
2020-10-14
場景
假設你現在要處理這樣一個問題,你有一個網站並且擁有很多訪客,每當有使用者訪問時,你想知道這個ip是不是第一次訪問你的網站。
hashtable 可以麼
一個顯而易見的答案是將所有的ip用hashtable存起來,每次訪問都去hashtable中取,然後判斷即可。但是題目說了網站有很多訪客, 假如有10億個使用者訪問過,每個ip的長度是4 byte,那麼你一共需要4 * 1000000000 = 4000000000Bytes = 4G , 如果是判斷URL黑名單, 由於每個URL會更長,那麼需要的空間可能會遠遠大於你的期望。
bit
另一個稍微難想到的解法是bit, 我們知道bit有0和1兩種狀態,那麼用來表示存在,不存在再合適不過了。
加入有10億個ip,我們就可以用10億個bit來儲存,那麼你一共需要 1 * 1000000000 = (4000000000 / 8) Bytes = 128M, 變為原來的1/32, 如果是儲存URL這種更長的字串,效率會更高。
基於這種想法,我們只需要兩個操作,set(ip) 和 has(ip)
這樣做有兩個非常致命的缺點:
- 當樣本分佈極度不均勻的時候,會造成很大空間上的浪費
我們可以通過雜湊函式來解決
- 當元素不是整型(比如URL)的時候,BitSet就不適用了
我們還是可以使用雜湊函式來解決, 甚至可以多hash幾次
布隆過濾器
布隆過濾器其實就是bit + 多個雜湊函式, 如果經過多次雜湊的值再bit上都為1,那麼可能存在(可能有衝突)。 如果 有一個不為1,那麼一定不存在(一個值經過雜湊函式得到的值一定是唯一的),這也是布隆過濾器的一個重要特點。
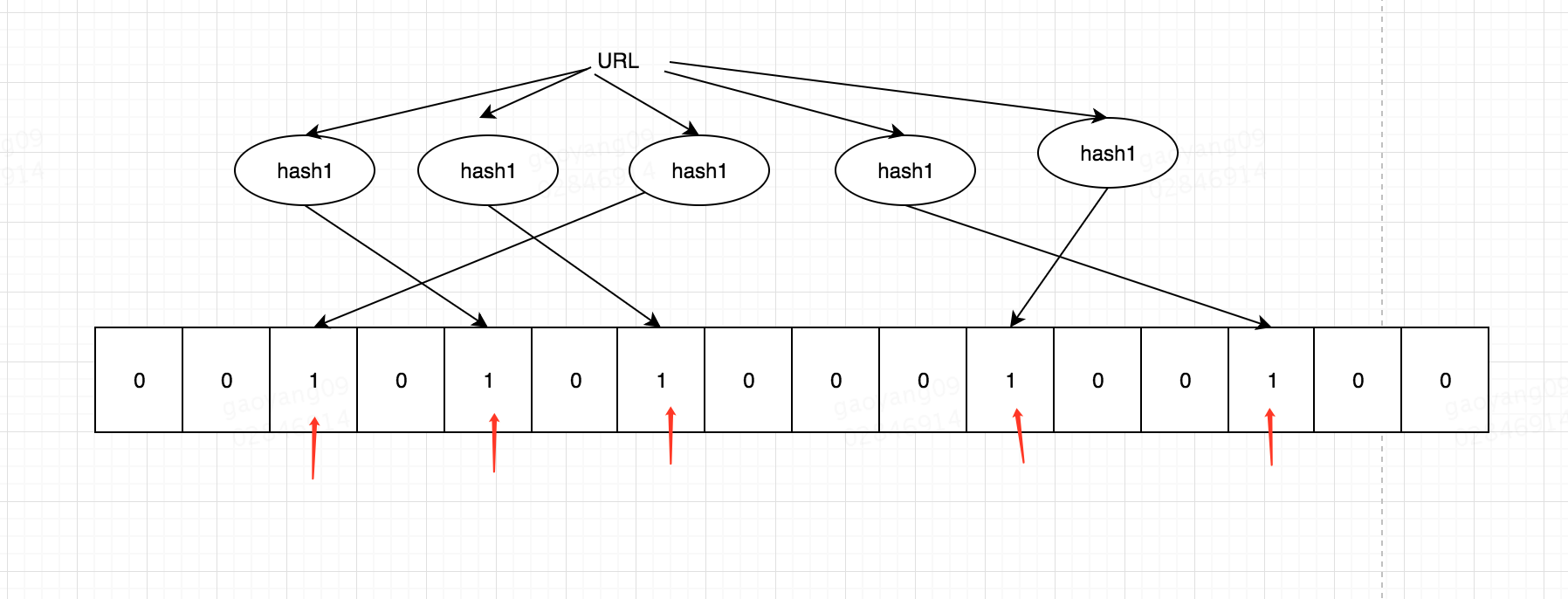
布隆過濾器的應用
-
網路爬蟲 判斷某個URL是否已經被爬取過
-
K-V資料庫 判斷某個key是否存在
比如Hbase的每個Region中都包含一個BloomFilter,用於在查詢時快速判斷某個key在該region中是否存在。
- 釣魚網站識別
瀏覽器有時候會警告使用者,訪問的網站很可能是釣魚網站,用的就是這種技術
從這個演算法大家可以對 tradeoff(取捨) 有更入的理解。