
kubernetes配置glusterfs作為後端動態儲存
原文轉載於:https://www.cnblogs.com/yuhaohao/p/10281392.html
GlusterFS分散式檔案系統
一.簡單介紹
分散式儲存按其儲存介面分為三種:檔案儲存、塊儲存、物件儲存
*檔案儲存
通常支援POSIX介面(如glusterFS,但GFS、HDFS是非POSIX介面的),可以像普通檔案系統(如ext4)那樣訪問,但又比普通檔案系統多了並行化訪問的能力和冗餘機制。主要的分散式儲存系統有TFS、CephFS、GlusterFS和HDFS等。主要儲存非結構化資料,如普通檔案,圖片,音視訊等。
*塊儲存
這種介面通常以QEMU Driver或者Kernel Module的方式存在,主要通過qemu或iscsi協議訪問。主要的塊儲存系統有Ceph塊儲存、SheepDog等。主要用來儲存結構化資料,如資料庫資料。
*物件儲存
物件儲存系統綜合了檔案系統(NAS)和塊儲存(SAN)的優點,同時具有SAN的高速直接訪問和NAS的資料共享等優勢。以物件作為基本的儲存單元,向外提供Restful資料讀寫介面,常以網路服務的形式提供資料訪問。主要的物件儲存系統有AWS、Swift和Ceph物件儲存。主要用來儲存費結構化資料
GlusterFS是Scale-out儲存解決方案Gluster的核心,它是一個開源的分散式檔案系統,具有強大的橫向擴充套件能力,通過擴充套件能夠支援數PB儲存容量和處理數千客戶端。GlusterFS藉助TCP/IP或者InfiniBandRDMA網路將物理分佈的儲存資源聚集在一起,具有高擴充套件性、高可用性、高效能的特點,並且沒有元資料伺服器的設計,讓整個服務沒有單點故障的隱患,使用單一全域性名稱空間來管理資料。
二.GlusterFS架構
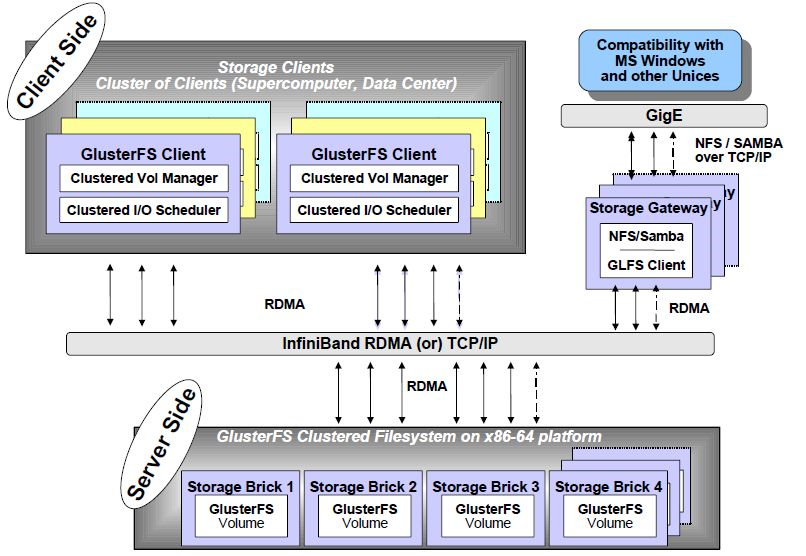{kind=link}
三.GlusterFS特點
*優勢:
- 擴充套件性和高效能
GlusterFS採用無中心對稱式結構,沒有專用的元資料伺服器,也就不存在元資料伺服器瓶頸。元資料存在於檔案的屬性和擴充套件屬性中,當需要訪問某檔案時,客戶端使用DHT演算法,根據檔案的路徑和檔名計算出檔案所在的brick,然後由客戶端從此brick獲取資料,省去了同元資料伺服器通訊的過程。 - 良好的可擴充套件性
使用彈性hash演算法替代傳統的有元資料節點服務,獲得了接近線性的高擴充套件性 - 高可用
採用副本、EC等冗餘設計,保證在冗餘範圍內的節點掉線時,任然可以從其它伺服器節點獲取資料,保證高可用性。採用弱一致性的設計,當向副本中檔案寫入資料時,客戶端計算出檔案所在brick,然後通過網路把資料傳給所在brick,當其中有一個成功返回,就認為資料成功寫入,不必等待其它brick返回,就會避免當某個節點網路異常或磁碟損壞時,因為一個brick沒有成功寫入而導致寫操作等待。
伺服器端還會隨著儲存池的啟動,而開啟一個glustershd程序,這個程序會定期檢查副本和EC卷中各個brick之間資料的一致性,並恢復。 - 儲存池型別豐富
包括粗粒度、條帶、副本、條帶副本和EC,可以根據使用者的需求,滿足不同程度的冗餘。
粗粒度不帶任何冗餘,檔案不進行切片,是完整的存放在某個brick上。
條帶卷不帶任何冗餘,檔案會切片儲存(預設大小為128kB)在不同的brick上,這些切片可以併發讀寫(併發粒度是條帶塊),可以明顯提高讀寫效能。該模式一般只適合用於處理超大型檔案和多節點效能要求高的情況。
副本卷冗餘度高,副本數量可以靈活配置,可以保證資料的安全性
條帶副本卷是條帶卷和副本卷的結合
