增加指定範圍的值
incr key #類似於i++ incrby key increment #相當於i+n incrbyfloat key increment #可以操作小數 #increment 增加
設定數值資料減少指定範圍的值
decr key #類似於i-- decrby key increment #相當於i-n #decrement 減少
設定資料具有指定的生命週期 (***)
setex key seconds value *** psetex key milliseconds value #expire : 有效期,期限
演示:
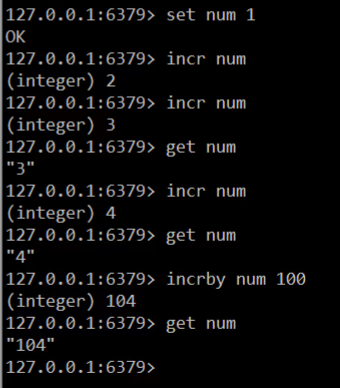
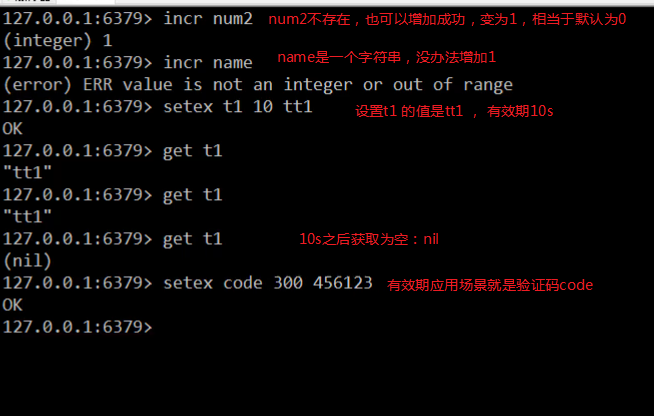
2.3.2 string 型別資料操作的注意事項
-
資料操作不成功的反饋與資料正常操作之間的差異
表示執行結果是否成功 : 例如setnx
(integer) 0 → false 失敗
(integer) 1 → true 成功
表示執行結果值:例如獲取資料長度 strlen
(integer) 3 → 3 3個
(integer) 1 → 1 1個
-
資料未獲取到時,對應的資料為(nil),等同於null
-
資料最大儲存量:512MB
-
string在redis內部儲存預設就是一個字串,當遇到增減類操作incr,decr時會轉成數值型進行計算
-
注意:redis雖然可以儲存數字,但是數字在內部儲存時依然是字串型別
-
-
按數值進行操作的資料,如果原始資料不能轉成數值,或超越了redis 數值上限範圍,將報錯
上限是:9223372036854775807(也就是java中Long型資料最大值,Long.MAX_VALUE)
-
redis所有的操作都是原子性的,採用單執行緒處理所有業務,命令是一個一個執行的,因此無需考慮併發帶來的資料影響.
2.4string應用場景與key命名約定
2.4.1 應用場景
它的應用場景在於:主頁高頻訪問資訊顯示控制,例如新浪微博大V主頁顯示粉絲數與微博數量。

我們來思考一下:這些資訊是不是你進入大V的頁面兒以後就要讀取這寫資訊的啊,那這種資訊一定要儲存到我們的redis中,因為他的訪問量太高了!那這種資料應該怎麼存呢?我們來一塊兒看一下方案!
2.4.2 解決方案
(1)在redis中為大V使用者設定使用者資訊,以使用者主鍵和屬性值作為key,後臺設定定時重新整理策略即可。
eg: user:id:3506728370:fans → 12210947 eg: user:id:3506728370:blogs → 6164 eg: user:id:3506728370:focuses → 83 #eg就是例子的意思
演示:

-
這個使用者的id為123456,這個大v儲存了blogs和fans倆資訊,分開儲存
(2)也可以使用json格式儲存資料
eg: user:id:3506728370 → {“fans”:12210947,“blogs”:6164,“ focuses ”:83 }
(3) key 的設定約定
資料庫中的熱點資料key命名慣例:由表名:主鍵名:主鍵值:欄位名,作為key名
| 表名 | 主鍵名 | 主鍵值 | 欄位名 | |
|---|---|---|---|---|
| eg1: | order | id | 29437595 | name |
| eg2: | equip | id | 390472345 | type |
| eg3: | news | id | 202004150 | title |
2.5 hash的基本操作
下面我們來學習第二個資料型別hash
2.5.1 資料儲存的困惑
物件類資料的儲存如果具有較頻繁的更新需求操作會顯得笨重!
在正式學習之前,我們先來看一個關於資料儲存的困惑:

-
比如說前面我們用以上形式存了資料,如果我們用單條去存的話,它存的條數會很多。
-
但如果我們用json格式,它存一條資料就夠了。
-
問題來了,假如說現在粉絲數量發生變化了,你要把整個值都改了。
-
但是用單條存的話就不存在這個問題,你只需要改其中一個就行了。
-
這個時候我們就想,有沒有一種新的儲存結構,能幫我們解決這個問題呢。
我們一塊兒來分析一下:

-
如上圖所示:單條的話是對應的資料在後面放著。
-
仔細觀察:我們看左邊是不是長得都一模一樣啊,都是對應的表名、ID等的一系列的東西。
-
我們可以將右邊紅框中的這個區域給他封起來。
那如果要是這樣的形式的話,如下圖,我們把它一合併,並把右邊的東西給他變成這個格式,這不就行了嗎?

