
未來直播 “神器”,畫素級視訊分割是如何實現的 | CVPR 冠軍技術解讀
阿新 • • 發佈:2021-03-31
> 被譽為計算機視覺領域 “奧斯卡” 的 CVPR 剛剛落下帷幕,2021 年首屆 “新內容 新互動” 全球視訊雲創新挑戰賽正火熱進行中,這兩場大賽都不約而同地將關注點放在了視訊目標分割領域,本文將詳細分享來自阿里達摩院的團隊在 CVPR DAVIS 視訊目標分割比賽奪冠背後的技術經驗,為本屆大賽參賽選手提供 “他山之石”。
作者|負天
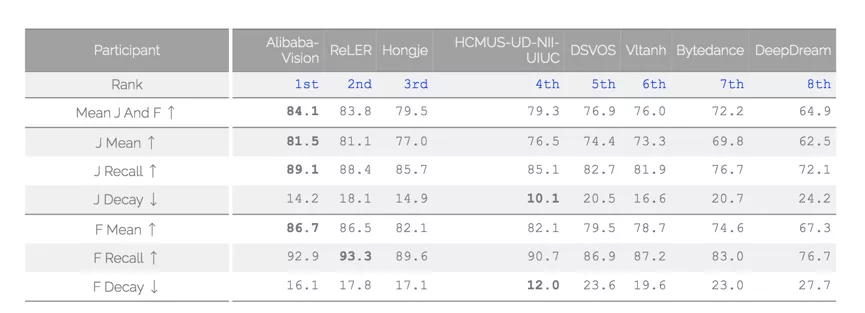
與影象識別不同,AI 分析理解視訊的技術門檻較高。長期以來,業界在視訊 AI 技術的研究上鮮有重大突破。以 CVPR 會議難度最高的比賽之一 DAVIS( Densely Annotated Video Segmentation)為例,該比賽需要參賽團隊精準處理複雜視訊中物體快速運動、外觀變化、遮擋等資訊,過去幾年,全球頂級科技在該比賽中的成績從未突破 80 分,而達摩院的模型最終在 test-challenge 上取得了 84.1 的成績。

DAVIS 的資料集經過精心挑選和標註,視訊分割中比較難的點都有體現,比如:快速運動、遮擋、消失與重現、形變等。DAVIS 的資料分為 train(60 個視訊序列), val(30 個視訊序列),test-dev(30 個視訊序列),test-challenge(30 個視訊序列)。其中 train 和 val 是可以下載的,且提供了每一幀的標註資訊。對於半監督任務, test-dev 和 test-challenge,每一幀的 RGB 圖片可以下載,且第一幀的標註資訊也提供了。演算法需要根據第一幀的標註 mask,來對後續幀進行分割。分割本身是 instance 級別的。
## 阿里達摩院:畫素級視訊分割
阿里達摩院提供了一種全新的空間約束方法,打破了傳統 STM 方法缺乏時序性的瓶頸,可以讓系統基於視訊前一幀的畫面預測目標物體下一幀的位置;此外,阿里還引入了語義分割中的精細化分割微調模組,大幅提高了分割的精細程度。最終,精準識別動態目標的輪廓邊界,並且與背景進行分離,實現畫素級目標分割。
### 基本框架
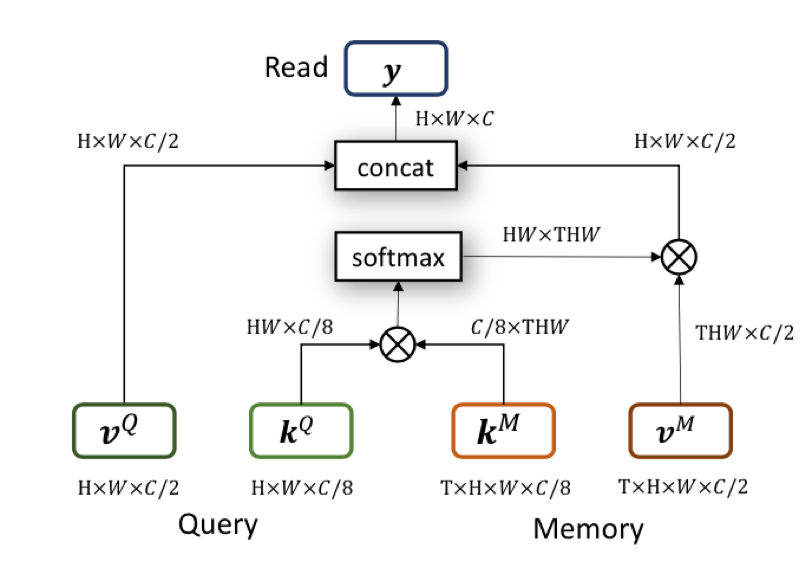