EC卷使用EC校驗演算法,提供了低於副本卷的冗餘度,冗餘度小於100%,滿足比較低的資料安全性,例如可以使2+1(冗餘度為50%),5+3(冗餘度為60%)等。這個可以滿足安全性要求不高的資料
*缺點:
- 擴容、縮容時影響的伺服器較多
GlusterFS對邏輯卷中的儲存單元brick劃分hash分散式空間(會以brick所在磁碟大小作為權重,空間總範圍為0~2**32-1),一個brick佔一份空間,當訪問某檔案時,使用Davies-Meyer演算法根據檔名計算出hash值,比較hash值落在哪個範圍內,即可確認檔案所在的brick,這樣定位檔案會很快。但是在向邏輯卷中新增或移除brick時,hash分佈空間會重新計算,每個brick的hash範圍都會變化,檔案定位就會失敗,因此需要遍歷檔案,把檔案移動到正確的hash分佈範圍對應的brick上,移動的檔案可能會很多,載入系統負載,影響到正常的檔案訪問操作。 - 遍歷目錄下檔案耗時
GlusterFS沒有元資料節點,而是根據hash演算法來確定檔案的分佈,目錄利用擴充套件屬性記錄子卷中的brick的hash分佈範圍,每個brick的範圍均不重疊,遍歷目錄時,需要readdir子卷中每個brick中的目錄。獲取每個檔案的屬性和擴充套件屬性,然後進行聚合,相對於有專門元資料節點的分散式儲存,遍歷效率會差很多,當目錄下有大量檔案時,遍歷會非常緩慢。
刪除目錄也會遇到此問題,目前提供的解決方法是合理組織目錄結構,目錄層級不要太深,目錄下檔案數量不要太多,增大GlusterFS目錄快取,另外,還可以設計把元資料和資料分離,把元資料放到記憶體資料庫中(如redis、memcache),並在ssd上持久保持 - 小檔案效能較差
GlusterFS主要是為大檔案設計,如io-cache、read-ahead、write-behind和條帶等都是為優化大檔案訪問,對小檔案的優化很少。
GlusterFS採用無元資料節點的設計,檔案的元資料和資料一起保持在檔案中,訪問元資料和資料的速率相同。訪問元資料的時間與訪問資料的時間比例會較大,而有元資料中心的分散式儲存系統,對元資料伺服器可以採用快速的SSD盤(如ceph),可以採用更大的元資料快取等優化措施才減少訪問元資料時間與訪問資料時間的比值,來提高小檔案效能
- 間與訪問資料的時間比例會較大,而有元資料中心的分散式儲存系統,對元資料伺服器可以採用快速的SSD盤(如ceph),可以採用更大的元資料快取等優化措施才減少訪問元資料時間與訪問資料時間的比值,來提高小檔案效能
四.GlusterFS的元件
-
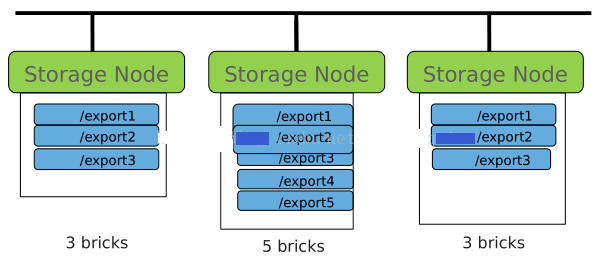
brick
GlusterFS中的儲存單元,通常是一個受信儲存池中的伺服器的一個匯出目錄。可以通過主機名和目錄名來標識,如'SERVER:EXPORT' -
Client
掛載了GlusterFS卷的裝置 -
GFID
GlusterFS卷中的每個檔案或目錄都有一個唯一的128位的資料相關聯,其用於模擬inode -
Namespace
每個Gluster卷都匯出單個ns作為POSIX的掛載點 -
Node
一個擁有若干brick的裝置 -
RDMA
遠端直接記憶體訪問,支援不通過雙方的OS進行直接記憶體訪問 -
RRDNS
round robin DNS是一種通過DNS輪轉返回不同的裝置以進行負載均衡的方法 -
Self-heal
用於後臺執行監測副本卷中檔案和目錄的不一致性並解決這些不一致 -
Split-brain
腦裂 -
Volfile
GlusterFS程序的配置檔案,通常位於/var/lib/glusterd/vols/volname -
