
【Excel】資料分析工具庫
文章目錄
-
* 一、工具庫簡介-
* 1、作用- 2、安裝
- 3、統計方法歸納
- 二、描述性統計分析
-
* 1、介紹- 2、操作
- 三、直方圖
-
* 1、介紹- 2、操作
- 四、抽樣分析
-
* 1、介紹- 2、操作
- 五、相關分析
-
* 1、介紹- 2、操作
- 六、迴歸分析
-
* 1、介紹- 2、操作
-
* 1)簡單線性迴歸- 2)多重線性迴歸
- 七、移動平均
-
* 1、介紹- 2、操作
- 八、指數平滑
-
* 1、介紹- 2、操作
-
一、工具庫簡介
1、作用
便於複雜資料統計分析,可以完成描述統計、直方圖、相關係數、移動平均、指數平滑、迴歸等19中統計分析方法。但是與專業的統計分析軟體相比,資料量和複雜程度有限。
2、安裝
步驟:【檔案】-【選項】-【載入項】-【Excel載入項】-轉到-勾選【分析工具庫】【分析工具庫-vba】
位置:【資料】-【資料分析】

3、統計方法歸納

二、描述性統計分析
1、介紹
描述統計分析的常用指標有平均數、中位數、中樞、標準差、方差等,提供分析物件資料的集中程度和離散程度等資訊。
2、操作
-
位置
【資料】-【資料分析】-【描述統計】 -
引數
1)輸入引數
-
輸入區域 - 要進行描述統計的資料區域
-
分組方式 - 選擇區域是按列還是按行
-
標誌位於第一行:勾選後表示第一行是欄位名
2)輸入引數 -
輸出區域/新工作表組/新工作表 - 描述統計值輸出的位置
-
彙總統計 - 平均、標準誤差、中位數、眾數、標準差、方差、峰度、偏度、區域、最小值、最大值、求和、觀測數
-
平均數置信度 - 指總體引數值落在樣本統計值某一區間的概率,常用95%或90%
-
第k大(小)值:第k位的最大(小)值

