
MYBATIS 簡單整理與回顧
阿新 • • 發佈:2017-05-06
生成 ssi 包含 一對一 收集 soc 讀取配置 close 排序 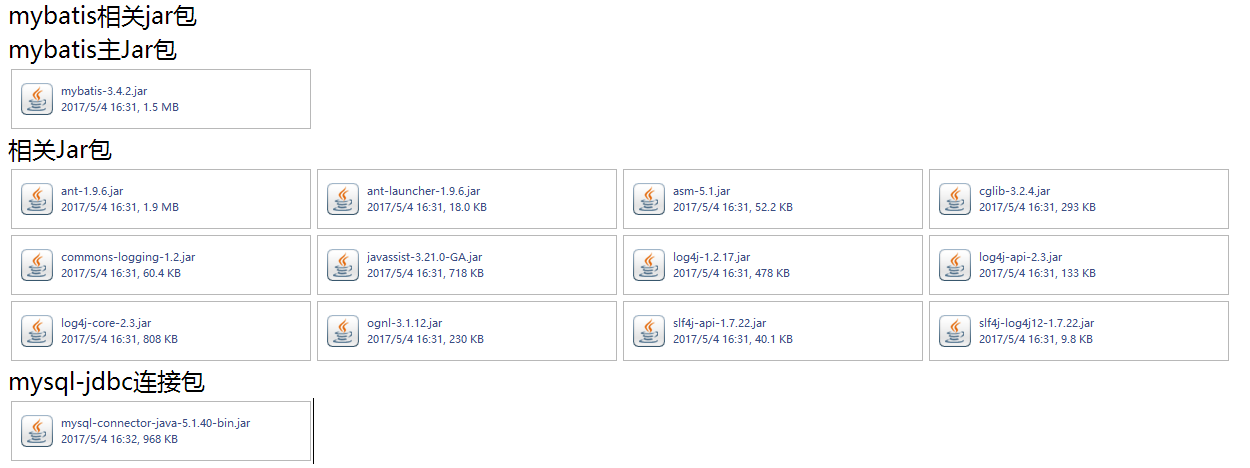






這兩天簡單整理了一下MyBatis
相關api和jar包這裏提供一個下載地址,免得找了
鏈接:http://pan.baidu.com/s/1jIl1KaE 密碼:d2yl
A.簡單搭建跑項目
2.進行相關xml配置
放在根目錄下


<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jhdx.mapper.T_CustomerMapper">
<!-- 通過編號查詢用戶 -->
<select id="getAllCustomer" resultType="Customer">
select
View Code
4.測試,讀取配置文件
String resource = "mybatis-config.xml";
InputStream inputStream
View Code
這種是通過代理方式
當然也可以直接通過session讀取xml寫的方法
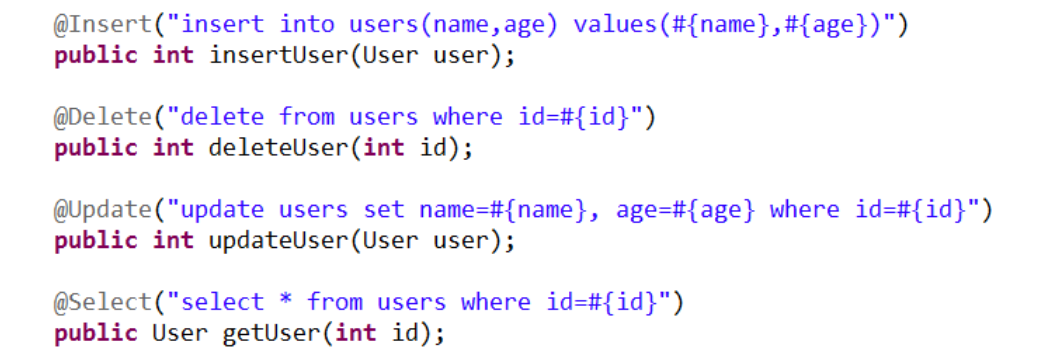
B.一些技巧 1.直接使用註解進行sql的編寫和映射 在dao接口裏直接使用註解
當然,在配置文件還需要配置一下
<mappers>
<!-- 配置映射文件 -->
<mapper resource="com/jhdx/mapper/T_customerMapper.xml" />
<mapper class="com.jhdx.mapper.T_customerMapper" />
</mappers>
View Code
如上圖,mappers裏配置一個class即可
2.關於模糊查詢
<select id="getCustomerByName" parameterType="java.lang.String" resultType="Customer">
select * from t_customer where name like "%"#{name}"%"
</select>
View Code
3.關於一對一的關聯 a)對結果進行處理,實際只執行一條sql語句,api叫嵌套結果
配置一個resultMap即可 標簽分別是數據庫的字段與實體類的映射 <association></association>標簽裏是對對象的映射 註意javaType指的是實體類 column指的是 表連接時使用的字段 例如上圖的例子中就是c.teacher_id=t.t_id 使用的是teacher_id 一般配置具體字段的標簽使用<id></id>配置主鍵Id <result></result>配置其他的字段 裏面的屬性分別是 property對應的是實體類的成員變量 column對應的是數據庫的字段 b)對過程進行處理,實際執行多條sql語句,api叫嵌套查詢
如圖,首先執行的是select * from Class where c_id=#{id} 接著對結果集進行封裝 封裝到teacher的時候再執行一條查詢語句 註意多了一個select的屬性 指的就是第二條查詢語句 參數通過 teacher_id傳遞過去 也就是屬性裏column的值傳遞過去 4.關於一對多的關聯 a)對結果進行處理,實際只執行一條sql語句,api叫嵌套結果
其他和上面的一對一一樣 只是配置 一對多 多的集合的時候 使用 <collection></collection>標簽 註意屬性了不是javaType而是ofType ,當然實體類也要配置相應的集合成員變量 然後column可以不指定 也可以指定 指定的列名是 根據這個列名可以查詢到相關集合對象的那個列 裏面的標簽還是作相應 實體類的成員變量和數據庫字段的對應 b)對過程進行處理,實際執行多條sql語句,api叫嵌套查詢
和1對1類似 多了一個 collection標簽 註意select 選擇的第二條查詢語句id以及column是用來傳值的 如果說實體類的屬性沒有設置全的話 查詢語句要自己設置別名(與實體類一致) 否則會映射失敗
