
機器學習中的數學意義
機器學習中的用於聲稱效能的指標標準很少被討論。由於在這個問題上似乎沒有一個明確的、廣泛的共識,因此我認為提供我一直在倡導並儘可能遵循的標準可能會很有趣。它源於這個簡單的前提,這是我的科學老師從中學開始就灌輸給我的:
- 科學報告的一般規則是,您寫下的每個數字都應為“ 真”的,因為“ 真”的定義是什麼。
- 讓我們來研究一下這對測試效能等統計量意味著什麼。當你在科學出版物中寫下以下陳述時:
- 測試準確率為52.34%。你所表達的是,據你所知,你的模型在從測試分佈中提取的未見資料上成功的概率在0.52335和0.52345之間。

這是一個非常強有力的宣告。
考慮你的測試集是從正確的測試分佈中抽取的N個樣本IID組成的。成功率可以表示為一個二項式變數,其平均概率p由樣本平均值估計:p ≅ s / N
- 其標準差為:σ=√p(1-p)。
- 其中當p=0.5時,其上限為0.5。
- 在正態近似下,估計量的標準差為:δ=σ/√N。
這個精度估計上的誤差δ 是這樣的,在最壞的情況下,有約50%的精度:
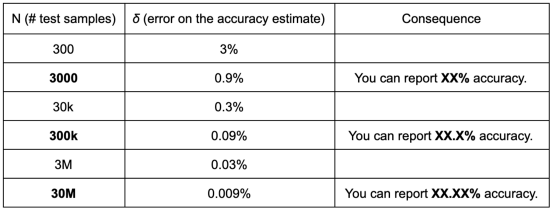
換句話說,為了保證上述報告中例子52.34%的準確率,你的測試集的大小至少應該在30M樣本的數量級上!這種粗略的分析很容易轉化為除了準確率以外的任何可計算的數量,儘管不能轉化為像似然率或困惑度這樣的連續數字。
下面是一些常見的機器學習資料集的說明。
在ImageNet上可以合理地報告多少位數的精度?準確率在80%左右,測試集是15萬張圖片:
- √(0.8*0.2/150000) = 0.103%
這意味著你幾乎可以報告XX.X%的數字,而實際上每個人都是這樣做的。
MNIST呢,準確率在99%:
- √(0.99*0.01/10000) = 0.099%
噗,也報個XX.X%就OK了!
然而,最值得注意的是,在大多數情況下,效能資料並不是單獨呈現的,而是用來比較同一測試集上的多種方法。在這種情況下,實驗之間的抽樣方差會被抵消,即使在樣本量較小的情況下,它們之間的準確度差異也可能在統計學上很顯著。估計圖方差的一個簡單方法是執行bootstrap重取樣。更嚴格、通常更嚴格的檢驗包括進行配對差異檢驗或更普遍的方差分析。
報告超出其內在精度的數字可能很具有極大的吸引力,因為在與基線進行比較的情況下,或者當人們認為測試集是一成不變的情況下,同時也不是從測試分佈中抽取的樣本時,效能數字往往更加重要。當在生產中部署模型時,這種做法會讓人感到驚訝,並且固定的測試集假設突然消失了,還有一些無關緊要的改進。更普遍的是,這種做法會直接導致對測試集進行過擬合。
那麼,在我們的領域中數字為“真”意味著什麼?好吧,這確實很複雜。對於工程師而言,很容易辯稱不應該報告的尺寸超出公差。或者對於物理學家來說,物理量不應超過測量誤差。對於機器學習從業者,我們不僅要應對測試集的取樣不確定性,而且還要應對獨立訓練執行,訓練資料的不同初始化和改組下的模型不確定性。
按照這個標準,在機器學習中很難確定哪些數字是 "真 "的。解決辦法當然是儘可能地報告其置信區間。置信區間是一種更精細的報告不確定性的方式,可以考慮到所有隨機性的來源,以及除簡單方差之外的顯著性檢驗。它們的存在也向你的讀者發出訊號,表明你已經考慮過你所報告的內容的意義,而不僅僅是你的程式碼所得到的數字。用置信區間表示的數字可能會被報告得超出其名義上的精度,不過要注意的是,你現在必須考慮用多少位數來報告不確定性,正如這篇博文所解釋的那樣。一路走來都是烏龜。
數字少了,雜亂無章的東西就少了,科學性就強了。
避免報告超出統計學意義的數字結果,除非你為它們提供一個明確的置信區間。這理所當然地被認為是科學上的不良行為,尤其是在沒有進行配對顯著性測試的情況下,用來論證一個數字比另一個數字好的時候。僅憑這一點就經常有論文被拒絕。一個良好的習慣是對報告中帶有大量數字的準確率數字始終持懷疑態度。還記得3000萬、30萬和30萬的經驗法則對最壞情況下作為“嗅覺測試”的統計顯著性所需樣本數量的限制嗎?它會讓你避免追逐統計上的“幽靈”。
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
【編輯推薦】