“泰迪杯”資料分析職業技能大賽B題 學生校園消費行為分析
1. 賽題背景
校園一卡通是集身份認證、金融消費、資料共享等多項功能於一體的資訊整合系統。在為師生提供優質、高效資訊化服務的同時,系統自身也積累了大量的歷史記錄,其中蘊含著學生的消費行為以及學校食堂等各部門的執行狀況等資訊。
很多高校基於校園一卡通系統進行“智慧校園”的相關建設,例如《揚子晚報》2016年 1月 27日的報道:《南理工給貧困生“暖心飯卡補助”》。
不用申請,不用稽核,飯卡上竟然能悄悄多出幾百元……記者昨天從南京理工大學獨家瞭解到,南理工教育基金會正式啟動了“暖心飯卡”
專案,針對特困生的溫飽問題進行“精準援助”。
專案專門針對貧困本科生的“溫飽問題”進行援助。在學校一卡通中心,教育基金會的工作人員找來了全校一萬六千餘名在校本科生 9 月中旬到
11月中旬的刷卡記錄,對所有的記錄進行了大資料分析。最終圈定了 500餘名“準援助物件”。
南理工教育基金會將拿出“種子基金”100萬元作為啟動資金,根據每位貧困學生的不同情況確定具體的補助金額,然後將這些錢“悄無聲息”的打入學生的飯卡中,保證困難學生能夠吃飽飯。
——《揚子晚報》2016年 1月 27日:南理工給貧困生“暖心飯卡補助”本賽題提供國內某高校校園一卡通系統一個月的執行資料,希望參賽者使用
資料分析和建模的方法,挖掘資料中所蘊含的資訊,分析學生在校園內的學習生活行為,為改進學校服務併為相關部門的決策提供資訊支援。
2. 分析目標
-
1. 分析學生的消費行為和食堂的運營狀況,為食堂運營提供建議。
-
2. 構建學生消費細分模型,為學校判定學生的經濟狀況提供參考意見。
3. 資料說明
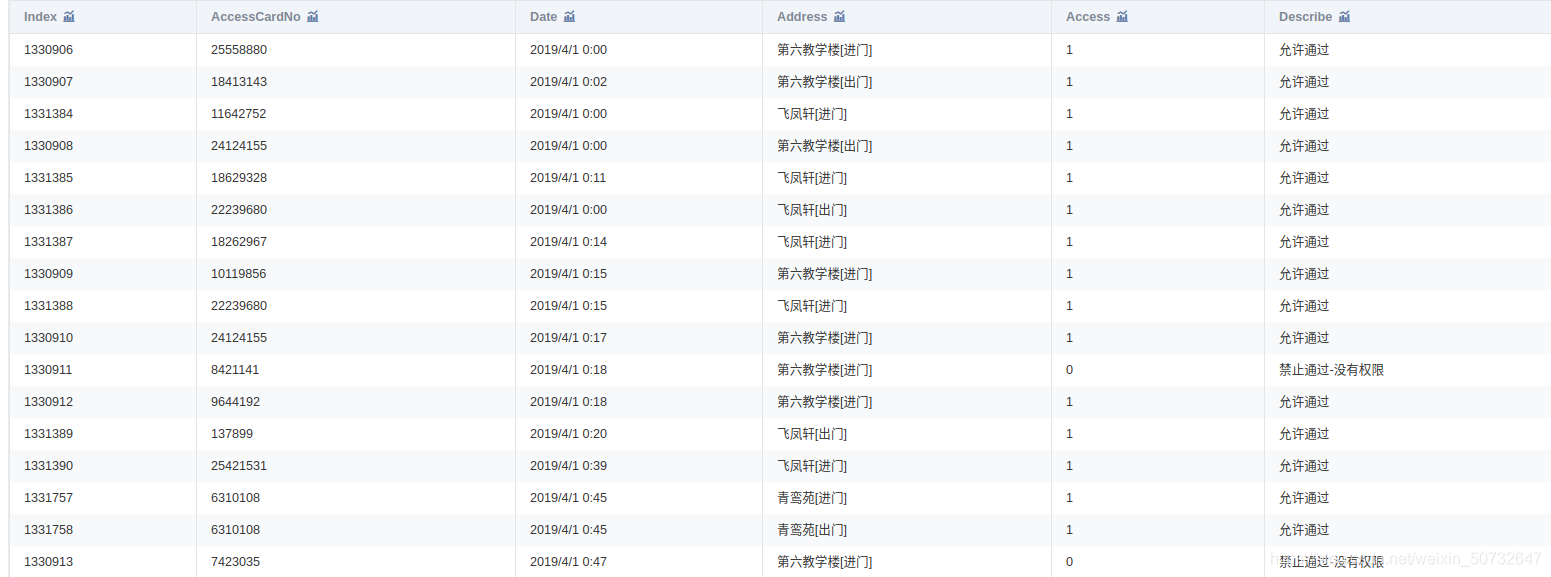
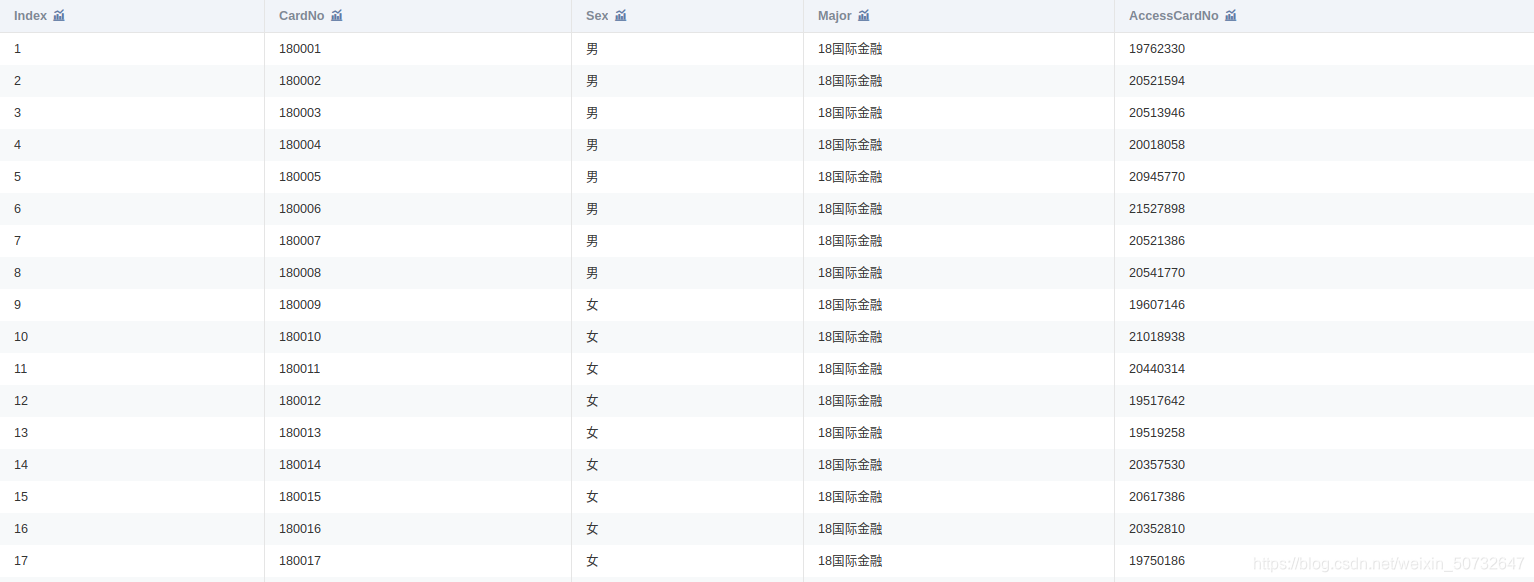
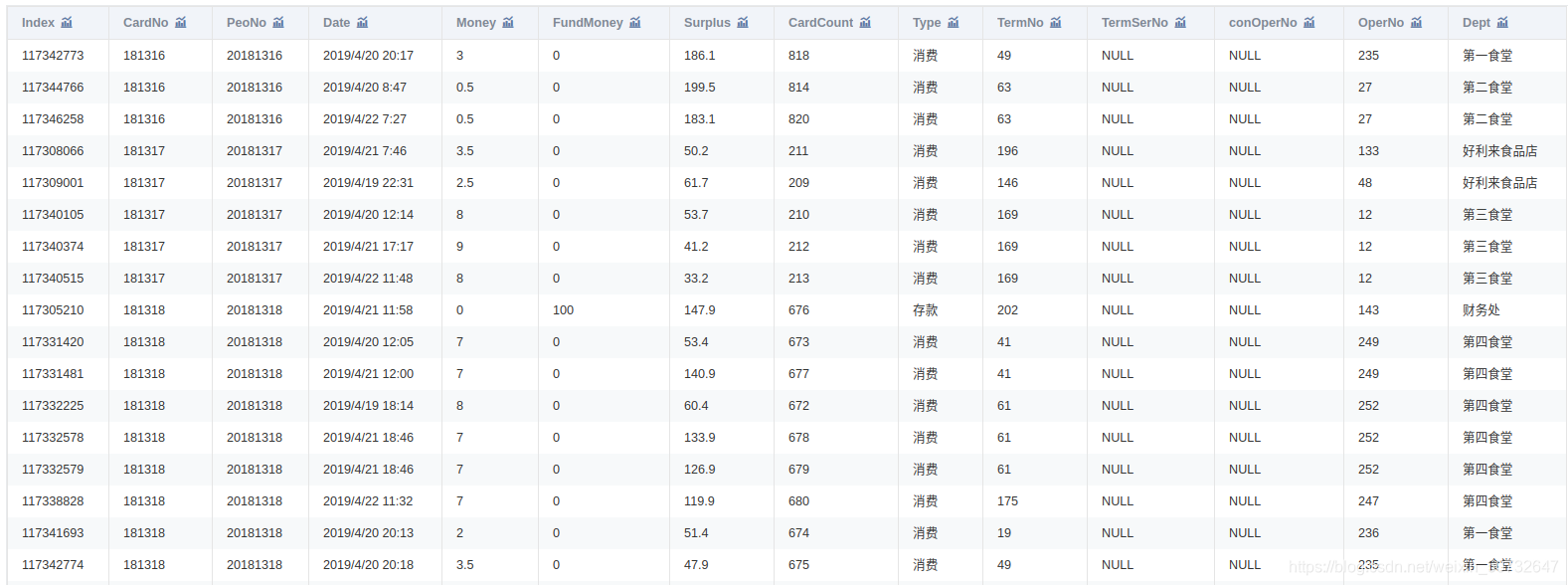
附件是某學校 2019年 4月 1 日至 4月 30日的一卡通資料
一共3個檔案:data1.csv、data2.csv、data3.csv
4. 資料預處理
將附件中的
data1.csv、data2.csv、data3.csv三份檔案載入到分析環境,對照附錄一,理解欄位含義。探查資料質量並進行缺失值和異常值等方面的必要處理。將處理結果儲存為“task1_1_X.csv”(如果包含多張資料表,X可從
