
任務佇列 與 Celery概述
阿新 • • 發佈:2021-03-08
## 一、任務佇列(Task Queues)
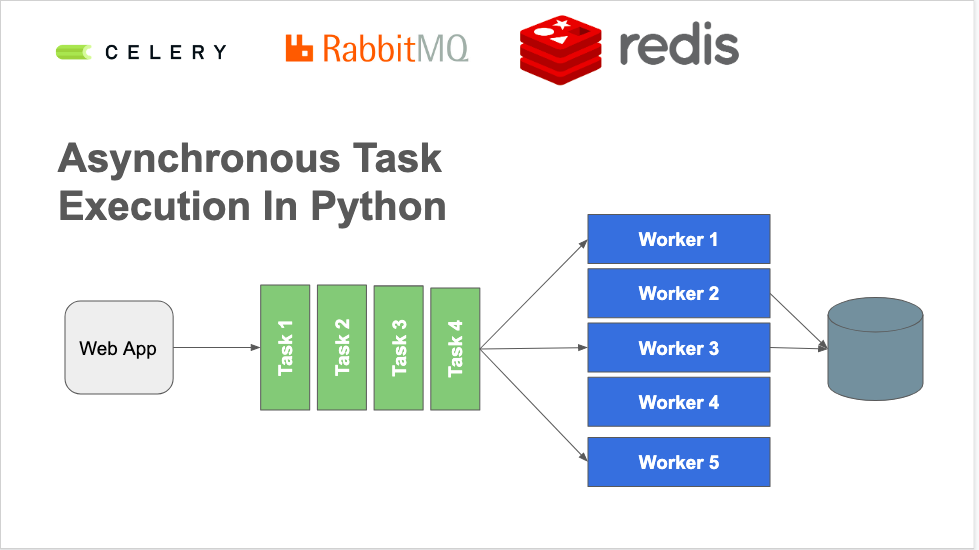
### 1.1 什麼是任務佇列? 任務佇列用於管理後臺工作,通常這些後臺工作必須在 HTTP請求-響應迴圈 之外執行。
### 1.2 為什麼需要任務佇列? 對於那些不是由客戶端HTTP請求產生的任務,或是需要長時間執行的作業,會大大降低HTTP響應的效能,所以這些請求需要非同步處理。 **示例一:**一個Web應用程式可以每10分鐘輪詢一次GitHub API,以收集前100個加星標儲存庫的名稱。任務佇列將處理呼叫程式碼以呼叫GitHub API、處理結果、並將其儲存在持久資料庫中以供以後使用。 **示例二:**在HTTP請求-響應週期內資料庫查詢花費的時間太長時。查詢可以在後臺以固定間隔執行,結果儲存在資料庫中。當收到一個需要這些結果的HTTP請求時,查詢將簡單地獲取預先計算的結果,而不是重新執行較長的查詢。這種預計算方案是任務佇列啟用的一種[快取](https://www.fullstackpython.com/caching.html)形式。 任務佇列的其他型別的作業包括 - 隨著時間的流逝散佈大量獨立的資料庫插入,而不是一次插入所有內容 - 以固定的時間間隔(例如每15分鐘)聚合收集的資料值 - 安排諸如批處理之類的定期作業
### 1.2 常用的任務佇列 事實上的標準Python任務佇列是[**Celery**](https://www.fullstackpython.com/celery.html)。其他任務佇列專案的出現,主要是因為對於簡單的使用場景而言Clelery還是有點繁瑣。所以重點還是在Celery。 此外還可以使用**第三方的任務佇列服務**,用於解決在大規模部署分散式任務佇列時出現的複雜問題。

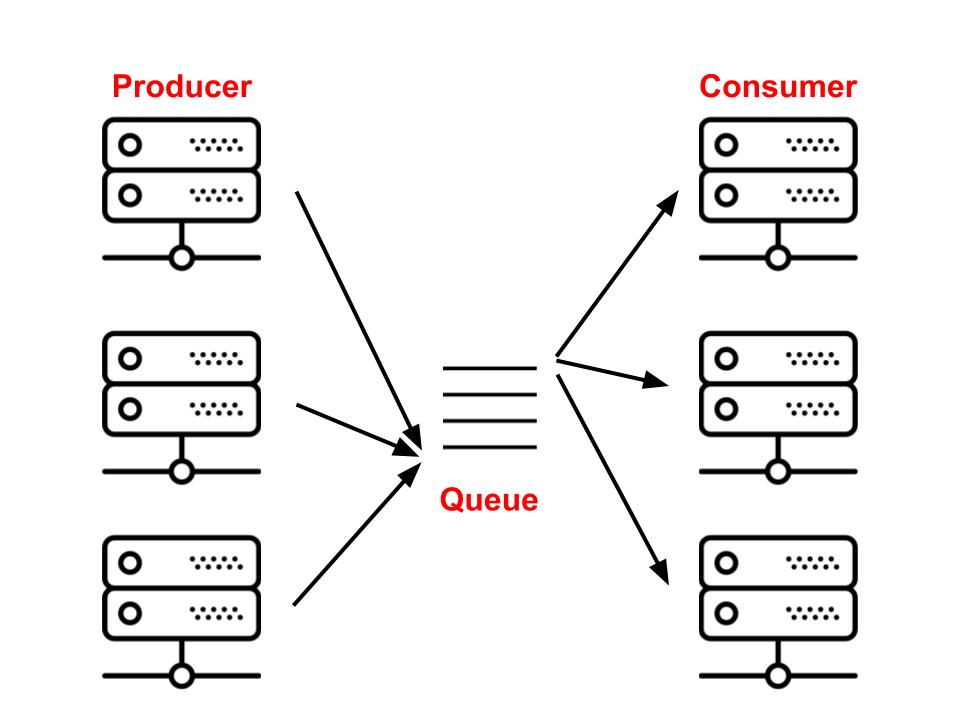
### 2.1 Broker broker也常譯為中間人,其實就是一個佇列。但是在計算機系統中實現一個佇列的方法有很多。最簡單的方式就是使用文字檔案。文字檔案可以包含要執行的一系列工作描述,因此,我們可以將它們用作系統的代理。文字檔案的問題在於它們不能處理實際的應用程式問題,例如網路和併發訪問。因此,我們需要更強大的功能。 另一方面,SQL資料庫能夠在網路中執行並處理併發訪問。它們的問題在於它們太慢。相比之下,NoSQL資料庫的速度相當快,但是很多時候它們缺乏可靠性。 因此,在構建佇列時,我們應該使用快速,可靠,併發啟用的工具,例如[RabbitMQ](https://www.rabbitmq.com/),[Redis](https://redis.io/)和[SQS](https://aws.amazon.com/pt/sqs/)。 