
Go語言GC實現原理及原始碼分析
阿新 • • 發佈:2021-03-25
> 轉載請宣告出處哦~,本篇文章釋出於luozhiyun的部落格:https://www.luozhiyun.com/archives/475
>
> 本文使用的 Go 的原始碼1.15.7
## 介紹
### 三色標記法
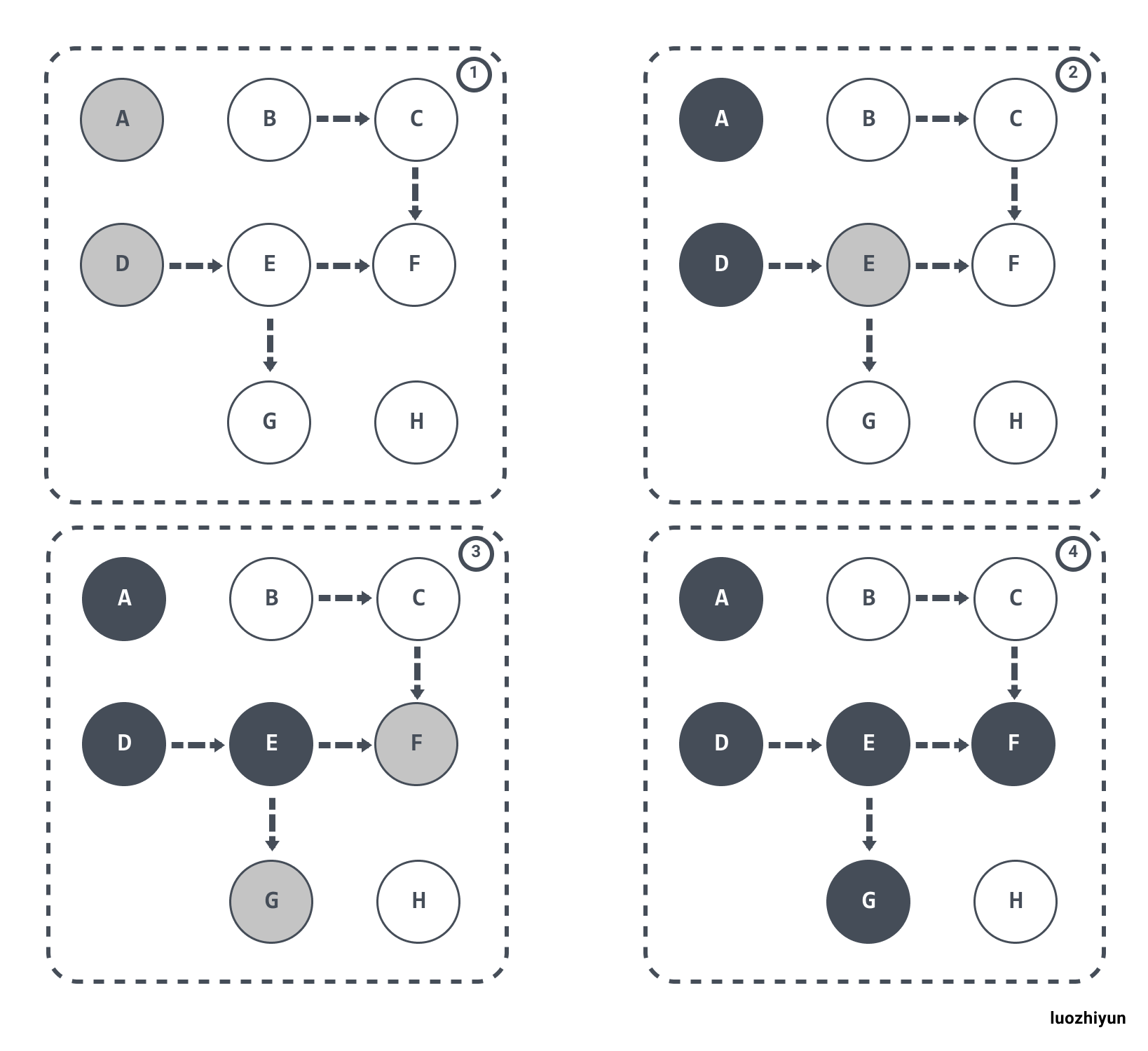
三色標記法將物件的顏色分為了黑、灰、白,三種顏色。
- 黑色:該物件已經被標記過了,且該物件下的屬性也全部都被標記過了(程式所需要的物件);
- 灰色:該物件已經被標記過了,但該物件下的屬性沒有全被標記完(GC需要從此物件中去尋找垃圾);
- 白色:該物件沒有被標記過(物件垃圾);
在垃圾收集器開始工作時,從 GC Roots 開始進行遍歷訪問,訪問步驟可以分為下面幾步:
1. GC Roots 根物件會被標記成灰色;
2. 然後從灰色集合中獲取物件,將其標記為黑色,將該物件引用到的物件標記為灰色;
3. 重複步驟2,直到沒有灰色集合可以標記為止;
4. 結束後,剩下的沒有被標記的白色物件即為 GC Roots 不可達,可以進行回收。
流程大概如下:
下面我們來說說三色標記法會存在的問題。