1 開始往後編號),並在報告中描述處理過程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
data1.head(3)
data1.columns = ['序號', '校園卡號', '性別', '專業名稱', '門禁卡號']
data1.dtypes
data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)
將 data1.csv中的學生個人資訊與 data2.csv中的消費記錄建立關聯,處理結果儲存為“task1_2_1.csv”;將 data1.csv
中的學生個人資訊與data3.csv 中的門禁進出記錄建立關聯,處理結果儲存為“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5. 資料分析
5.1 食堂就餐行為分析
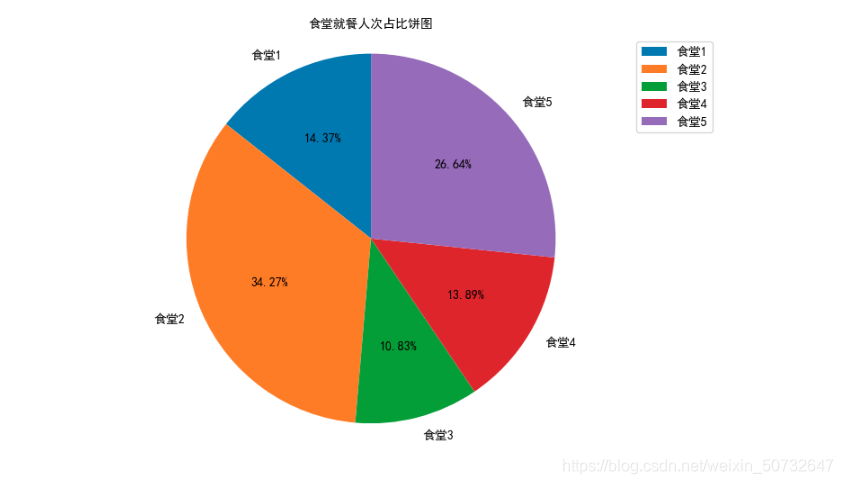
繪製各食堂就餐人次的佔比餅圖,分析學生早中晚餐的就餐地點是否有顯著差別,並在報告中進行描述。(提示:時間間隔非常接近的多次刷卡記錄可能為一次就餐行為)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()
import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入圖片
%matplotlib inline
# 提高解析度
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消費地點'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消費地點'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消費地點'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消費地點'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消費地點'].apply(str).str.contains('第五食堂').sum()