Celery完全支援RabbitMQ和Redis。儘管也可以使用SQS和[Zookeeper](https://zookeeper.apache.org/),但它們提供的功能有限。
### 2.2 Web節點 和 Workers web節點和workers都是普通的伺服器,他們的不同僅僅是:web節點接收客戶端請求,然後釋出需要非同步處理的任務;而workers所在的伺服器接收這些任務,執行並提供反饋。 儘管他們的執行邏輯不同,但一般這兩者的程式碼都放在同一個伺服器的專案中,這樣做兩個應用程式都可以受益於共享模型和服務之類的東西,還可以防止這些模型和服務不一致。
### 2.3 執行一個非同步任務 ``` # worker node: from celery import Celery app = Celery(...) @app.task def add(a, b): return a + b ``` ``` # web node: from tasks import add r = add.delay(4, 5).get() print(r) # 9 ``` 上面分別是 **非同步任務需要執行的程式碼** 和 **將作業放置在要執行的佇列中的程式碼**。在此示例中,Web節點放置一個作業,並等待直到結果可用。響應的結果到來後,將列印結果。
### 2.4 Results Backend 在前面的示例中,我們將一起呼叫`delay`和`get`函式。實際上,它們是兩個獨立的事物。`delay`將任務放在佇列中並返回一個promise,該promise可用於監視狀態並在準備就緒時獲取結果。呼叫`get`該promise將阻塞執行(block the execution),直到結果可用為止。 這個`add`任務必須將結果儲存在某個位置,以便隨後觸發它的程序可以對其進行訪問。這意味著我們錯過了一部分架構。除了`web`,`broker`和`worker`元件,還有一個`results backend`。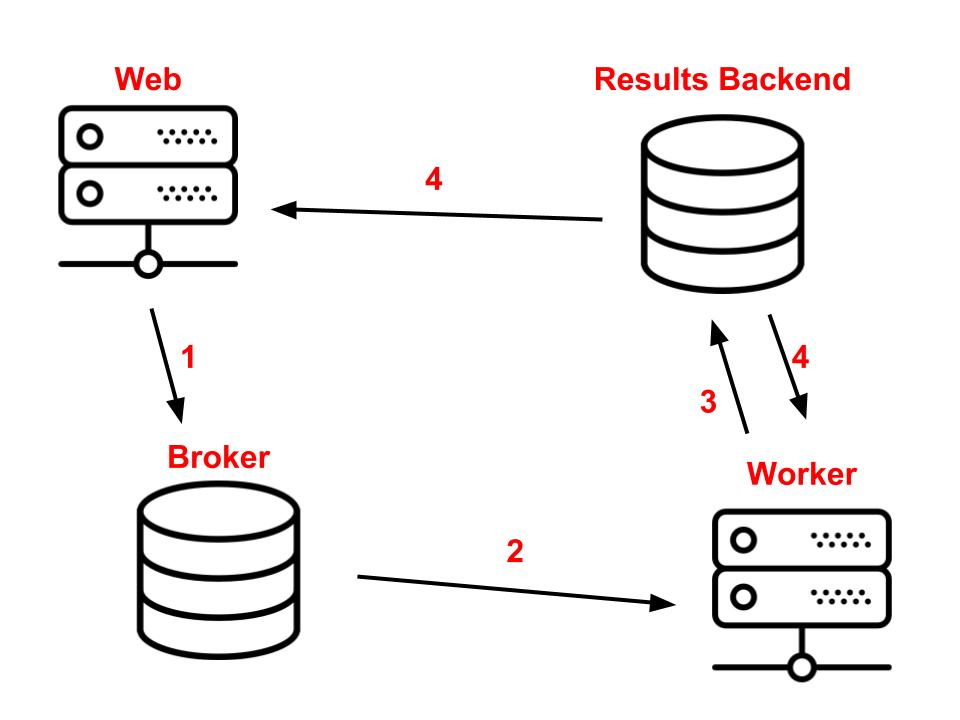
## 參考 - [Celery](https://www.fullstackpython.com/celery.html) - [Task Queue](https://www.fullstackpython.com/task-queues.html) - [Celery: an overview of the architecture and how it works](https://www.vinta.com.br/blog/2017/celery-overview-archtecture-and-how-it-works/) - [asynchronous-task-execution-in-python](https://bhavaniravi.com/blog/asynchronous-task-execution-in-
### 1.1 什麼是任務佇列? 