### 三色標記法所存在問題
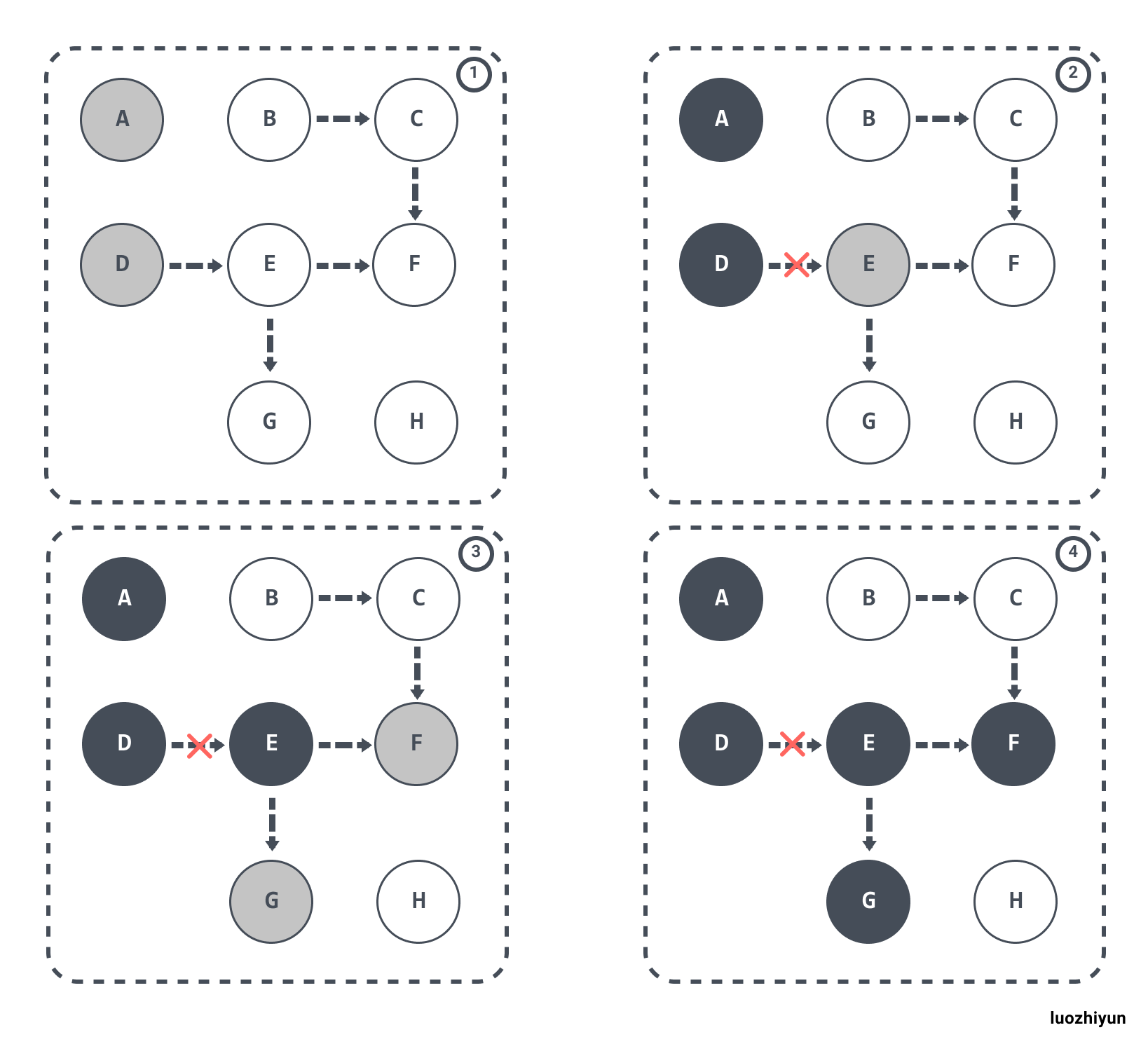
#### 多標-浮動垃圾問題
假設 E 已經被標記過了(變成灰色了),此時 D 和 E 斷開了引用,按理來說物件 E/F/G 應該被回收的,但是因為 E 已經變為灰色了,其仍會被當作存活物件繼續遍歷下去。最終的結果是:這部分物件仍會被標記為存活,即本輪 GC 不會回收這部分記憶體。
這部分本應該回收 但是沒有回收到的記憶體,被稱之為“浮動垃圾”。過程如下圖所示:
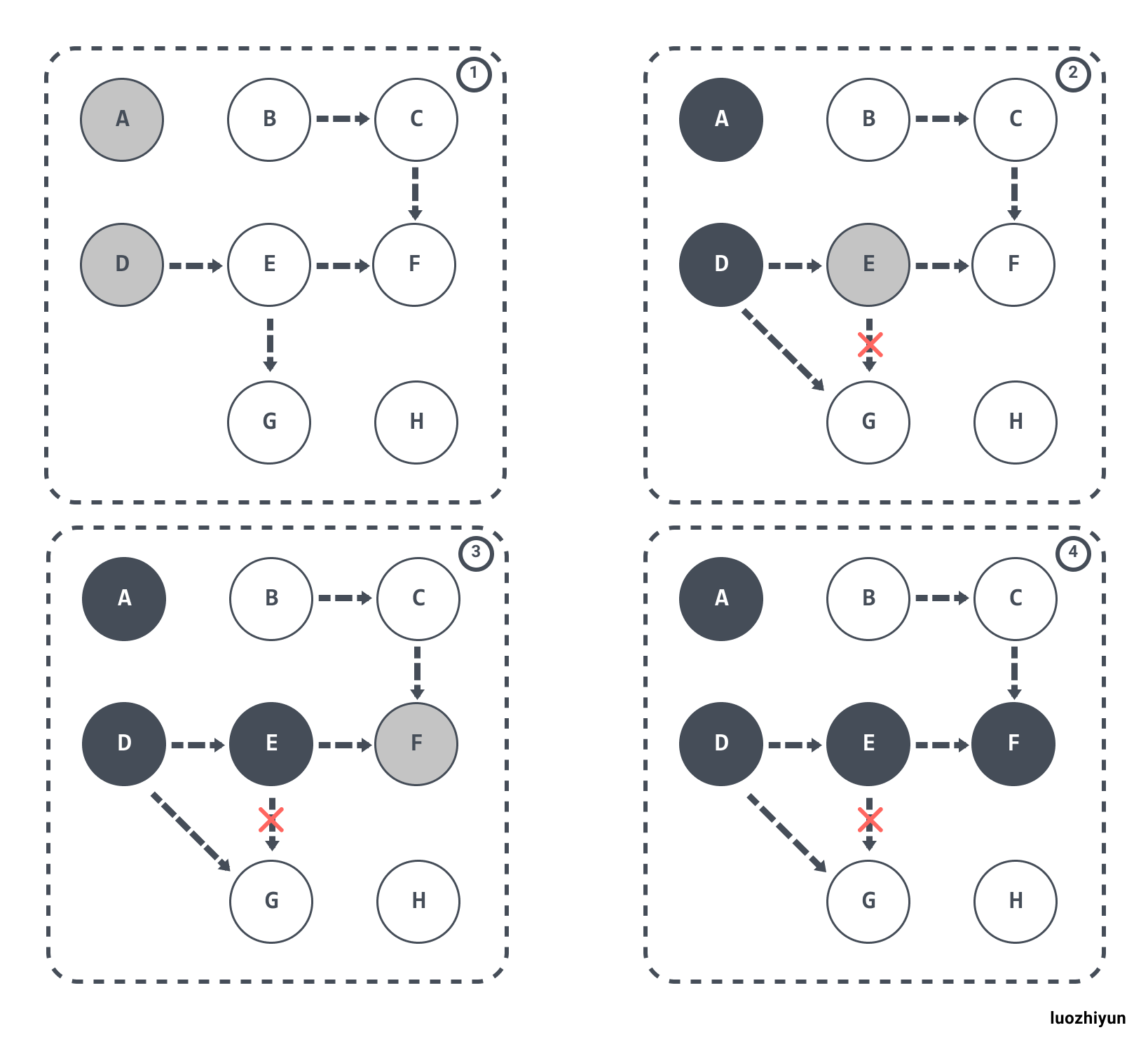
#### 漏標-懸掛指標問題
除了上面多標的問題,還有就是漏標問題。當 GC 執行緒已經遍歷到 E 變成灰色,D變成黑色時,灰色 E 斷開引用白色 G ,黑色 D 引用了白色 G。此時切回 GC 執行緒繼續跑,因為 E 已經沒有對 G 的引用了,所以不會將 G 放到灰色集合。儘管因為 D 重新引用了 G,但因為 D 已經是黑色了,不會再重新做遍歷處理。
最終導致的結果是:G 會一直停留在白色集合中,最後被當作垃圾進行清除。這直接影響到了應用程式的正確性,是不可接受的,這也是 Go 需要在 GC 時解決的問題。
### 記憶體屏障
為了**解決**上面的懸掛指標問題,我們需要引入屏障技術來保障資料的一致性。
