
DNN個性化推薦模型
阿新 • • 發佈:2017-05-17
max 點擊 工具 行為 個人 evel end title 職業
0 推薦技術
1)協同過濾:
(1)基於user的協同過濾:根據歷史日誌中用戶年齡,性別,行為,偏好等特征計算user之間的相似度,根據相似user對item的評分推薦item。缺點:新用戶冷啟動問題和數據稀疏不能找到置信的相似用戶進行推薦。
(2)基於item的協同過濾:根據item維度的特征計算item之間的相似度,推薦user偏好item相似的item。
(3)基於社交網絡:根據user社交網絡親密關系,推薦親密的user偏好的item。
(4)基於模型:LR模型,user和item等維度特征輸入給模型訓練,label是show:clk,根據預估的pctr進行推薦。DNN模型:見下面。
2)基於內容的過濾:抽取item的有意義描述特征,推薦user偏好item相似度高的item,個人覺得像基於item的過濾。 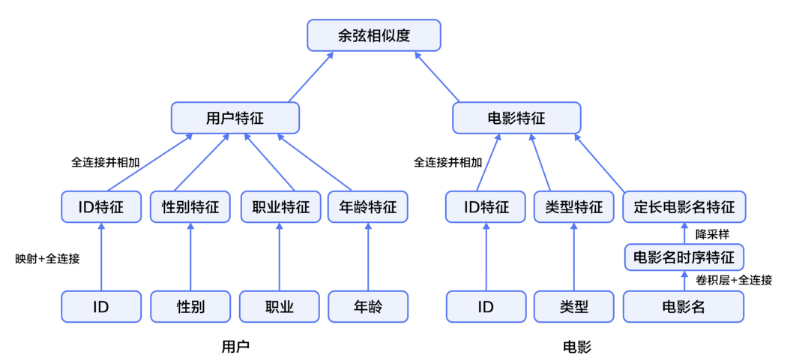 (1) user維度的網絡結構,分別將四個特征embedding,並輸入全連接層;再將四個全連接輸入到全連接層,並定義激活函數為tanh(代碼為paddle開源工具)。
(1) user維度的網絡結構,分別將四個特征embedding,並輸入全連接層;再將四個全連接輸入到全連接層,並定義激活函數為tanh(代碼為paddle開源工具)。

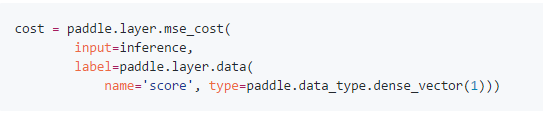
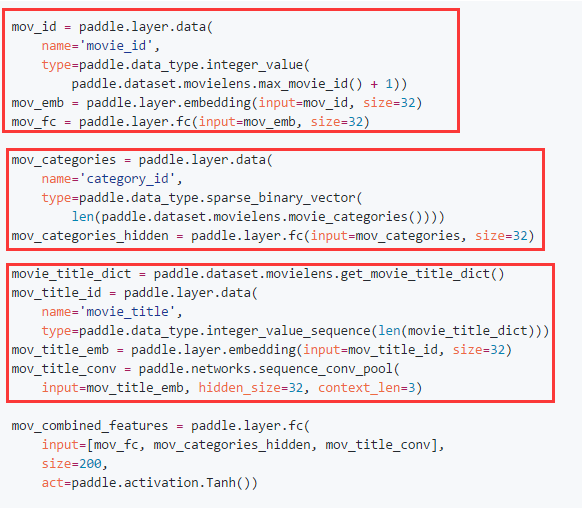 (3)最頂層將user和item連接,cosin距離代表了user和item的相似度,並且損失函數為mse。
(3)最頂層將user和item連接,cosin距離代表了user和item的相似度,並且損失函數為mse。

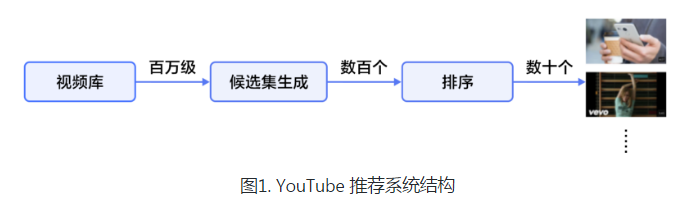 2)百萬級到百級的觸發過濾,模型采用MLP,訓練時softmax做多分類,預測時計算與所有視頻的相似度,取top K個視頻。我認為label可以是show:clk,類似於LR進行模型推薦。
2)百萬級到百級的觸發過濾,模型采用MLP,訓練時softmax做多分類,預測時計算與所有視頻的相似度,取top K個視頻。我認為label可以是show:clk,類似於LR進行模型推薦。
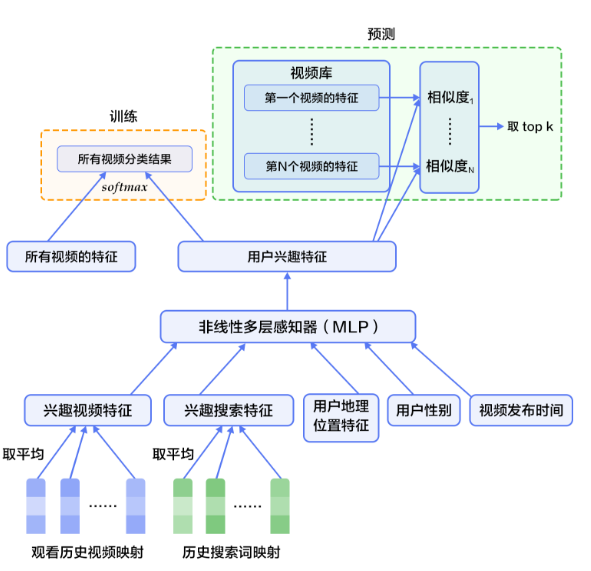
(1) user維度的網絡結構,分別將四個特征embedding,並輸入全連接層;再將四個全連接輸入到全連接層,並定義激活函數為tanh(代碼為paddle開源工具)。

(2)item維度網絡結構,同user維度一樣,分別將三個特征embedding後輸入全連接層,再相加輸入全連接層(註意title用了cnn)。
(3)最頂層將user和item連接,cosin距離代表了user和item的相似度,並且損失函數為mse。
2)百萬級到百級的觸發過濾,模型采用MLP,訓練時softmax做多分類,預測時計算與所有視頻的相似度,取top K個視頻。我認為label可以是show:clk,類似於LR進行模型推薦。
DNN個性化推薦模型