任務佇列用於管理後臺工作,通常這些後臺工作必須在 HTTP請求-響應迴圈 之外執行。
### 1.2 為什麼需要任務佇列? 對於那些不是由客戶端HTTP請求產生的任務,或是需要長時間執行的作業,會大大降低HTTP響應的效能,所以這些請求需要非同步處理。 **示例一:**一個Web應用程式可以每10分鐘輪詢一次GitHub API,以收集前100個加星標儲存庫的名稱。任務佇列將處理呼叫程式碼以呼叫GitHub API、處理結果、並將其儲存在持久資料庫中以供以後使用。 **示例二:**在HTTP請求-響應週期內資料庫查詢花費的時間太長時。查詢可以在後臺以固定間隔執行,結果儲存在資料庫中。當收到一個需要這些結果的HTTP請求時,查詢將簡單地獲取預先計算的結果,而不是重新執行較長的查詢。這種預計算方案是任務佇列啟用的一種[快取](https://www.fullstackpython.com/caching.html)形式。 任務佇列的其他型別的作業包括 - 隨著時間的流逝散佈大量獨立的資料庫插入,而不是一次插入所有內容 - 以固定的時間間隔(例如每15分鐘)聚合收集的資料值 - 安排諸如批處理之類的定期作業
### 1.2 常用的任務佇列 事實上的標準Python任務佇列是[**Celery**](https://www.fullstackpython.com/celery.html)。其他任務佇列專案的出現,主要是因為對於簡單的使用場景而言Clelery還是有點繁瑣。所以重點還是在Celery。 此外還可以使用**第三方的任務佇列服務**,用於解決在大規模部署分散式任務佇列時出現的複雜問題。
### 2.1 Broker broker也常譯為中間人,其實就是一個佇列。但是在計算機系統中實現一個佇列的方法有很多。最簡單的方式就是使用文字檔案。文字檔案可以包含要執行的一系列工作描述,因此,我們可以將它們用作系統的代理。文字檔案的問題在於它們不能處理實際的應用程式問題,例如網路和併發訪問。因此,我們需要更強大的功能。 另一方面,SQL資料庫能夠在網路中執行並處理併發訪問。它們的問題在於它們太慢。相比之下,NoSQL資料庫的速度相當快,但是很多時候它們缺乏可靠性。 因此,在構建佇列時,我們應該使用快速,可靠,併發啟用的工具,例如[RabbitMQ](https://www.rabbitmq.com/),[Redis](https://redis.io/)和[SQS](https://aws.amazon.com/pt/sqs/)。 Celery完全支援RabbitMQ和Redis。