達摩院的演算法基於 2019 年 CVPR 的 STM 做了進一步改進。STM 的主要思想在於,對於歷史幀,每一幀都編碼為 key-value 形式的 feature。預測當前幀的時候,以當前幀的 key 去和歷史幀的 key 做匹配。匹配的方式是 non-local 的。這種 non-local 的匹配,可以看做將當前 key,每個座標上的 C 維特徵,和歷史每一幀在這個座標上的 C 維特徵做匹配。匹配得到的結果,作為一個 soft 的 index,去讀取歷史 value 的資訊。讀取的特徵和當前幀的 value 拼接起來,用於後續的預測。
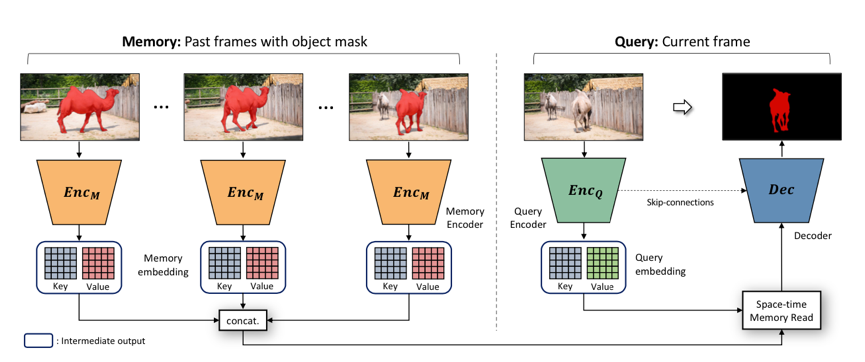
## 三大技術創新
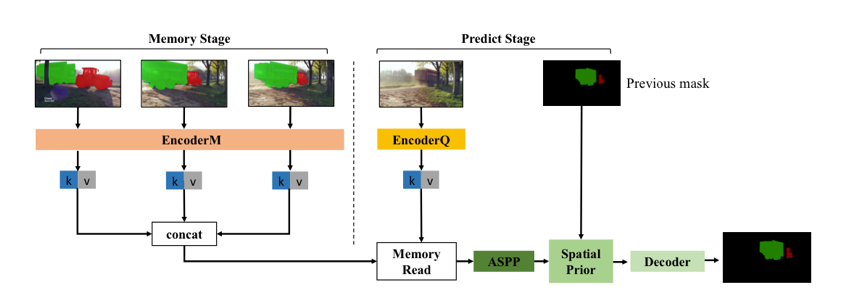
### 1. 空間約束
STM 的特徵匹配方式,提供了一種空間上的長依賴, 類似於 Transformer 中,通過 self-attention 來做序列關聯。這種機制,能夠很好地處理物體運動、外觀變化、遮擋等。但也有一個問題,就是缺乏時序性,缺少短時依賴。當某一幀突然出現和目標相似的物體時,容易產生誤召回。在視訊場景中,很多情況下,當前幀臨近的幾幀,對當前幀的影響要大於更早的幀。基於這一點,達摩院提出依靠前一幀結果,計算 attention 來約束當前幀目標預測的位置,相當於對短期依賴的建模。
具體的方法如下圖所示:
1. 當前幀的特徵和前一幀的預測 mask 在 channel 維度上做 concat,得到 HxWx (c+1) 的特徵;
2. 通過卷積將特徵壓縮為 HxW;
3. 用 sigmoid 函式將 HxW 的特徵,壓縮範圍,作為空間 attention;
4. 把 attention 乘到原特徵上,作為空間約束。
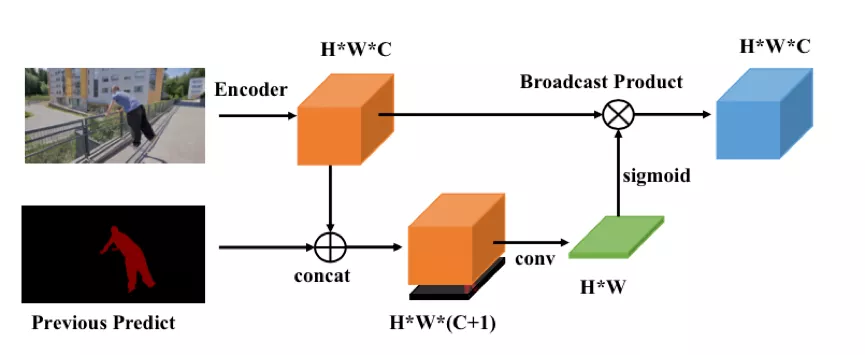
下圖為空間 attention 的視覺化結果,可以看到大致對應了前景的位置。

### 2. 增強 decoder
達摩院引入了語義分割中的感受野增強技術 ASPP 和精細化分割的微調(refinement)模組。ASPP 作用於 memory 讀取後的特徵,用於融合不同感受野的資訊,提升對不同尺度物體的處理能力。
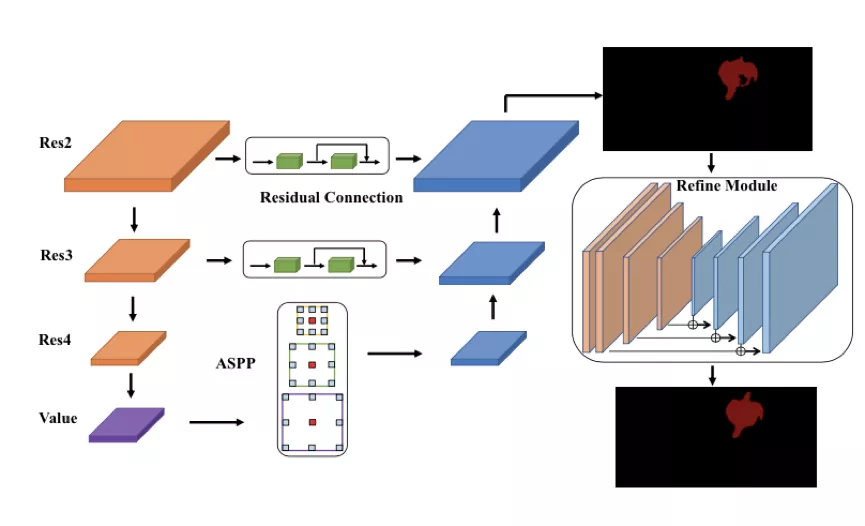
### 3. 訓練策略
達摩院提出了一個簡單但是有效的訓練策略,減少了訓練階段和測試階段存在的差異,提升了最終效果。
原始 STM 訓練時,會隨機從視訊中取樣 3 幀。這三幀之間的跳幀間隔,隨著訓練逐漸增大,目的是增強模型魯棒性。但達摩院發現,這樣會導致訓練時和測試時不一致,因為測試時,是逐幀處理的。為此,在訓練的最後階段,達摩院將跳幀間隔重新減小,以保證和測試時一致。
