
juedaiyuer MNIST機器學習
MNIST是一個入門級的計算機視覺數據集,它包含各種手寫數字圖片:
1. MNIST數據集
MNIST,是不是聽起來特高端大氣,不知道這個是什麽東西?
== 手寫數字分類問題所要用到的(經典)MNIST數據集 ==
MNIST數據集的官網是Yann LeCun‘s website
自動下載和安裝這個數據集的python代碼
該段代碼在tensorflow/examples/tutorials/mnist/input_data.py
"""Functions for downloading and reading MNIST data."""from __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport gzipimport osimport tempfileimport numpyfrom six.moves import urllibfrom six.moves import xrange # pylint: disable=redefined-builtinimport tensorflow as tffrom tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
導入項目
import tensorflow.examples.tutorials.mnist.input_dataimport input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)2. 運行TensorFlow的InteractiveSession
使用TensorFlow之前,首先導入它:
import tensorflow as tfsess = tf.InteractiveSession()
3. 計算圖
為了在Python中進行高效的數值計算,我們通常會使用像NumPy一類的庫,將一些諸如矩陣乘法的耗時操作在Python環境的外部來計算,這些計算通常會通過其它語言並用更為高效的代碼來實現。
但遺憾的是,每一個操作切換回Python環境時仍需要不小的開銷。如果你想在GPU或者分布式環境中計算時,這一開銷更加可怖,這一開銷主要可能是用來進行數據遷移。
TensorFlow也是在Python外部完成其主要工作,但是進行了改進以避免這種開銷。其並沒有采用在Python外部獨立運行某個耗時操作的方式,而是先讓我們描述一個交互操作圖,然後完全將其運行在Python外部。這與Theano或Torch的做法類似。
因此Python代碼的目的是用來構建這個可以在外部運行的計算圖,以及安排計算圖的哪一部分應該被運行。詳情請查看基本用法中的計算圖表一節。
4. 實現softmax回歸模型
4.1 占位符
我們通過為輸入圖像 x 和目標輸出類別 y_ 創建節點,來開始構建計算圖
我們通過操作符號變量來描述這些可交互的操作單元,可以用下面的方式創建一個:
x = tf.placeholder("float", shape=[None, 784])y_ = tf.placeholder("float", shape=[None, 10])x不是一個特定的值,而是一個占位符placeholder,我們在TensorFlow運行計算時輸入這個值。我們希望能夠輸入任意數量的MNIST圖像,每一張圖展平成784維的向量。我們用2維的浮點數張量來表示這些圖,這個張量的形狀是[None,784 ]。(這裏的None表示此張量的第一個維度可以是任何長度的。)
輸出類別值y_也是一個2維張量,其中每一行為一個10維的one-hot向量,用於代表對應某一MNIST圖片的類別。
雖然placeholder的shape參數是可選的,但有了它,TensorFlow能夠自動捕捉因數據維度不一致導致的錯誤。
4.2 變量
我們的模型也需要權重值和偏置量,當然我們可以把它們當做是另外的輸入(使用占位符),但TensorFlow有一個更好的方法來表示它們:Variable 。 一個Variable代表一個可修改的張量,存在在TensorFlow的用於描述交互性操作的圖中。它們可以用於計算輸入值,也可以在計算中被修改。對於各種機器學習應用,一般都會有模型參數,可以用Variable表示。
W = tf.Variable(tf.zeros([784,10]))b = tf.Variable(tf.zeros([10]))
我們在調用tf.Variable的時候傳入初始值。在這個例子裏,我們把W和b都初始化為零向量。W是一個784x10的矩陣(因為我們有784個特征和10個輸出值)。b是一個10維的向量(因為我們有10個分類)
變量需要通過seesion初始化後,才能在session中使用。這一初始化步驟為,為初始值指定具體值(本例當中是全為零),並將其分配給每個變量,可以一次性為所有變量完成此操作。
sess.run(tf.initialize_all_variables())
5. 類別預測
現在,我們可以實現我們的模型啦。只需要一行代碼!計算每個分類的softmax概率值
y = tf.nn.softmax(tf.matmul(x,W) + b)
tf.matmul(X,W)表示x乘以W,對應之前等式裏面的Wx,這裏x是一個2維張量擁有多個輸入。然後再加上b,把和輸入到tf.nn.softmax函數裏面。
為了訓練我們的模型,我們首先需要定義一個指標來評估這個模型是好的。其實,在機器學習,我們通常定義指標來表示一個模型是壞的,這個指標稱為成本(cost)或損失(loss),然後盡量最小化這個指標。但是,這兩種方式是相同的。