# 繪製餅圖
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 建立畫布
plt.figure(figsize=(10, 6), dpi=50)
# 繪製餅圖
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 顯示圖例
plt.legend(prop=font)
# 新增標題
plt.title("食堂就餐人次佔比餅圖", fontproperties=font)
# 餅圖保持圓形
plt.axis('equal')
# 顯示影象
plt.show()
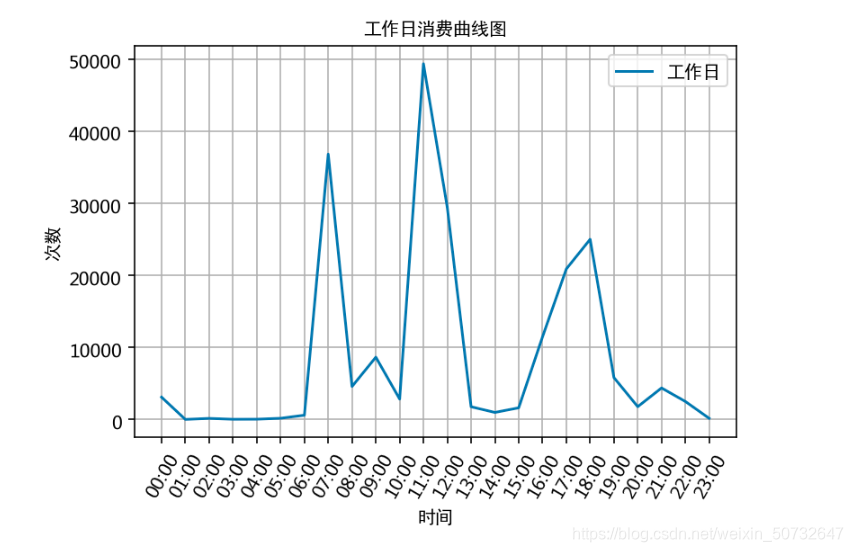
通過食堂刷卡記錄,分別繪製工作日和非工作日食堂就餐時間曲線圖,分析食堂早中晚餐的就餐峰值,並在報告中進行描述。
# 對data中消費時間資料進行時間格式轉換,轉換後可作運算,coerce將無效解析設定為NaT
data.loc[:,'消費時間'] = pd.to_datetime(data.loc[:,'消費時間'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 建立一個消費星期列,根據消費時間計算出消費時間是星期幾,Monday=1, Sunday=7
data['消費星期'] = data['消費時間'].dt.dayofweek + 1
data.head(3)
# 以週一至週五作為工作日,週六日作為非工作日,拆分為兩組資料
work_day_query = data.loc[:,'消費星期'] <= 5
unwork_day_query = data.loc[:,'消費星期'] > 5
work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 計算工作日消費時間對應的各時間的消費次數
work_day_times = []
for i in range(24):
work_day_times.append(work_day_data['消費時間'].apply(str).str.contains(' {:02d}:'.format(i)).sum())
# 以時間段作為x軸,同一時間段出現的次數和作為y軸,作曲線圖
x = []
for i in range(24):