Volume
- 是brick的邏輯組合
- 建立時命名來識別
-
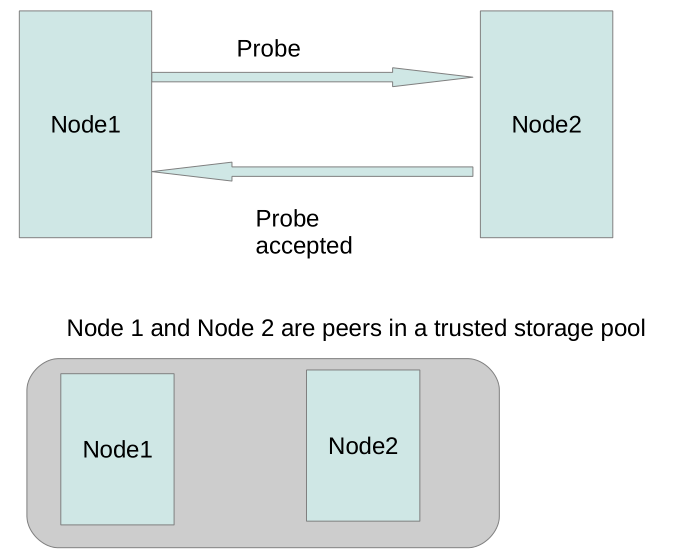
Trushed Storage Pool
{kind=link}
{kind=link}
五.GlusterFS叢集的部署
我們使用GlusterF作為K8S的後端儲存,在使用動態儲存StorageClass時,叢集至少需要配置三節點,如果GlusterFS叢集少於三節點,在建立volume時會提示Failed to allocate new volume:Nospace報錯
這裡我們採用的叢集節點如下:
節點hostname 節點IP 資料盤 192.168.0.211 k8s-master /dev/sdb 192.168.0.212 k8s-node1 /dev/sdb 192.168.0.213 k8s-node2 /dev/sdb
5.1 部署配置GlusterFS叢集
1)所有節點安裝gluster
yum install centos-release-gluster -y
yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma glusterfs-geo-replication glusterfs-devel
2)所有節點啟動glusterFS
systemctl start glusterd.service systemctl enable glusterd.service systemctl status glusterd.service
3)在叢集任意節點,將glusterfs其他的peer新增進去
[root@k8s-master ~]# gluster peer probe k8s-node1 peer probe: success. [root@k8s-master ~]# gluster peer probe k8s-node2 peer probe: success. [root@k8s-master ~]# gluster pool list UUID Hostname State be94a0f1-5fc6-4d50-8460-0276426c81ab k8s-node1 Connected d6918655-2477-4a06-99c8-0dfbf810e4ef k8s-node2 Connected 91c0e283-9c77-4687-a5f8-1a2d1e951e55 localhost Connected
4)格式化叢集所有節點的所有資料盤,並將物理硬碟分割槽初始化為物理卷
[root@k8s-master ~]# mkfs.xfs /dev/sdb -f
[root@k8s-master ~]# pvcreate /dev/sdb [root@k8s-node1 ~]# mkfs.xfs /dev/sdb -f
[root@k8s-node1 ~]# pvcreate /dev/sdb [root@k8s-node2 ~]# mkfs.xfs /dev/sdb -f
[root@k8s-node2 ~]# pvcreate /dev/sdb
5.2 部署配置GlusterFS的動態儲存StorageClass
heketi提供一個RESTful管理節點介面,可以用來管理GlusterFS卷的生命週期,通過heketi,就可以像使用Opentack Manila,kubernete和openShift一樣申請可以動態配置GlusterFS卷,Heketi會動態在叢集內選擇bricks構建所需的volumes,這樣以確保資料的副本會分散到叢集不同的故障域內。
