
基於PYTHON SKLEARN應用邏輯迴歸對泰坦尼克乘客存活做預測(一)
Python 的sklearn庫包含許多可用於機器學習的工具,本文以經典的泰坦尼克號問題為例,來說明在Python中使用sklearn做機器學習的一般流程。由於本人對機器學習瞭解還不深,對於本文內容如有任何建議或意見,歡迎提出!閒話少說,咱們立即進入主題。
1. 讀取並檢視資料
泰坦尼克號問題,Kaggle上提供了較為詳細的資料說明和下載地址,本文這裡不再贅述。有需要了解的同學請移步這裡。
首先,我們匯入需要用到的庫檔案,為之後工作做準備:
| 1 2 3 4 5 6 7 8 9 10 |
# 匯入後續需要用到的庫檔案
import numpy as np
import pandas as pdimport seaborn as sns
import matplotlib.pylab as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report |
然後讀取資料並檢視:
| 1 2 3 4 |
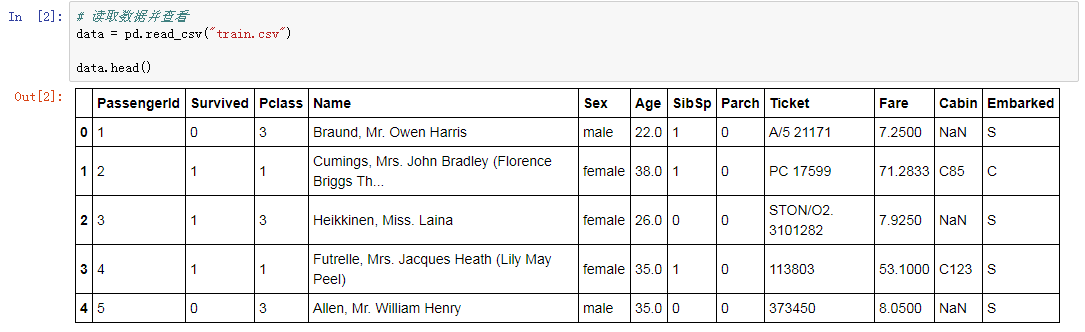
# 讀取資料並檢視
data = pd.read_csv("train.csv")
data.head()
|
{kind=link}
| 1 2 |
# 檢視資料行列
data.shape
|
輸出:(891, 12)
說明有891行,12列。
檢視缺失值的情況:
| 1 2 |
# 檢查NA值的情況
data.isnull().sum()
|
{kind=link}
可以看到Age, Cabin, Embarked這三列均存在缺失值,其中Cabin列缺失很嚴重。不過這列表示船艙號,直觀上我們覺得這個跟最終是否能倖存關係不大,所以缺失就缺失吧。
2. 特徵選取
泰坦尼克號這個資料集中,有乘客ID、是否存活、船票等級、乘客姓名、乘客性別、年齡、船上兄弟姊妹或配偶個數、床上父母或子女個數、船票號碼、船票價格、船艙號、上船港口等資料。
顯然,是否存活是我們將要預測的量,而乘客ID、乘客姓名、船票號碼、船艙號,我們覺得跟最終是否能存活關係不大,於是忽略它們,剩餘其他的列作為後續模型訓練的特徵。
選取特徵並檢視選取後的資料:
| 1 2 3 |
# 選取資料集中有用的特徵
data = data.drop(labels=['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
data.head()
|
執行後可以看到:我們後面建模用來訓練的資料將會來自於這裡。
3. 缺失值處理
前面我們看到,原資料中有不少缺失值,這裡我們選最簡單的缺失值處理辦法,即將包含缺失值的行全部捨棄:
| 1 2 |
# 去除有缺失值的行
data = data.dropna()
|
4. 離散特徵處理
上邊留下來的列,Pclass表示船票等級,為有序分類變數,已經是數值型;Sex和Embarked為無序分類變數,為字元型;Age、SibSp、Parch、Fare為連續變數。
sklearn中模型最後訓練的資料需要是數值型的,因此Sex和Embarked這兩列的數值需要轉換為數值型。
我們直接用pandas中的get_dummies即可對無序分類變數進行編碼:
| 1 2 |
# 分類變數編碼
data_dummy = pd.get_dummies(data[['Sex', 'Embarked']])
|
編碼後與原來其他列的資料重新拼接起來:
# 編碼後和原來其他列資料拼接
| 1 2 |
data_conti = pd.DataFrame(data, columns=['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare'], index=data.index)
data = data_conti.join(data_dummy)
|
5. 分割訓練集和測試集
資料集基本行列都確定之後,我們就可以進行分割了,這裡將30%的資料集作為測試集:
| 1 2 3 |
X = data.iloc[:, 1:]
y = data.iloc[:, 0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