注意 :與正態分佈相比(峰度=0,偏度=0)
峰度>0,呈尖峭峰分佈;峰度<0,成平闊峰分佈
偏度>0,呈高峰偏左,長尾向右延,正偏態分佈;偏度<0,呈高峰偏右,長尾向左延,負偏態分佈
如圖,該組資料呈平闊峰負偏態分佈。
三、直方圖
1、介紹
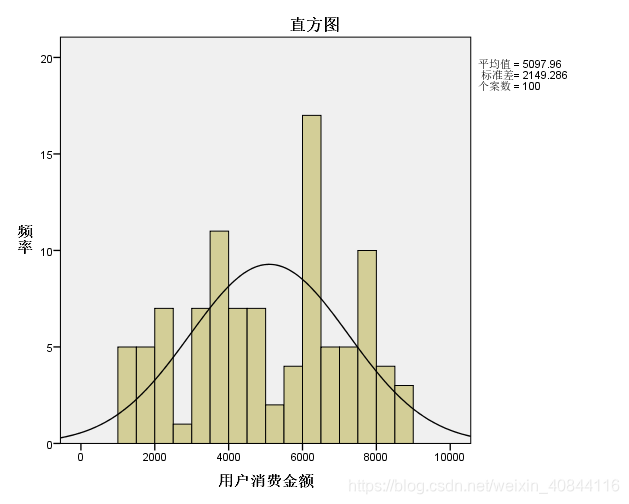
直方圖用於展示資料分佈,用矩形的寬度和高度表示頻數分佈,橫軸表示資料分組,縱軸表示頻數或頻率。
2、操作
-
定義組距
-
位置:【資料】-【資料分析】-【直方圖】
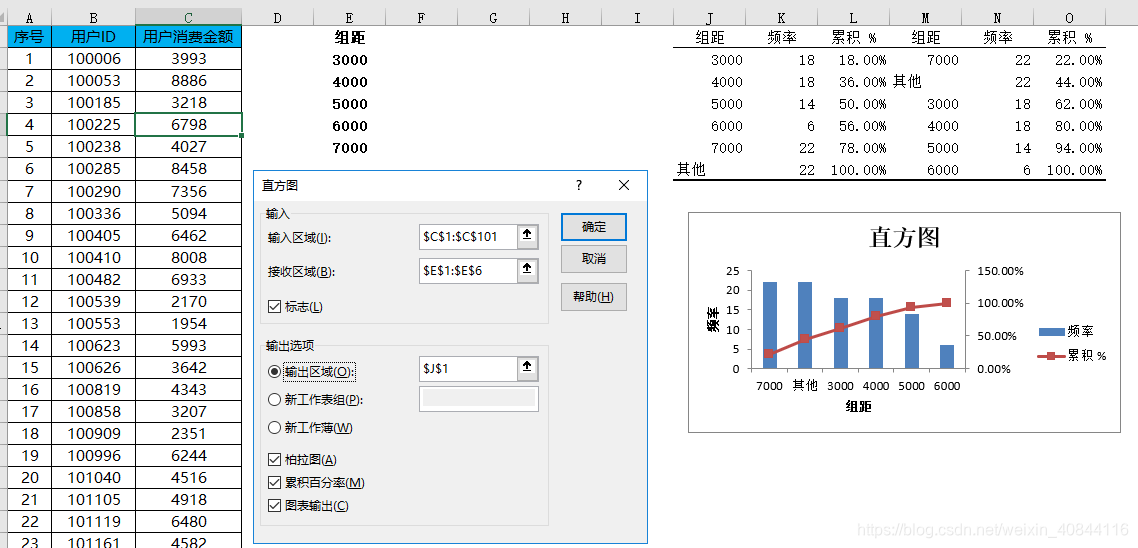 -
引數
- 接收區域:組距資料區域
- 標誌:輸入區域和接收區域中包含標題則勾選
- 柏拉圖:組距按照頻數從大到小排列
- 累積百分率:頻數累計百分率
- 圖表輸出:輸出圖表
四、抽樣分析
1、介紹
rand函式可以實現隨機抽取資料,但無法實現有規律抽取。“抽樣”分析工具可以解決這個問題。
2、操作
-
位置:【資料】-【資料分析】-【抽樣】
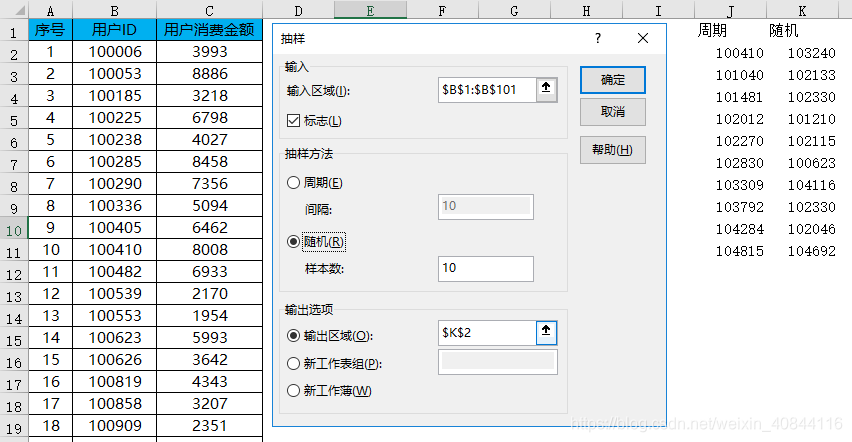 -
引數
- 抽樣方法-週期:輸入週期間隔,抽取間隔位置上的數
- 抽樣方法-隨機:有放回的方式,任何數值有可能被多次抽取。
五、相關分析
1、介紹
相關關係現象之間存在的非嚴格的、不確定的依存關係。
相關分析是研究兩個或兩個以上隨機變數之間相互依存的方向和密切程度的方法,直線相關用相關係數表示,曲線相關用相關指數表示,多重相關用複相關係數表示。
相關係數就是反應變數之間先行相關強度的一個度量指標,用r表示,r範圍[-1,1]。
2、操作
-
位置:【資料】-【資料分析】-【抽樣】
 -
引數
- 分組方式:根據輸入區域,選擇的是兩列資料,因此選擇逐列。
- 解讀
矩陣的行列交叉處就是兩個變數之間的相關係數。
六、迴歸分析
1、介紹
迴歸函式關係是指現象之間存在的依存關係中,對於某一變數的每一個數值,都有另一個變數值與之相對應,並且可以用一個數學表示式表示出來。
迴歸分析是研究自變數和因變數之間的關係形式的分析方法,主要通過建立因變數y與自變數Xi(i=1,2,3,…)之間的迴歸模型,來預測因變數Y的發展趨勢。
迴歸分析與相關分析的聯絡:均為研究及測量兩個及兩個以上變數之間關係的方法,實際工作中,一般先進行相關分析,極端相關係數,然後你和迴歸模型,進行顯著性檢驗,最後用迴歸模型推算或預測。
迴歸分析與相關分析的區別:相關分析不區分自變數和因變數,迴歸分析不僅可以揭示兩個變數之間的影響大小,還可以由迴歸模型進行預測。