x.append('{:02d}:00'.format(i))
# 繪圖
plt.plot(x, work_day_times, label='工作日')
# x,y軸標籤
plt.xlabel('時間', fontproperties=font);
plt.ylabel('次數', fontproperties=font)
# 標題
plt.title('工作日消費曲線圖', fontproperties=font)
# x軸傾斜60度
plt.xticks(rotation=60)
# 顯示label
plt.legend(prop=font)
# 加網格
plt.grid()
# 計算飛工作日消費時間對應的各時間的消費次數
unwork_day_times = []
for i in range(24):
unwork_day_times.append(unwork_day_data['消費時間'].apply(str).str.contains(' {:02d}:'.format(i)).sum())
# 以時間段作為x軸,同一時間段出現的次數和作為y軸,作曲線圖
x = []
for i in range(24):
x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('時間', fontproperties=font);
plt.ylabel('次數', fontproperties=font)
plt.title('非工作日消費曲線圖', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
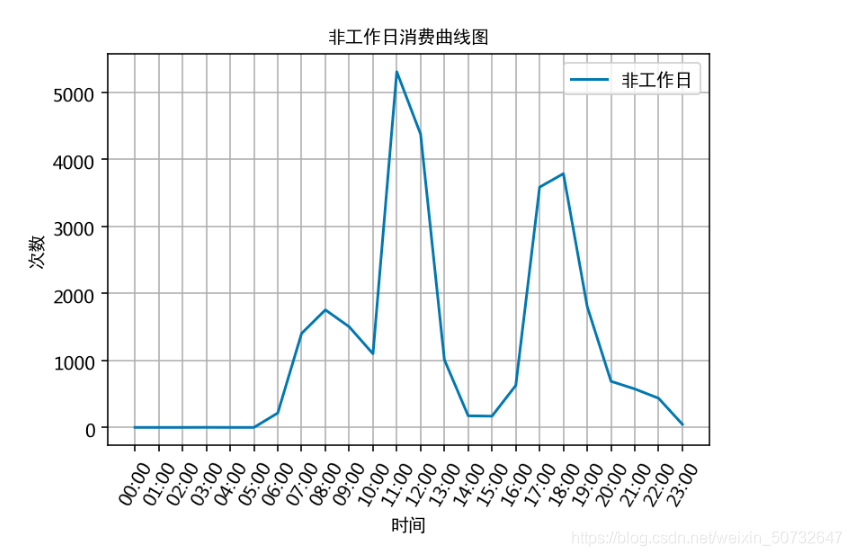
根據上述分析的結果,很容易為食堂的運營提供建議,比如錯開高峰等等。
5.2 學生消費行為分析
根據學生的整體校園消費資料,計算本月人均刷卡頻次和人均消費額,並選擇 3個專業,分析不同專業間不同性別學生群體的消費特點。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 計算人均刷卡頻次(總刷卡次數/學生總人數)
cost_count = data['消費時間'].count()
student_count = data['校園卡號'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count