|
6. 連續特徵處理
要保證模型訓練時快速收斂,我們需要對資料集中連續的資料列進行縮放,這裡使用標準化的方法:
| 1 2 3 4 5 6 7 |
# 標準化
stdsc = StandardScaler()
X_train_conti_std = stdsc.fit_transform(X_train[['Age', 'SibSp', 'Parch', 'Fare']])
X_test_conti_std = stdsc.fit_transform(X_test[['Age', 'SibSp', 'Parch', 'Fare']])
# 將ndarray轉為dataframe
X_train_conti_std = pd.DataFrame(data=X_train_conti_std, columns=['Age', 'SibSp', 'Parch', 'Fare'], index=X_train.index)
X_test_conti_std = pd.DataFrame(data=X_test_conti_std, columns=['Age', 'SibSp', 'Parch', 'Fare'], index=X_test.index)
|
最後我們將處理好的資料列再次拼接起來,用於接下來模型的訓練:
| 1 2 3 4 5 6 7 8 9 10 11 |
# 有序分類變數Pclass
X_train_cat = X_train[['Pclass']]
X_test_cat = X_test[['Pclass']]
# 無序已編碼的分類變數
X_train_dummy = X_train[['Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
X_test_dummy = X_test[['Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
# 拼接為dataframe
X_train_set = [X_train_cat, X_train_conti_std, X_train_dummy]
X_test_set = [X_test_cat, X_test_conti_std, X_test_dummy]
X_train = pd.concat(X_train_set, axis=1)
X_test = pd.concat(X_test_set, axis=1)
|
7. 建模和預測
使用sklearn中邏輯迴歸模型進行訓練並做預測:
| 1 2 3 4 5 6 7 8 |
# 基於訓練集使用邏輯迴歸建模
classifier = LogisticRegression(random_state=0)
classifier.fit(X_train, y_train)
# 將模型應用於測試集並檢視混淆矩陣
y_pred = classifier.predict(X_test)
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)
|
檢視模型的準確率:
| 1 2 |
# 在測試集上的準確率
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(classifier.score(X_test, y_test)))
|
執行後得到:
Accuracy of logistic regression classifier on test set: 0.77
檢視模型的效能指標:
| 1 |
print(classification_report(y_test, y_pred))
|
執行後得到:
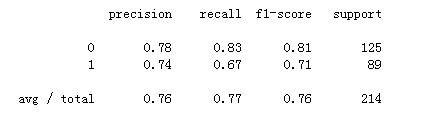{kind=link}
至此,基於邏輯迴歸來預測泰坦尼克號乘客存活基本就完成了。但是這個模型準確率僅76%,還有優化空間。比如這裡特徵選取比較主觀,模型訓練時也直接用的預設引數,沒有調參使模型更優。此外,機器學習中分類有關的演算法很多,比如支援向量機、決策樹、隨機森林、樸素貝葉斯等,邏輯迴歸並不一定最適合這個問題。
因此,我們將在之後嘗試對這個模型進行優化,以使模型預測準確率更高一些。