## 其他
**backbone**: 達摩院使用了 ResNeST 這個比較新的 backbone,它可以無痛替換掉原 STM 的 resnet。在結果上有比較明顯提升。
**測試策略**: 達摩院使用了多尺度測試和 model ensemble。不同尺度和不同 model 的結果,在最終預測的 map 上,做了簡單的等權重平均。
**視訊記憶體優化**: 達摩院做了一些視訊記憶體優化方面的工作,使得 STM 在多目標模式下,可以支援大尺度的訓練、測試,以及支援較大的 memory 容量。
**資料**: 訓練資料上,達摩院使用了 DAVIS、Youtube-VOS,以及 STM 原文用到的靜態影象資料庫。沒有其他資料。
## 結果
達摩院的模型,最終在 test-challenge 上取得了 84.1 的成績。
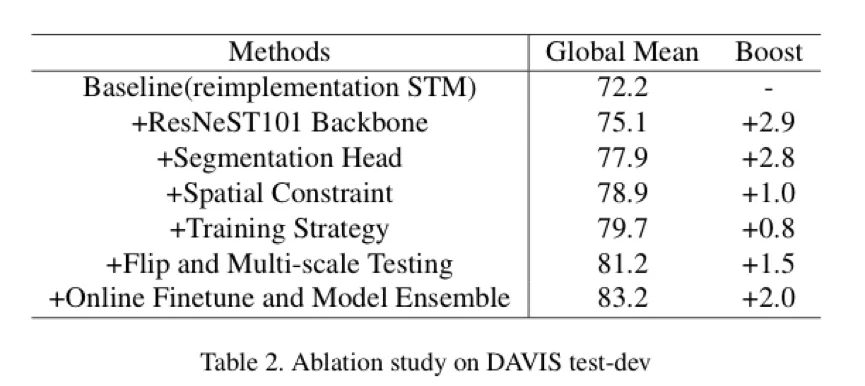
在 test-dev 上的消融實驗。達摩院復現的 STM 達到了和原文一致的結果。在各種 trick 的加持下, 得到了 11 個點的提升。
隨著網際網路技術、5G 技術等的發展,短視訊、視訊會議、直播的場景越來越多,視訊分割技術也將成為不可或缺的一環。比如,在視訊會議中,視訊分割可以精確區分前背景,從而對背景進行虛化或替換;**在直播中,使用者只需要站在綠幕前,演算法就實時替換背景,實現一秒鐘換新直播間**;在視訊編輯領域,可以輔助進行後期製作。
## 參考
1. Oh SW, Lee JY, Xu N, Kim SJ. Video object segmentation using space-time memory networks. InProceedings of the IEEE International Conference on Computer Vision 2019
1. Wang X, Girshick R, Gupta A, He K. Non-local neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition 2018
****
## “新內容 新互動” 全球視訊雲創新挑戰賽演算法挑戰賽道
本屆全球視訊雲創新挑戰賽是由阿里雲聯手英特爾主辦,與優酷戰略技術合作,面向企業以及個人開發者的音視訊領域的挑戰賽。演算法挑戰賽道聚焦視訊人像分割領域,視訊分割將傳統影象分割問題延伸到視訊領域,可服務於視訊理解處理和編輯等任務。
