
GBDT與LR融合提升廣告點擊率預估模型
阿新 • • 發佈:2017-05-07
所有 預測 其中 參考 ans 工作 方案 隨機 適合 1GBDT和LR融合
LR模型是線性的,處理能力有限,所以要想處理大規模問題,需要大量人力進行特征工程,組合相似的特征,例如user和Ad維度的特征進行組合。
GDBT天然適合做特征提取,因為GBDT由回歸樹組成所以, 每棵回歸樹就是天然的有區分性的特征及組合特征,然後給LR模型訓練,提高點擊率預估模型(很多公司技術發展應用過,本人認為dnn才是趨勢)。
例如,輸入樣本x,GBDT模型得到兩顆樹tree1和tree2,遍歷兩顆樹,每個葉子節點都是LR模型的一個維度特征,在求和每個葉子*權重及時LR模型的分類結果。
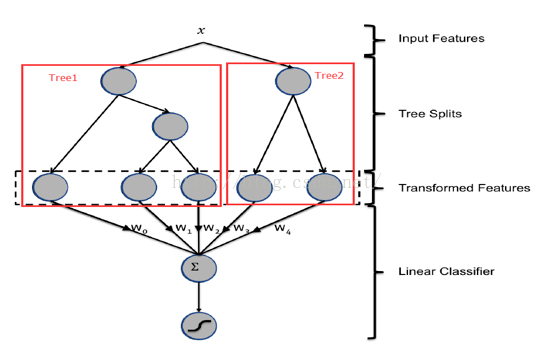
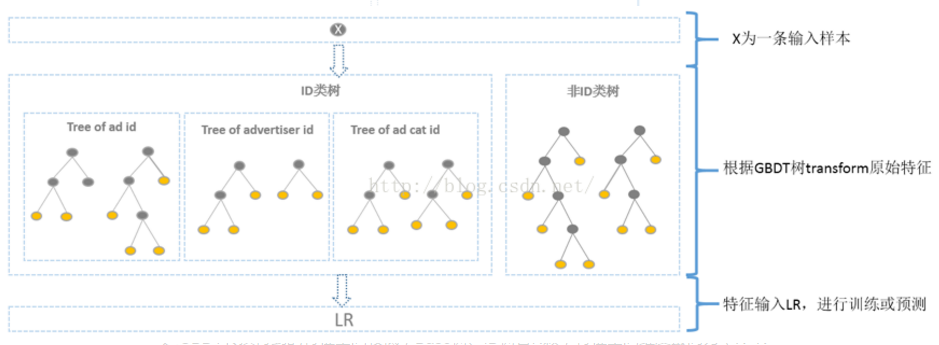
2廣告長尾性 1)gbdt和隨機森林rf的對比: rf主要選擇對大多數樣本有區分度的特征;gbdt的過程,前面樹針對大多數樣本有區分 ,後面樹針對殘差依然較大的樣本,即針少數的對長尾樣本。更適合ctr模型預估。 2)針對廣告的長尾性,廣告id這個特征就很重要,比如:某少量長尾用戶就喜歡點某類廣告主的廣告。 方案:分別針對ID類和非ID類建樹,ID類樹:用於發現曝光充分的ID對應的有區分性的特征及組合特征;非ID類樹:用於曝光較少的廣告。
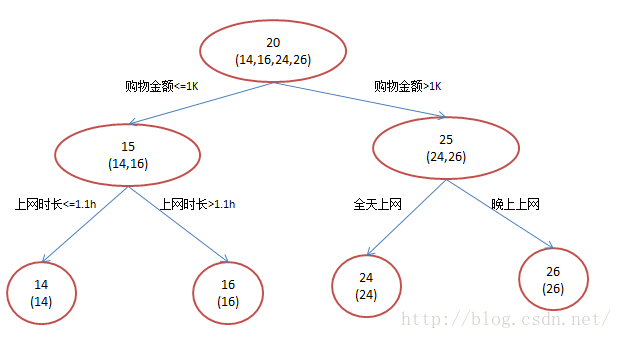
3gbdt得到的特征維度 維度會降低,總維度是所有葉子節點數之和。 4gdbt模型原理 1)BT回歸樹 年齡預測:簡單起見訓練集只有4個人,A,B,C,D,他們的年齡分別是14,16,24,26。其中A、B分別是高一和高三學生;C,D分別是應屆畢業生和工作兩年的員工。 1BT回歸樹:顯然容易過擬合,特征太細了,只要葉子允許夠多可以達到百分百的準確率,但性能並不好。
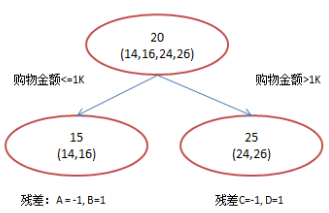
2)GDBT模型 (1)最小化均方誤差特,確定特征:購物金額的分割點:
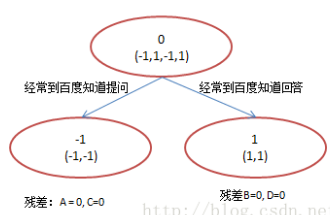
(2)計算殘差=預測值-真實值,真實值是葉子節點均值,特征:百度知道提問:
(3)殘差為0,停止叠代,輸出預測結果,真實值=初始值+殘差之和
A: 14歲高一學生,購物較少,經常問學長問題;預測年齡A = 15 – 1 = 14
B: 16歲高三學生;購物較少,經常被學弟問問題;預測年齡B = 15 + 1 = 16
C: 24歲應屆畢業生;購物較多,經常問師兄問題;預測年齡C = 25 – 1 = 24
D: 26歲工作兩年員工;購物較多,經常被師弟問問題;預測年齡D = 25 + 1 = 26 參考 http://www.jianshu.com/p/504acc6c410eGBDT與LR融合提升廣告點擊率預估模型