這個圖其實大家並不陌生:
-
第一,你前面學過一個東西叫hashmap不就這格式嗎?
-
第二,redis自身不也是這格式嗎?那是什麼意思呢?
-
注意,這就是我們要講的第二種格式,hash。

在右邊對應的值,我們就存具體的值,那左邊兒這就是我們的key。
問題來了,那中間的這一塊叫什麼呢?這個東西我們給他起個名兒,叫做field欄位。
那麼右邊兒整體這塊兒空間我們就稱為hash,也就是說hash是存了一個key value的儲存空間。
-
總結:
-
hash的結構是:key:{field:value,field2:value2}
-
在redis中的hash的值,可以理解為是一個物件
-
2.5.2 hash 型別
新的儲存需求:對一系列儲存的資料進行編組,方便管理,典型應用儲存物件資訊
需要的儲存結構:一個儲存空間儲存多個鍵值對資料
hash型別:底層使用雜湊表結構實現資料儲存

如上圖所示,這種結構叫做hash,左邊一個key,對右邊一個儲存空間。這裡要明確一點,右邊這塊兒儲存空間叫hash,也就是說hash是指的一個數據型別,他指的不是一個數據,是這裡邊的一堆資料,那麼它底層呢,是用hash表的結構來實現的。
值得注意的是:
如果field數量較少,儲存結構優化為類陣列結構
如果field數量較多,儲存結構使用HashMap結構
2.5.3 hash 型別資料的基本操作
新增/修改資料
hset key field value #h:hash
獲取資料
hget key field hgetall key
刪除資料
hdel key field1 [field2] #可以刪除多個field,空格分隔即可
設定field的值,如果該field存在則不做任何操作
hsetnx key field value
新增/修改多個數據
hmset key field1 value1 field2 value2 …
獲取多個數據
hmget key field1 field2 …
獲取雜湊表中欄位的數量
hlen key
獲取雜湊表中是否存在指定的欄位
hexists key field
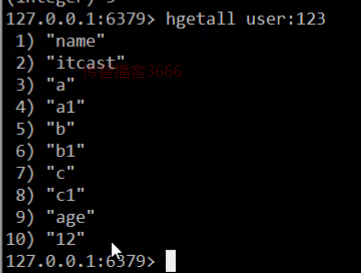
演示:hash的key是user:123
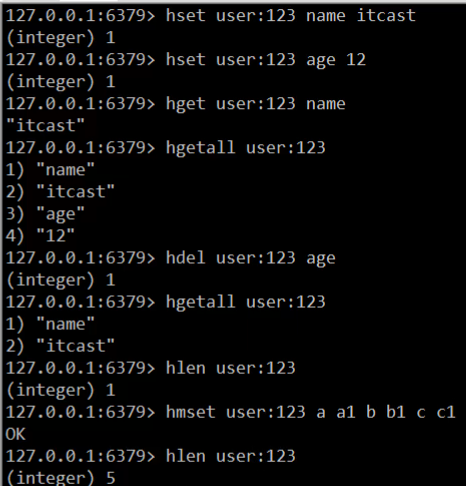
-
這裡刪除了一個還剩下一個,又增加3個,按理說長度應該是4的。這裡缺顯示的是5,這個可能是老師對視訊截圖之後出的問題·
2.6 hash的拓展操作
在看完hash的基本操作後,我們再來看他的拓展操作,他的拓展操作相對比較簡單:
2.6.1 hash 型別資料擴充套件操作
獲取雜湊表中所有的欄位名或欄位值
hkeys key hvals key
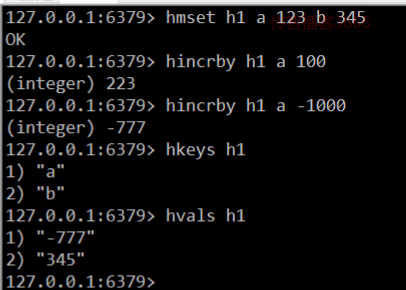
設定指定欄位的數值資料增加指定範圍的值
hincrby key field increment hincrbyfloat key field increment
演示:
2.6.2 hash型別資料操作的注意事項
-
(1)hash型別中value只能儲存字串,不允許儲存其他資料型別,不存在巢狀現象。如果資料未獲取到,對應的值為(nil)
-
(2)每個 hash 可以儲存 (2的32次方 - 1) 個鍵值對
-
(3)hash型別十分貼近物件的資料儲存形式,並且可以靈活新增刪除物件屬性。但hash設計初衷不是為了儲存大量物件而設計 的,切記不可濫用,更不可以將hash作為物件列表使用
-
(4)hgetall 操作可以獲取全部屬性,如果內部field過多,遍歷整體資料效率就很會低,有可能成為資料訪問瓶頸
2.7 hash應用場景
2.7.1 應用場景
雙11活動日,銷售手機充值卡的商家對移動、聯通、電信的30元、50元、100元商品推出搶購活動,每種商品搶購上限1000 張。