# 計算人均消費額(總消費金額/學生總人數)
cost_sum = data['消費金額'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money
# 選擇消費次數最多的3個專業進行分析
data['專業名稱'].value_counts(dropna=False)
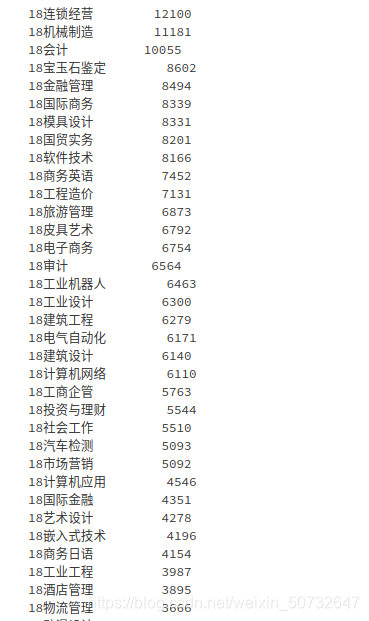
# 消費次數最多的3個專業為 連鎖經營、機械製造、會計
major1 = data['專業名稱'].apply(str).str.contains('18連鎖經營')
major2 = data['專業名稱'].apply(str).str.contains('18機械製造')
major3 = data['專業名稱'].apply(str).str.contains('18會計')
major4 = data['專業名稱'].apply(str).str.contains('18機械製造(學徒)')
data_new = data[(major1 | major2 | major3) ^ major4]
data_new['專業名稱'].value_counts(dropna=False)
分析 每個專業,不同性別 的學生消費特點
data_male = data_new[data_new['性別'] == '男']
data_female = data_new[data_new['性別'] == '女']
data_female.head()
根據學生的整體校園消費行為,選擇合適的特徵,構建聚類模型,分析每一類學生群體的消費特點。
data['專業名稱'].value_counts(dropna=False).count()
# 選擇特徵:性別、總消費金額、總消費次數
data_1 = data[['校園卡號','性別']].drop_duplicates().reset_index(drop=True)
data_1['性別'] = data_1['性別'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校園卡號'], inplace=True)