<resultMap id="BaseResultMap" type="com.jhdx.model.entity.User">
<id column="userId" jdbcType="INTEGER" property="userid" />
<result column="userName" jdbcType="VARCHAR" property="username" />
<result column="userPwd" jdbcType="VARCHAR" property="userpwd" />
<collection property="contents" ofType="Content" column="userId" select="selectAllContents"></collection>
</resultMap>
<select id="selectAllContents" resultType="Content" parameterType="java.lang.Integer">
select * from content where userId=#{userId}
</select>
View Code
5.關於sql標簽 這個元素可以被用來定義可重用的 SQL 代碼段,可以包含在其他語句中。它可以被靜態地(在加載參數) 參數化. 不同的屬性值通過包含的實例變化. 比如: <sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql> 這個 SQL 片段可以被包含在其他語句中,例如:
<select id="selectUsers" resultType="map"> select <include refid="userColumns"><property name="alias" value="t1"/></include>, <include refid="userColumns"><property name="alias" value="t2"/></include> from some_table t1 cross join some_table t2 </select>View Code 屬性值可以用於包含的refid屬性或者包含的字句裏面的屬性值,例如:
<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>
View Code
5.關於動態sql
常用的有if,choose(when,otherwise),trim(where,set),foreach,bind
用法類似於jstl標簽
詳情還是翻看api吧,裏面的例子簡單明了,這裏就不直接列舉了
6.關於傳入多個參數的問題
常用的有三種方法
1.使用#{0},#{1}....
DAO層的函數方法 Public User selectUser(String name,String area); 對應的Mapper.xml <select id="selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{0} and user_area=#{1} </select>View Code
2.使用map進行傳遞(不建議,無法通過接口看到傳遞的是什麽參數)
此方法采用Map傳多參數. Dao層的函數方法 Public User selectUser(Map paramMap); 對應的Mapper.xml <select id=" selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{userName,jdbcType=VARCHAR} and user_area=#{userArea,jdbcType=VARCHAR} </select> Service層調用 Private User xxxSelectUser(){ Map paramMap=new hashMap(); paramMap.put(“userName”,”對應具體的參數值”); paramMap.put(“userArea”,”對應具體的參數值”); User user=xxx. selectUser(paramMap);}View Code