迴歸分析五個步驟:
2、操作
1)簡單線性迴歸
- 公式
Y=a+bX+ε
- Y——因變數
- X——自變數
- a——常數項,迴歸直線在縱座標上的截距
- b——迴歸係數,迴歸直線的斜率
- ε——隨機誤差,隨機因素對因變數所產生的影響
-
繪製散點圖
一般做線性迴歸之前,需要先用散點圖檢視資料之間是否具有先行分佈特徵。 -
新增趨勢線,通過繪製趨勢線建立迴歸模型
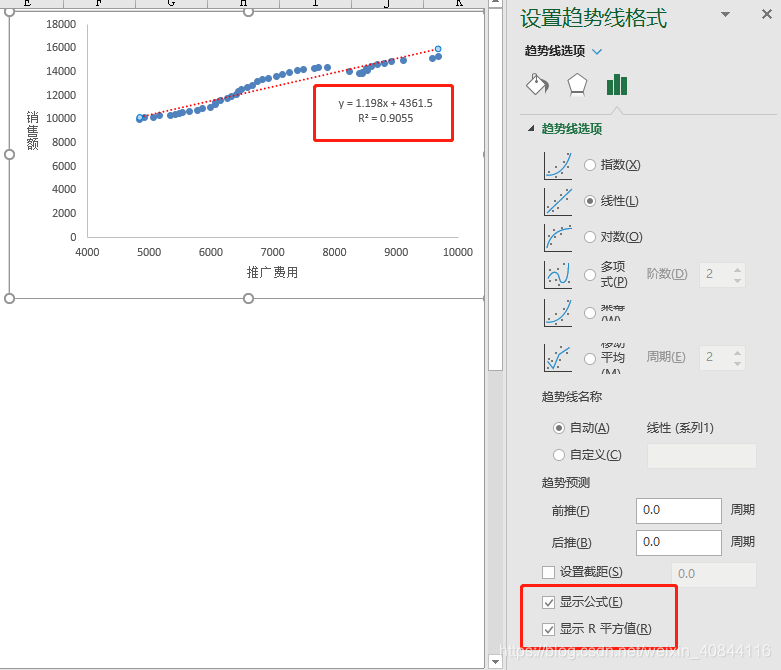 -
檢驗
位置:【資料】-【資料分析】-【移動平均】

引數
- 殘差:觀測值和預測值之間的差
- 標準殘差:(殘差-殘差的均值)/殘差的標準差
- 殘差圖:繪製散點圖,橫座標不變,縱座標是殘差值。如果點都分佈在以0為橫軸的直線上下散佈,則表示擬合合理。
- 線性擬合圖:橫軸不變,以因變數和預測值為縱座標繪製散點圖。
- 正態概率圖:用於檢查一組資料是否服從正態分佈,以因變數的百分位排名為橫座標,以因變數為縱座標繪製散點圖。
解讀
-
迴歸統計表
衡量相關程度,迴歸模型的擬合效果。
 -
方差分析表
判斷迴歸模型的迴歸效果,即線性關係是否顯著,線性模型描述得是否恰當。
-
迴歸係數表
用於迴歸模型的描述和迴歸係數的顯著性檢驗。
2)多重線性迴歸
多重線性迴歸模型是指一個因變數和多個自動變數的迴歸模型,與包含兩個或兩個以上因變數的多元迴歸模型區分。
-
公式
Y=a+b 1 X 1 +b 2 X 2 +…+b n X n +ε -
Y——因變數
-
X n ——第n個自變數
-
a——常數項,迴歸直線在縱座標上的截距
-
b n ——第n個迴歸係數
-
ε——隨機誤差,隨機因素對因變數所產生的影響
-
引數
 -
解讀

七、移動平均
1、介紹
除了相關分析和迴歸分析這種找變數之間關係的預測方法,還有根據時間發展進行預測,即時間序列預測。特徵如下:
- 假設事物發展趨勢會延伸到未來;
- 預測所依據的資料具有不規則性;
- 不考慮事物發展之間的因果關係。
時間序列預測主要包括移動平均法、指數平滑法、趨勢外推法、季節變動法等。
移動平均法根據時間序列逐期推移,依次計算包含一定奇書的平均值,形成平均值時間序列。
2、操作
- 公式
Y t =(X t-1 + X t-2 + X t-3 +…+ X t-n )/n
- Y t ——對下一期的預測值
- n——移動平均的時期個數
- a——常數項,迴歸直線在縱座標上的截距
- X t-n ——前n期實際值
-
位置
【資料】-【資料分析】-【移動平均】 -
引數

- 間隔:指定n組資料來計算平均值
- 圖表輸出:由實際資料和移動平均值形成的直線圖輸出。(注意這個圖表述可能不準確)
- 標準誤差:實際資料與預測資料的標準差,越小表明資料越準確。
- 結果

八、指數平滑
1、介紹
改良的加權平均法,在不捨棄歷史資料的前提下,對離預測期較近的歷史資料基於較大的權屬,權數由近到遠按指數規律遞減。
2、操作
- 公式
Y t =αX t-1 + (1-α)Y t-1 = (1-β)X t-1 + βY t-1
- Y t ——時間t的平滑值
- X t-1 ——時間t-1的實際值
- Y t-1 ——時間t-1的平滑值
- α——平滑係數
- β——阻尼係數
注意:β=1-α,阻尼係數越大,近期實際值對預測結果的影響越大。實際應用中,阻尼係數是根據時間序列的變化特性來選取的。如果時間序列資料波動不大,比較平穩,則阻尼係數應取小一些,如0.1-0.3;反之,時間序列資料具有迅速且明顯的變動傾向,則阻尼係數,如0.6~0.9.
-
位置
【資料】-【資料分析】-【指數平滑】  -
結果

多個阻尼係數對比