> A **memory barrier**, is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memoryoperations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier.
記憶體屏障,是一種屏障指令,它能使CPU或編譯器對在該屏障指令之前和之後發出的記憶體操作強制執行**排序約束**,在記憶體屏障前執行的操作一定會先於記憶體屏障後執行的操作。
那麼為了在標記演算法中保證正確性,那麼我們需要達成下面任意一個條件:
* 強三色不變性(strong tri-color invariant):黑色物件不會指向白色物件,只會指向灰色物件或者黑色物件;
* 弱三色不變性(weak tri-color invariant):即便黑色物件指向白色物件,那麼從灰色物件出發,總存在一條可以找到該白色物件的路徑;
根據操作型別的不同,我們可以將記憶體屏障分成 Read barrier(讀屏障)和 Write barrier(寫屏障)兩種,在 Go 中都是使用 Write barrier(寫屏障),原因在《Uniprocessor Garbage Collection Techniques》也提到了:
> If a non copying collector is used the use of a read barrier is an unnecessary expense.there is no need to protect the mutator from seeing an invalid version of a pointer. Write barrier techniques are cheaper, because heap writes are several times less common than heap reads
對於一個不需要物件拷貝的垃圾回收器來說, Read barrier(讀屏障)代價是很高的,因為對於這類垃圾回收器來說是不需要儲存讀操作的版本指標問題。相對來說 Write barrier(寫屏障)程式碼更小,因為堆中的寫操作遠遠小於堆中的讀操作。
來下面我們看看 Write barrier(寫屏障)是如何做到這一點的。
#### Dijkstra Write barrier
Go 1.7 之前使用的是 Dijkstra Write barrier(寫屏障),使用的實現類似下面虛擬碼:
```go