data_2 = data.groupby('校園卡號').sum()[['消費金額']]
data_2.columns = ['總消費金額']
data_3 = data.groupby('校園卡號').count()[['消費時間']]
data_3.columns = ['總消費次數']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()
# 構建聚類模型
from sklearn.cluster import KMeans
# k為聚類類別,iteration為聚類最大迴圈次數,data_zs為標準化後的資料
k = 3 # 分成幾類可以在此處調整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs為併發數
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1統計各個類別的數目,r2找出聚類中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['類別數目']
# 選出消費總額最低的500名學生的消費資訊
data_500 = data.groupby('校園卡號').sum()[['消費金額']]
data_500.sort_values(by=['消費金額'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校園卡號'].isin(data_500_index)]
data_500.head(10)
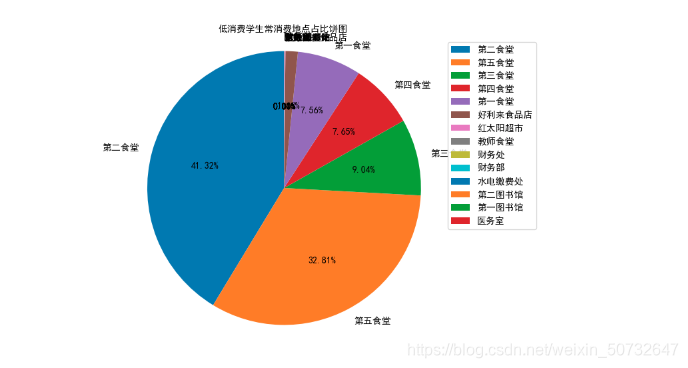
# 繪製餅圖
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 建立畫布
plt.figure(figsize=(10, 6), dpi=50)
# 繪製餅圖
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 顯示圖例
plt.legend(prop=font)
# 新增標題
plt.title("低消費學生常消費地點佔比餅圖", fontproperties=font)
# 餅圖保持圓形
plt.axis('equal')
# 顯示影象
plt.show()