### 演算法賽道描述
本次大賽提供一個大規模高精度視訊人像分割資料集,供參賽選手訓練模型。不同於傳統的二值分割目標(即人像區域標註為 1,其他區域標註為 0),本競賽重點關注分割各個不同的人象例項,目標是從視訊中精確、穩定分割出顯著的(單個或多個)人體例項,以及其相應附屬物、手持物。
本次比賽分為初賽資料集和複賽資料集。複賽資料集等初賽結束後公佈,複賽中也可以使用初賽資料集。
初賽環節提供訓練集供選手下載,訓練資料集共 1650 段視訊。訓練集中每個樣本由 RGB 影象序列和掩碼影象序列組成,RGB 影象序列為原始視訊影象序列,格式為 jpg 檔案;掩碼影象為人體分割的真值 (ground-truth),格式為 png 檔案,掩碼影象中不同的畫素值表示不同的人體例項,0 為背景區域,非 0 為前景區域(例如 1 為人像 1,2 為人像 2)。RGB 和 png 檔案是一一對應關係。資料集每個視訊的長度為 80 幀~150 幀,每個視訊的解析度不完全相同。預賽的測試資料為 48 段視訊。測試集只提供 RGB 影象序列。如出現多個人像例項,每個人像可以任意順序標註,評測時將被獨立計算。
本次比賽允許引數選手使用其他公開資料集和公開模型,但參賽選手的模型必須滿足能在限定時間內復現的要求,復現精度小於規定誤差。
### 評估標準
對於演算法恢復的視訊結果,本次比賽採用 Mean J And F 做為評價指標。J 為描述分割人體區域精度的 Jaccard Index,F 為描述分割人體的邊界精確度。具體請參照參考文獻 1。每個視訊允許選手最多輸出 8 個人物分割結果,選手分割結果與真值先進行 IOU 匹配,找到對應的人物後,根據該結果進行評分。多餘的分割結果,沒有懲罰。如果超過 8 個區域,整個視訊結果無效。
### 獎項設定
**冠軍**:1 支隊伍,獎金 9 萬人民幣,頒發獲獎證書
**亞軍**:2 支隊伍,獎金 3 萬人民幣,頒發獲獎證書
**季軍**:3 支隊伍,獎金 1 萬人民幣,頒發獲獎證書
**Cooper Lake 最佳實踐**:3 支隊伍,獎金 2 萬人民幣,頒發獲獎證書
此外,複賽稽核通過的排名前 12 隊伍,可進入阿里雲校招綠色通道。
**視訊雲大賽正在火熱報名中**
**掃碼或點選下方連結,一起驅動下一代浪潮!**
https://tianchi.aliyun.com/competition/entrance/531873/introduction
![](https://ucc.alicdn.com/pic/developer-ecology/25ba425499d8427fb7f5dc16abf22