3.使用註解進行傳遞(建議,簡單明了)
Dao層的函數方法 Public User selectUser(@param(“userName”)Stringname,@parm(“userArea”String area); 對應的Mapper.xml <select id=" selectUser" resultMap="BaseResultMap"> select * from user_user_t where user_name = #{userName,jdbcType=VARCHAR} and user_area=#{userArea,jdbcType=VARCHAR} </select>View Code
7.關於註解與緩存 [email protected],@insert,@delete,@update,@param,@result,@resultMap 這裏貼個地址吧,講的比較詳細也比較好 http://www.cnblogs.com/ibook360/archive/2012/07/16/2594056.html 緩存詳情還是要翻api 可以簡單地配置 <cache/> 這個簡單語句的效果如下:
- ? 映射語句文件中的所有select 語句將會被緩存。
- ? 映射語句文件中的所有insert,update 和delete 語句會刷新緩存。
- ? 緩存會使用Least Recently Used(LRU,最近最少使用的)算法來收回。
- ? 根據時間表(比如no Flush Interval,沒有刷新間隔), 緩存不會以任何時間順序來刷新。
- ? 緩存會存儲列表集合或對象(無論查詢方法返回什麽)的1024 個引用。
- 緩存會被視為是read/write(可讀 /可寫 )的緩存,意味著對象檢索不是共享的 ,而 且可以 安全地被調用者修改 ,而不幹擾其他調用者或線程所做的潛在修改。
- ? LRU– 最近最少使用的:移除最長時間不被使用的對象。
- ? FIFO– 先進先出:按對象進入緩存的順序來移除它們。
- ? SOFT– 軟引用:移除基於垃圾回收器狀態和軟引用規則的對象。
- ? WEAK– 弱引用:更積極地移除基於垃圾收集器狀態和弱引用規則的對象。
1. mybatis中 jdbcType 時間類型
當jdbcType = DATE 時, 只傳入了 年月日
jdbcType = TIMESTAMP , 年月日+ 時分秒
使用時, 沒有加jdbcType 正常,
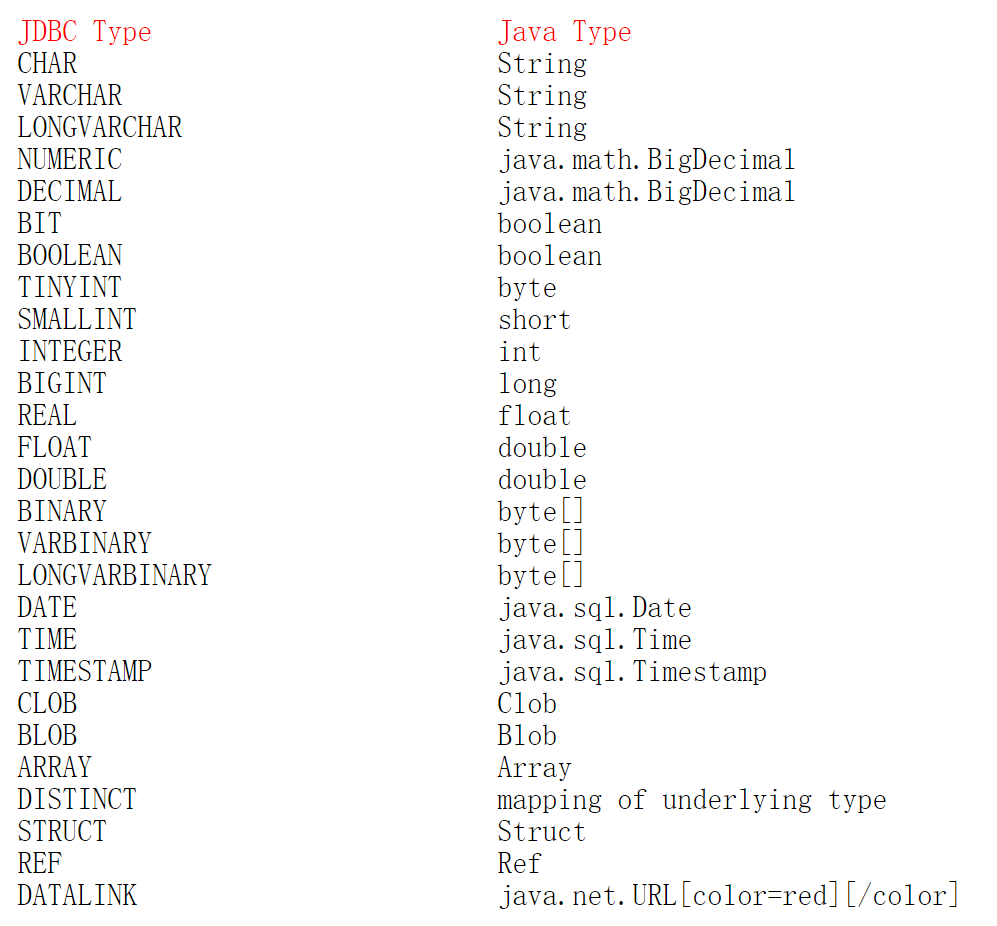
加上jdbcType原因(網絡): 當傳入字段值為null,時,需要加入. 否則報錯. 涉及到數據類型可能要轉換的時候帶上會好些,比如你傳入的是Strring對象,而數據庫是decimal, 這樣能轉換為正確的類型,防止類型不匹配而使用不了某些索引 下面賦一個javaType與jdbcType的對應關系
2.關於MyBaits中${}與#{}的區別
1. #將傳入的數據都當成一個字符串,會對自動傳入的數據加一個雙引號。如:order by #user_id#,如果傳入的值是111,那麽解析成sql時的值為order by "111", 如果傳入的值是id,則解析成的sql為order by "id".
2. $將傳入的數據直接顯示生成在sql中。如:order by $user_id$,如果傳入的值是111,那麽解析成sql時的值為order by user_id, 如果傳入的值是id,則解析成的sql為order by id.
3. #方式能夠很大程度防止sql註入。
4.$方式無法防止Sql註入。
5.$方式一般用於傳入數據庫對象,例如傳入表名.
6.一般能用#的就別用$.
MyBatis排序時使用order by 動態參數時需要註意,用$而不是#MYBATIS 簡單整理與回顧