儘管也可以使用SQS和[Zookeeper](https://zookeeper.apache.org/),但它們提供的功能有限。
### 2.2 Web節點 和 Workers web節點和workers都是普通的伺服器,他們的不同僅僅是:web節點接收客戶端請求,然後釋出需要非同步處理的任務;而workers所在的伺服器接收這些任務,執行並提供反饋。 儘管他們的執行邏輯不同,但一般這兩者的程式碼都放在同一個伺服器的專案中,這樣做兩個應用程式都可以受益於共享模型和服務之類的東西,還可以防止這些模型和服務不一致。
### 2.3 執行一個非同步任務 ``` # worker node: from celery import Celery app = Celery(...) @app.task def add(a, b): return a + b ``` ``` # web node: from tasks import add r = add.delay(4, 5).get() print(r) # 9 ``` 上面分別是 **非同步任務需要執行的程式碼** 和 **將作業放置在要執行的佇列中的程式碼**。在此示例中,Web節點放置一個作業,並等待直到結果可用。響應的結果到來後,將列印結果。
### 2.4 Results Backend 在前面的示例中,我們將一起呼叫`delay`和`get`函式。實際上,它們是兩個獨立的事物。`delay`將任務放在佇列中並返回一個promise,該promise可用於監視狀態並在準備就緒時獲取結果。呼叫`get`該promise將阻塞執行(block the execution),直到結果可用為止。 這個`add`任務必須將結果儲存在某個位置,以便隨後觸發它的程序可以對其進行訪問。這意味著我們錯過了一部分架構。除了`web`,`broker`和`worker`元件,還有一個`results backend`。
## 參考 - [Celery](https://www.fullstackpython.com/celery.html) - [Task Queue](https://www.fullstackpython.com/task-queues.html) - [Celery: an overview of the architecture and how it works](https://www.vinta.com.br/blog/2017/celery-overview-archtecture-and-how-it-works/) - [asynchronous-task-execution-in-python](https://bhavaniravi.com/blog/asynchronous-task-execution-in-