1)所有節點安裝heketi和heketi的客戶端
[root@k8s-master ~]# yum install -y heketi heketi-client [root@k8s-node1 ~]# yum install -y heketi heketi-client [root@k8s-node2 ~]# yum install -y heketi heketi-client
2)在叢集主節點配置SSH金鑰
[root@k8s-master ~]# ssh-keygen -f /etc/heketi/heketi_key -t rsa -N '' [root@k8s-master ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@k8s-master [root@k8s-master ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@k8s-node1 [root@k8s-master ~]# ssh-copy-id -i /etc/heketi/heketi_key.pub root@k8s-node2 [root@k8s-master ~]# chown heketi:heketi /etc/heketi/heketi_key*
3)編輯修改heketi的配置檔案/etc/heketi/heketi.json
heketi有三種executor,分別為mock,ssh,kubernetes,建議在測試環境使用mock,生成環境使用ssh,當glusterfs以容器的方式部署在Kubernetes上時,才是用kubernetes。
{
"_port_comment": "Heketi Server Port Number",
#這裡埠預設為8080,如果在實際的使用過程中,可以修改此埠號
"port": "8080",
"_use_auth": "Enable JWT authorization. Please enable for deployment",
#開啟認證
"use_auth": true,
"_jwt": "Private keys for access",
"jwt": {
"_admin": "Admin has access to all APIs",
"admin": {
"key": "adminkey"
},
"_user": "User only has access to /volumes endpoint",
"user": {
"key": ""userkey""
}
},
"_glusterfs_comment": "GlusterFS Configuration",
"glusterfs": {
"_executor_comment": [
"Execute plugin. Possible choices: mock, ssh",
"mock: This setting is used for testing and development.",
" It will not send commands to any node.",
"ssh: This setting will notify Heketi to ssh to the nodes.",
" It will need the values in sshexec to be configured.",
"kubernetes: Communicate with GlusterFS containers over",
" Kubernetes exec api."
