
程式化廣告交易中的點選率預估
指標
廣告點選率預估是程式化廣告交易框架的非常重要的元件,點選率預估主要有兩個層次的指標:
1. 排序指標。排序指標是最基本的指標,它決定了我們有沒有能力把最合適的廣告找出來去呈現給最合適的使用者。這個是變現的基礎,從技術上,我們用AUC來度量。
2. 數值指標。數值指標是進一步的指標,是競價環節進一步優化的基礎,一般DSP比較看中這個指標。如果我們對CTR普遍低估,我們出價會相對保守,從而使得預算花不出去或是花得太慢;如果我們對CTR普遍高估,我們的出價會相對激進,從而導致CPC太高。從技術上,我們有Facebook的NE(Normalized Entropy)還可以用OE(Observation Over Expectation)。

框架
工業界用得比較多的是基於LR的點選率預估策略,我覺得這其中一個重要的原因是可解釋性,當出現bad case時越簡單的模型越好debug,越可解釋,也就越可以有針對性地對這種bad case做改善。但雖然如此,我見到的做廣告的演算法工程師,很少有利用LR的這種好處做模型改善的,遺憾….. 最近DNN很熱,百度宣佈DNN做CTR預估相比LR產生了20%的benefit,我不知道比較的benchmark,但就機理上來講如果說DNN比原本傳統的人工feature engineering的LR高20%,我一點也不奇怪。但如果跟現在增加了FM和GBDT的自動高階特徵生成的LR相比,我覺得DNN未必有什麼優勢。畢竟看透了,DNN用線性組合+非線性函式(tanh/sigmoid etc.)來做高階特徵生成,GBDT + FM用樹和FM來做高階特徵生成,最後一層都是非線性變換。從場景上來講,可能在擬生物的應用上(如視、聽覺)上DNN這種高階特徵生成更好,在廣告這種情境下,我更傾向於GBDT + FM的方法。
整個CTR預估模組的框架,包含了exploit/explore的邏輯。

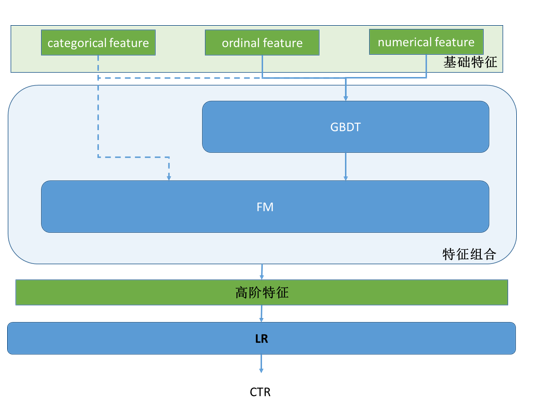
單純點選率預估演算法的框圖如下;
Step-by-step
1. 資料探索(data exploration)
主要是基礎特徵(raw feature/fundamental feature)的粗篩和規整。
展示廣告的場景可以表述為”在某場景下,通過某媒體向某使用者展示某廣告”,因此基礎特徵就在這四個範圍內尋找:
場景 – 當時場景,如何時何地,使用何種裝置,使用什麼瀏覽器等
廣告 – 包括廣告主特徵,廣告自身的特徵如campaign、創意、型別,是否重定向等
媒體 – 包括媒體(網頁、app等)的特徵、廣告位的特徵等
使用者 – 包括使用者畫像,使用者瀏覽歷史等
單特徵選擇的方法有下面幾種:
1. 簡單統計方法,統計特徵取值的覆蓋面和平衡度,對dominant取值現象很顯著的特徵,要選擇性地捨棄該特徵或者是歸併某些取值集到一個新的值,從而達到平衡的目的。
2. 特徵選擇指標,特徵選擇主要有兩個目的,一是去除冗餘的特徵,也就是特徵之間可能是互相冗餘的;二是去無用,有些特徵對CTR預估這個任務貢獻度很小或沒有,對於這類特徵選擇,要小小地做,寧不足而不過分,因為單特徵對任務貢獻度小,很有可能後面再組合特徵生成時與其他特徵組合生成很有效的組合特徵,所以做得不能太過。
a) 去冗餘。主要是特徵間的相關性,如Pearson相關性,或者指數迴歸(從泰勒定理的角度它可以模擬高階的多項式特徵)。
b) 去無用。主要是資訊增益比。
2. 特徵組合
兩派方法:
FM系列 - 對於categorical feature,一般把他們encode成one hot的形式,特徵組合適合用FM。
Tree系列 - 對於numerical feature和ordinal feature, 特徵組合可以使用決策樹類的,一般用random forest或GBDT。其中GBDT的效果應該更好,因為boosting方法會不斷增強對錯判樣本的區分能力。
對於廣告點選率預估,同時擁有這三類特徵。所以一個簡單的方法就是級聯地使用這兩個方法,更好地進行特徵組合。

3. LR
a. OWL-QN
這個是batch訓練的方法,主要用於處理L1正則下的LR最優化。
b. Online learning(FTRL and Facebook enhancement)
線上學習,及時反饋點選資訊,不斷演化LR模型,從而為新廣告更快收斂。
4. 預測CTR可信嗎?
任何一個特徵向量輸入到這個CTR預測演算法,演算法都會像模像樣地給你輸出一個預測CTR。但這個CTR真的可信嗎?我們知道機器學習是典型data driven的,當訓練資料中某種情況的資料不足時,這種情況下的預測值很有可能被其他資料拉偏。所以,肯定會有預測值不可信的情況,那我們怎麼判斷當前的預測CTR的可信度呢?
Google在提出FTRL演算法的同時伴隨提出了一個預測CTR可信度的方法,想法很簡單:訓練資料越多則可信度越高。下圖公式中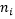 指訓練集中第i維feature非零的訓練向量的個數。normalization到[0, 1]的方法很多,需要根據總業務資料量以及先驗CTR來最終確定。
指訓練集中第i維feature非零的訓練向量的個數。normalization到[0, 1]的方法很多,需要根據總業務資料量以及先驗CTR來最終確定。
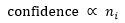
5. 修修補補
後面的事情就是在前述的框架的基礎上,根據bad case修修補補了。比如說,現在認為在不同的點選率區段,影響點選率的特徵的權重是一致的,但實際發現是不一樣的,就可以按照點選率的區間劃分,做分割槽間模型(據說阿里用的MLR就是這個東東)。這些都不出上面的框架,是在分析資料之後做的細化,逃不脫“分段逼近”這個大圈。