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
```
如果該物件是白色的話,`shade(ptr)`會將物件標記成灰色。這樣可以保證強三色不變性,它會保證 ptr 指標指向的物件在賦值給 `*slot` 前不是白色。
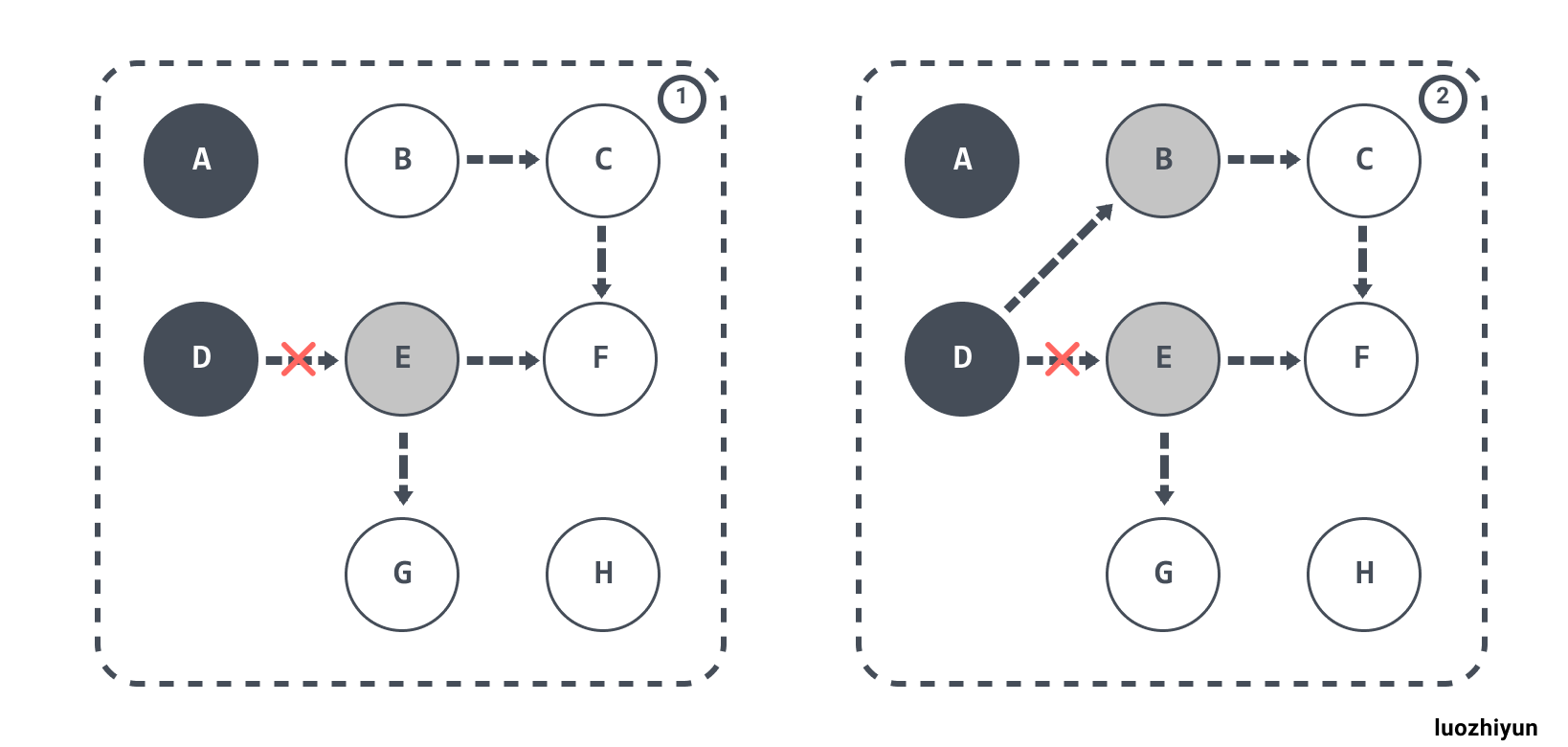
如下,根物件指向的 D 物件標記成黑色並將 D 物件指向的物件 E 標記成灰色;如果 D 斷開對 E 的引用,改成引用 B 物件,那麼這時觸發寫屏障將 B 物件標記成灰色。
Dijkstra Write barrier雖然實現非常的簡單,並且也能保證強三色不變性,但是在《Proposal: Eliminate STW stack re-scanning》中也提出了它具有一些缺點:
> In particular, it presents a trade-off for pointers on stacks: either writes to pointers on the stack must have write barriers, which is prohibitively expensive, or stacks must be permagrey.