],
#修改執行外掛為ssh
"executor": "ssh",
#配置ssh所需的證書
"_sshexec_comment": "SSH username and private key file information",
"sshexec": {
"keyfile": "/etc/heketi/heketi_key",
"user": "root",
"port": "22",
"fstab": "/etc/fstab"
},
"_kubeexec_comment": "Kubernetes configuration",
"kubeexec": {
"host" :"https://kubernetes.host:8443",
"cert" : "/path/to/crt.file",
"insecure": false,
"user": "kubernetes username",
"password": "password for kubernetes user",
"namespace": "OpenShift project or Kubernetes namespace",
"fstab": "Optional: Specify fstab file on node. Default is /etc/fstab"
},
"_db_comment": "Database file name",
"db": "/var/lib/heketi/heketi.db",
"_loglevel_comment": [
"Set log level. Choices are:",
" none, critical, error, warning, info, debug",
"Default is warning"
],
"loglevel" : "debug"
}
}
4)在叢集所有節點將heketi服務加入開機啟動,並啟動服務
[root@k8s-master ~]# systemctl restart heketi [root@k8s-master ~]# systemctl enable heketi [root@k8s-node1 ~]# systemctl restart heketi [root@k8s-node1 ~]# systemctl enable heketi [root@k8s-node2 ~]# systemctl restart heketi [root@k8s-node2 ~]# systemctl enable heketi
5)測試heketi的連線
[root@k8s-master ~]# curl http://k8s-node2:8080/hello Hello from Heketi [root@k8s-master ~]# curl http://k8s-node1:8080/hello Hello from Heketi [root@k8s-master ~]# curl http://k8s-master:8080/hello Hello from Heketi
6)在叢集的主節點設定環境變數
注意這裡的埠號要和/etc/heketi/heketi.json配置檔案中的保持一致
[root@glusterfs-01 ~]#export HEKETI_CLI_SERVER=http://k8s-master:8080
6)在叢集的主節點修改/usr/share/heketi/topology-sample.json配置檔案,執行新增節點和新增device的操作
manage為GFS管理服務的Node節點主機名,storage為Node節點IP,device為Node節點上的裸裝置
[root@k8s-master ~]# cat /usr/share/heketi/topology-sample.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "k8s-master" ], "storage": [ "192.168.0.211" ] }, "zone": 1 }, "devices": [ { "name": "/dev/sdb", "destroydata": false } ] }, { "node": { "hostnames": { "manage": [ "k8s-node1" ], "storage": [ "192.168.0.212" ] }, "zone": 1 }, "devices": [ { "name": "/dev/sdb", "destroydata": false } ] }, { "node": { "hostnames": { "manage": [ "k8s-node2" ], "storage": [ "192.168.0.213" ] }, "zone": 1 }, "devices": [ { "name": "/dev/sdb", "destroydata": false } ] } ] } ] }
執行建立:
[root@k8s-master ~]# heketi-cli topology load --json=/usr/share/heketi/topology-sample.json Found node k8s-master on cluster df868693bc506f0273852c454b71c415 Adding device /dev/sdb ... OK Found node k8s-node1 on cluster df868693bc506f0273852c454b71c415 Adding device /dev/sdb ... OK Found node k8s-node2 on cluster df868693bc506f0273852c454b71c415 Adding device /dev/sdb ... OK
建立一個volume測試:
[root@k8s-master yaml]# heketi-cli volume create --size=2 --user "admin" --secret "adminkey"
Name: vol_d97876e11454d259f2dcccc6a27c2a13
Size: 2
Volume Id: d97876e11454d259f2dcccc6a27c2a13
Cluster Id: df868693bc506f0273852c454b71c415
Mount: 192.168.0.212:vol_d97876e11454d259f2dcccc6a27c2a13
Mount Options: backup-volfile-servers=192.168.0.211,192.168.0.213
Block: false
Free Size: 0
Reserved Size: 0
Block Hosting Restriction: (none)
Block Volumes: []
Durability Type: replicate
Distribute Count: 1
Replica Count: 3
檢視volume的資訊:
[root@k8s-master yaml]# gluster volume info
Volume Name: vol_d97876e11454d259f2dcccc6a27c2a13
Type: Replicate