也就是商家有了,商品有了,數量有了。最終我們的使用者買東西就是在改變這個數量。那你說這個結構應該怎麼存呢?對應的商家的ID作為key,然後這些充值卡的ID作為field,最後這些數量作為value。而我們所謂的操作是其實就是increa這個操作,只不過你傳負值就行了。看一看對應的解決方案。
2.7.2 解決方案
以商家id作為key
將參與搶購的商品id作為field
將參與搶購的商品數量作為對應的value
搶購時使用降值的方式控制產品數量
注意:實際業務中還有超賣等實際問題,這裡不做討論
演示:

2.8 list基本操作
-
前面我們存資料的時候呢,單個數據也能存,多個數據也能存
-
但是這裡面有一個問題,我們存多個數據用hash的時候它是沒有順序的
-
我們平時操作,實際上資料很多情況下都是有順序的,那有沒有一種能夠用來儲存帶有順序的這種資料模型呢
-
list就專門來幹這事兒
2.8.1 list 型別
資料儲存需求:儲存多個數據,並對資料進入儲存空間的順序進行區分
需要的儲存結構:一個儲存空間儲存多個數據,且通過資料可以體現進入順序
list型別:儲存多個數據,底層使用雙向連結串列儲存結構實現
先來通過一張圖,回憶一下順序表、連結串列、雙向連結串列。
-
下圖為將cnpc插入前的圖示

-
下圖為將cnpn插入後的圖示

-
順序表:想要插入cnpc,需要將後邊的元素都向後移動,比較麻煩
-
連結串列:想要插入cnpc,需要將頭指標和huawei的鏈條斷開,然後重新連線
-
連結串列的形式,插入挺高效,就是查詢比較慢,如果要查詢alibaba,就需要從頭查到尾
-
-
雙向連結串列:它的鏈條是雙向的
-
想要插入cnpc,也是需要斷開頭指標和華為的鏈條,重新連線,所以插入也高效
-
但是查詢也是高效的,查詢可以雙向查詢
-
雖然查詢alibaba也是從頭開始查詢,但是如果這時再查詢tencent,就可以反向直接查詢到
-
-
list對應的儲存結構是什麼呢?裡邊存的這個東西是個列表,他有一個對應的名稱。
就是key存一個list的這樣結構。對應的基本操作,你其實是可以想到的。
來看一下,因為它是雙向的,所以他左邊右邊都能操作,它對應的操作結構兩邊都能進資料。這就是連結串列的一個儲存結構。
往外拿資料的時候怎麼拿呢?通常是從一端拿,當然另一端也能拿。
如果兩端都能拿的話,這就是個雙端佇列,兩邊兒都能操作。如果只能從一端進一端出,這個模型咱們前面瞭解過,叫做棧。
lpush,rpush,lrange
佇列(排隊),先進先出
棧堆:摞(摞東西),先進後出
2.8.2 list 型別資料基本操作
最後看一下他的基本操作
新增/修改資料
lpush key value1 [value2] …… rpush key value1 [value2] …… #l:left #r:right
獲取資料:因為列表儲存的資料有順序,所以可以通過索引來獲取
lrange key start stop # range:範圍,查詢某個範圍的資料。stop如果寫-1,意味著直接查詢所有 lindex key index #index:索引,查詢某個索引的資料 llen key
獲取並移除資料:刪除之後會返回被刪除的資料
lpop key #左側刪除末尾資料(刪除最左側的資料) rpop key #右側刪除末尾資料(刪除最右側的資料)
演示:
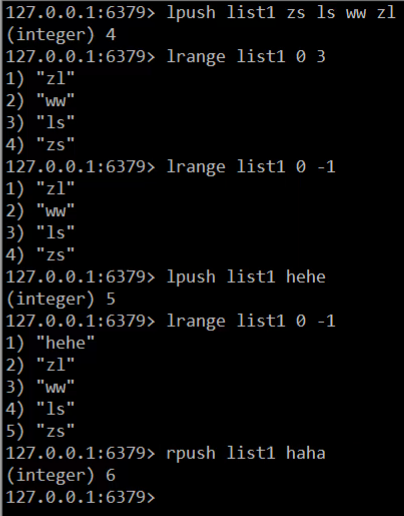
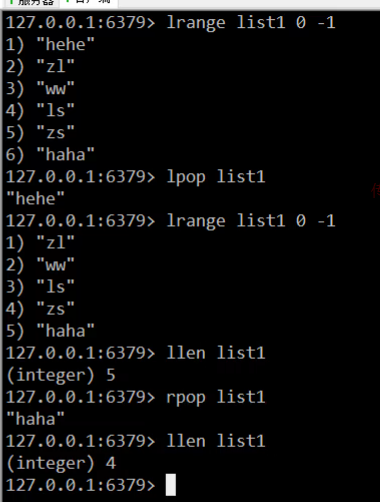
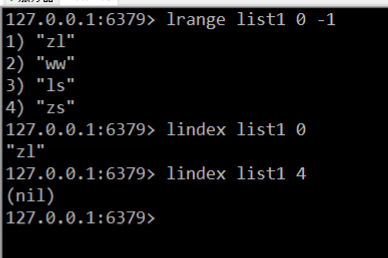
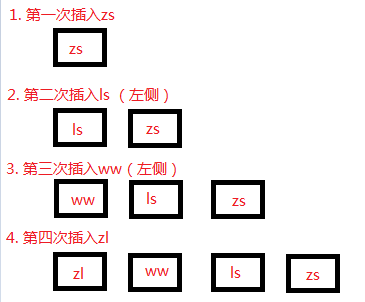
分析:
2.9 list擴充套件操作
2.9.1 list 型別資料擴充套件操作
移除指定資料:不返回刪除的資料
lrem key count value #rem remove移除 #count 可以刪除多個,如果list中儲存了倆a,就可以是 lrem list1 2 a
規定時間內獲取並移除資料:規定時間內取資料,能取到就返回,取不到就返回nil
blpop key1 [key2] timeout brpop key1 [key2] timeout brpoplpush source destination timeout #b:block:阻塞,塊
演示:




2.9.2 list 型別資料操作注意事項
(1)list中儲存的資料都是string型別的,資料總容量是有限的,最多 (2的32次方- 1) 個元素(4294967295)。
(2)list具有索引的概念,但是操作資料時通常以佇列的形式進行入隊出隊操作,或以棧的形式進行入棧出棧操作
(3)獲取全部資料操作結束索引設定為-1
(4)list可以對資料進行分頁操作,通常第一頁的資訊來自於list,第2頁及更多的資訊通過資料庫的形式載入
2.10 list 應用場景
2.10.1 應用場景
企業運營過程中,系統將產生出大量的運營資料,如何保障多臺伺服器操作日誌的統一順序輸出?

假如現在你有多臺伺服器,每一臺伺服器都會產生它的日誌,假設你是一個運維人員,你想看它的操作日誌,你怎麼看呢?開啟A機器的日誌看一看,開啟B機器的日誌再看一看嗎?這樣的話你會可能會瘋掉的!因為左邊看的有可能它的時間是11:01,右邊11:02,然後再看左邊11:03,它們本身是連續的,但是你在看的時候就分成四個檔案了,這個時候你看起來就會很麻煩。能不能把他們合併呢?答案是可以的!怎麼做呢?建立起redis伺服器。當他們需要記日誌的時候,記在哪兒,全部發給redis。等到你想看的時候,通過伺服器訪問redis獲取日誌。然後得到以後,就會得到一個完整的日誌資訊。那麼這裡面就可以獲取到完整的日誌了,依靠什麼來實現呢?就依靠我們的list的模型的順序來實現。進來一組資料就往裡加,誰先進來誰先加進去,它是有一定的順序的。
2.10.2 解決方案
依賴list的資料具有順序的特徵對資訊進行管理
使用佇列模型解決多路資訊彙總合併的問題
使用棧模型解決最新訊息的問題
演示:

-
先進先出,就用rpush放入,lrange取出即可
2.11 set 基本操作
2.11.1 set型別
新的儲存需求:儲存大量的資料,在查詢方面提供更高的效率
需要的儲存結構:能夠儲存大量的資料,高效的內部儲存機制,便於查詢
set型別:與hash儲存結構完全相同,僅儲存field,不儲存值(儲存的值都是nil),並且field是不允許重複的

通過這個名稱,大家也基本上能夠認識到和我們Java中的set完全一樣。我們現在要儲存大量的資料,並且要求提高它的查詢效率。用list這種連結串列形式,它的查詢效率是不高的,那怎麼辦呢?這時候我們就想,有沒有高效的儲存機制。其實前面咱講Java的時候說