因為棧上的物件在垃圾收集中也會被認為是根物件,所以要麼為棧上的物件增加寫屏障,但這會大幅度增加寫入指標的額外開銷;要麼當發生棧上的寫操作時,將棧標記為恆灰(permagrey)。
Go 1.7 的時候選擇的是將棧標記為恆灰,但需要在標記終止階段 STW 時對這些棧進行重新掃描(re-scan)。原因如下所描述:
> without stack write barriers, we can‘t ensure that the stack won’t later contain a reference to a white object, so a scanned stack is only black until its goroutine executes again, at which point it conservatively reverts to grey. Thus, at the end of the cycle, the garbage collector must re-scan grey stacks to blacken them and finish marking any remaining heap pointers.
#### Yuasa Write barrier
Yuasa Write barrier 是 Yuasa 在《Real-time garbage collection on general-purpose machines》中提出的一種刪除屏障(deletion barrier)技術。其思想是當賦值器從灰色或白色物件中刪除白色指標時,通過寫屏障將這一行為通知給併發執行的回收器。
該演算法會使用如下所示的寫屏障保證增量或者併發執行垃圾收集時程式的正確性,虛擬碼實現如下:
```
writePointer(slot, ptr)
shade(*slot)
*slot = ptr
```
為了防止丟失從灰色物件到白色物件的路徑,應該假設 *slot 可能會變為黑色, 為了確保 ptr 不會在被賦值到 *slot 前變為白色,shade(*slot) 會先將 *slot 標記為灰色, 進而該寫操作總是創造了一條灰色到灰色或者灰色到白色物件的路徑,這樣刪除寫屏障就可以保證弱三色不變性,老物件引用的下游物件一定可以被灰色物件引用。
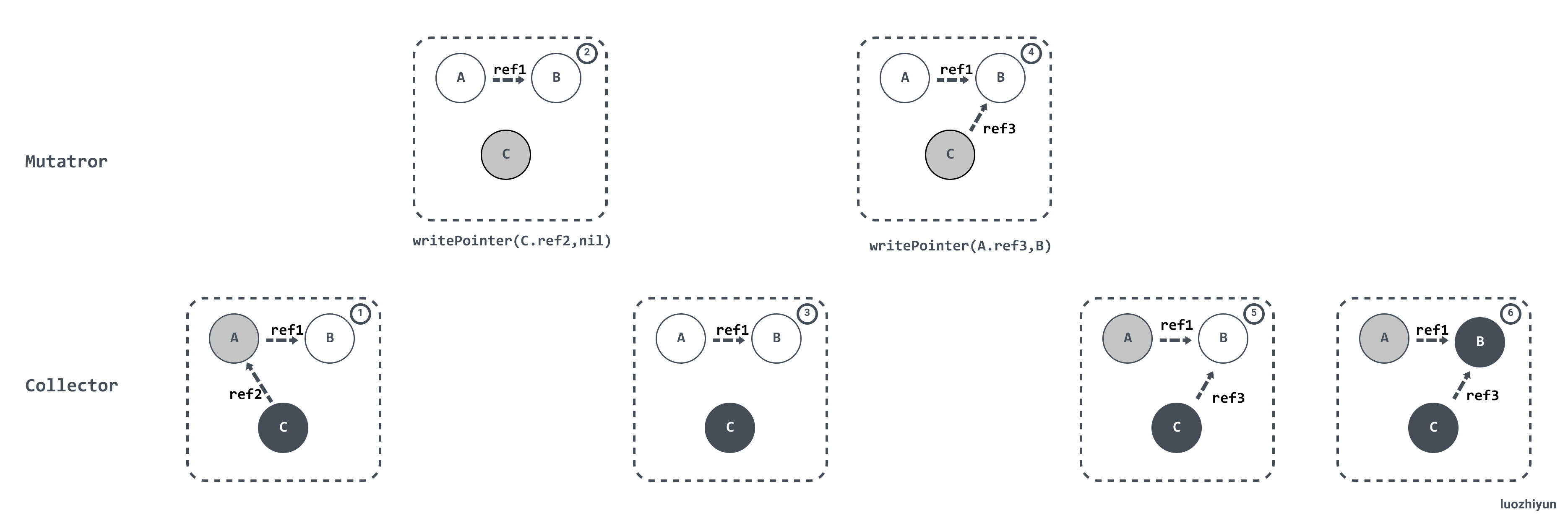
#### Hybrid write barrier
上面說了在 Go 1.7 之前使用的是 Dijkstra Write barrier(寫屏障)來保證三色不變性。Go 在重新掃描的時候必須保證物件的引用不會改變,因此會進行暫停程式(STW)、將所有棧物件標記為灰色並重新掃描,這通常會消耗10~100 毫秒的時間。
通過 Proposal: Eliminate STW stack re-scanning https://go.googlesource.com/proposal/+/master/design/17503-eliminate-rescan.md 的介紹,可以知道為了消除重新掃描所帶來的效能損耗,Go 在 1.8 的時候使用 Hybrid write barrier(混合寫屏障),結合了 Yuasa write barrier 和 Dijkstra write barrier ,實現的虛擬碼如下:
```
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
```
這樣做不僅簡化 GC 的流程,同時減少標記終止階段的重掃成本。混合寫屏障的基本思想是:
> the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
翻譯過來就是:對正在被覆蓋的物件進行著色,且如果當前棧未掃描完成, 則同樣對指標進行著色。