一個非常常見的,非常漂亮的成本函數是“交叉熵”(cross-entropy)。交叉熵產生於信息論裏面的信息壓縮編碼技術,但是它後來演變成為從博弈論到機器學習等其他領域裏的重要技術手段。它的定義如下:
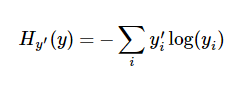
交叉熵是用來衡量我們的預測用於描述真相的低效性。
交叉熵
根據公式計算交叉熵,可以很容易的為訓練過程指定最小化誤差用的損失函數,我們的損失函數是目標類別和預測類別之間的交叉熵
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
首先,用 tf.log 計算 y 的每個元素的對數。接下來,我們把 y_ 的每一個元素和 tf.log(y) 的對應元素相乘。最後,用 tf.reduce_sum 計算張量的所有元素的總和。(註意,這裏的交叉熵不僅僅用來衡量單一的一對預測和真實值,而是所有100幅圖片的交叉熵的總和。對於100個數據點的預測表現比單一數據點的表現能更好地描述我們的模型的性能
6. 訓練模型
現在我們知道我們需要我們的模型做什麽啦,用TensorFlow來訓練它是非常容易的。因為TensorFlow擁有一張描述你各個計算單元的圖,它可以自動地使用反向傳播算法(backpropagation algorithm)來有效地確定你的變量是如何影響你想要最小化的那個成本值的。然後,TensorFlow會用你選擇的優化算法來不斷地修改變量以降低成本。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
在這裏,我們要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的學習速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一個簡單的學習過程,TensorFlow只需將每個變量一點點地往使成本不斷降低的方向移動。當然TensorFlow也提供了其他許多優化算法:只要簡單地調整一行代碼就可以使用其他的算法。
TensorFlow在這裏實際上所做的是,它會在後臺給描述你的計算的那張圖裏面增加一系列新的計算操作單元用於實現反向傳播算法和梯度下降算法。然後,它返回給你的只是一個單一的操作,當運行這個操作時,它用梯度下降算法訓練你的模型,微調你的變量,不斷減少成本。
然後開始訓練模型,這裏我們讓模型循環訓練1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})另一種代碼寫法
for i in range(1000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})該循環的每個步驟中,我們都會隨機抓取訓練數據中的50個批處理數據點,然後我們用這些數據點作為參數替換之前的占位符來運行train_step。
使用一小部分的隨機數據來進行訓練被稱為隨機訓練(stochastic training)- 在這裏更確切的說是隨機梯度下降訓練。在理想情況下,我們希望用我們所有的數據來進行每一步的訓練,因為這能給我們更好的訓練結果,但顯然這需要很大的計算開銷。所以,每一次訓練我們可以使用不同的數據子集,這樣做既可以減少計算開銷,又可以最大化地學習到數據集的總體特性。
7. 評估我們的模型
首先讓我們找出那些預測正確的標簽。tf.argmax 是一個非常有用的函數,它能給出某個tensor對象在某一維上的其數據最大值所在的索引值。由於標簽向量是由0,1組成,因此最大值1所在的索引位置就是類別標簽,比如tf.argmax(y,1)各個預測數字中概率最大的那一個,而 tf.argmax(y_,1) 代表正確的標簽,我們可以用 tf.equal 來檢測我們的預測是否真實標簽匹配(索引位置一樣表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
這行代碼會給我們一組布爾值。為了確定正確預測項的比例,我們可以把布爾值轉換成浮點數,然後取平均值。例如,[True, False, True, True] 會變成 [1,0,1,1] ,取平均值後得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最後,我們計算所學習到的模型在測試數據集上面的正確率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})#輸出結果0.90928. 代碼
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)print(mnist.train.images.shape, mnist.train.labels.shape)print(mnist.test.images.shape, mnist.test.labels.shape)print(mnist.validation.images.shape, mnist.validation.labels.shape)import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
tf.global_variables_initializer().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels}))juedaiyuer MNIST機器學習