Volume ID: a1c58d2e-4245-4611-8af2-5a0c9875028b
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: 192.168.0.212:/var/lib/heketi/mounts/vg_b3a994403be347c3363a07cb43301485/brick_9077a394163d5af9a14a19857d12abd8/brick
Brick2: 192.168.0.213:/var/lib/heketi/mounts/vg_bf1d8d9ea9a01e42e4927e44c654e712/brick_4a2e7ee783495c026d12061e9dbb8865/brick
Brick3: 192.168.0.211:/var/lib/heketi/mounts/vg_8abda9d8f3a5c05efe76c03711e6331f/brick_0a078688802780f8a2b103f2b0c2a1eb/brick
Options Reconfigured:
user.heketi.id: d97876e11454d259f2dcccc6a27c2a13
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
performance.client-io-threads: off
8)配置StorageClass
建立glusterfs-storageclass.yaml檔案內容如下:
[root@k8s-master yaml]# cat gluster-storageclass.yaml --- kind: StorageClass apiVersion: storage.k8s.io/v1beta1 metadata: name: gluster-k8s provisioner: kubernetes.io/glusterfs parameters: resturl: "http://192.168.0.211:8080" restauthenabled: "true" restuser: "admin" restuserkey: "adminkey" volumetype: "replicate:2"
9)執行PVC的建立測試
[root@k8s-master gluster]# cat gluster-pvc.yaml --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: glusterfs-pvc namespace: default annotations: volume.beta.kubernetes.io/storage-class: "gluster-k8s" spec:
storageClassName: gluster-k8s accessModes: - ReadWriteMany resources: requests: storage: 1Gi
檢視建立的PVC的狀態:
[root@k8s-master gluster]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE glusterfs-pvc Bound pvc-deb44c85-2bbe-11eb-ac6d-000c29824e3f 1Gi RWX gluster-k8s 54s
PS:
報錯一:
[root@k8s-master ~]# heketi-cli topology load --json=/usr/share/heketi/topology-sample.json Creating cluster ... ID: df868693bc506f0273852c454b71c415 Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node k8s-master ... ID: 772ef741192c089f72eb93b810639c41 Adding device /dev/sdb ... Unable to add device: Setup of device /dev/sdb failed (already initialized or contains data?): WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: [n] Aborted wiping of xfs. 1 existing signature left on the device. Creating node k8s-node1 ... ID: 106b0ee5abce83199053a92515fbc1c5 Adding device /dev/sdb ... Unable to add device: Setup of device /dev/sdb failed (already initialized or contains data?): WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: [n] Aborted wiping of xfs. 1 existing signature left on the device. Creating node k8s-node2 ... ID: 79e131ca65ead7586471db873af16f45 Adding device /dev/sdb ... Unable to add device: Setup of device /dev/sdb failed (already initialized or contains data?): WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: [n] Aborted wiping of xfs. 1 existing signature left on the device.
解決方法:
進入節點glusterfs容器執行pvcreate
[root@k8s-master ~]# pvcreate /dev/sdb WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: y Wiping xfs signature on /dev/sdb. Physical volume "/dev/sdb" successfully created. [root@k8s-node1 ~]# pvcreate /dev/sdb WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: y Wiping xfs signature on /dev/sdb. Physical volume "/dev/sdb" successfully created. [root@k8s-node2 ~]# pvcreate /dev/sdb WARNING: xfs signature detected on /dev/sdb at offset 0. Wipe it? [y/n]: y Wiping xfs signature on /dev/sdb. Physical volume "/dev/sdb" successfully creat