同時,在GC的過程中所有新分配的物件都會立刻變為黑色,在記憶體分配的時候 `go\src\runtime\malloc.go` 的 mallocgc 函式中可以看到:
```go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
dataSize := size
// 獲取mcache,用於處理微物件和小物件的分配
c := gomcache()
var x unsafe.Pointer
// 表示物件是否包含指標,true表示物件裡沒有指標
noscan := typ == nil || typ.ptrdata == 0
// maxSmallSize=32768 32k
if size <= maxSmallSize {
// maxTinySize= 16 bytes
if noscan && size < maxTinySize {
...
} else {
...
}
// 大於 32 Kb 的記憶體分配,通過 mheap 分配
} else {
...
}
...
// 在 GC 期間分配的新物件都會被標記成黑色
if gcphase != _GCoff {
gcmarknewobject(span, uintptr(x), size, scanSize)
}
...
return x
}
```
在垃圾收集的標記階段,將新建的物件標記成黑色,防止新分配的棧記憶體和堆記憶體中的物件被錯誤地回收。
## 分析
### GC phase 垃圾收集階段
GC 相關的程式碼在`runtime/mgc.go`檔案下。通過註釋介紹我們可以知道 GC 一共分為4個階段:
1. sweep termination(清理終止)
1. 會觸發 STW ,所有的 P(處理器) 都會進入 safe-point(安全點);
2. 清理未被清理的 span ,不知道什麼是 span 的同學可以看看我的:詳解Go中記憶體分配原始碼實現 https://www.luozhiyun.com/archives/434;
2. the mark phase(標記階段)
1. 將 `_GCoff` GC 狀態 改成 `_GCmark`,開啟 Write Barrier (寫入屏障)、mutator assists(協助執行緒),將根物件入隊;
2. 恢復程式執行,mark workers(標記程序)和 mutator assists(協助執行緒)會開始併發標記記憶體中的物件。對於任何指標寫入和新的指標值,都會被寫屏障覆蓋,而所有新建立的物件都會被直接標記成黑色;
3. GC 執行根節點的標記,這包括掃描所有的棧、全域性物件以及不在堆中的執行時資料結構。掃描goroutine 棧繪導致 goroutine 停止,並對棧上找到的所有指標加置灰,然後繼續執行 goroutine。
4. GC 在遍歷灰色物件佇列的時候,會將灰色物件變成黑色,並將該物件指向的物件置灰;
5. GC 會使用分散式終止演算法(distributed termination algorithm)來檢測何時不再有根標記作業或灰色物件,如果沒有了 GC 會轉為mark termination(標記終止);
3. mark termination(標記終止)
1. STW,然後將 GC 階段轉為 `_GCmarktermination`,關閉 GC 工作執行緒以及 mutator assists(協助執行緒);
2. 執行清理,如 flush mcache;
4. the sweep phase(清理階段)
1. 將 GC 狀態轉變至 `_GCoff`,初始化清理狀態並關閉 Write Barrier(寫入屏障);
2. 恢復程式執行,從此開始新建立的物件都是白色的;
3. 後臺併發清理所有的記憶體管理單元
需要注意的是,上面提到了 mutator assists,因為有一種情況:
>