
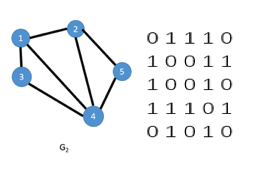
圖的鄰接矩陣存儲
鄰接表的構造與鄰接矩陣完全不同,同學們應該發現了,鄰接表的的結構更像是由幾個鏈表構成的。
在構造鄰接表時,我們的確會借助鏈表的結構。對圖中每個頂點的信息,我們都會分別使用一個鏈表來進行存儲。
因此,我們需要初始化一個有 n 個元素的鏈表數組,n 為圖中頂點數量。
我們要在鄰接表中存儲的圖的信息,實際上就是頂點之間存在的有向邊。
當從頂點 a 到頂點 b 存在一條有向邊時,我們只需要在頭結點為 a 的鏈表後插入一個結點 b。
值得註意的是,當一條邊是從頂點 b 到頂點 a 時,我們同樣需要在以 b 為頭結點的鏈表後插入一個結點 a。
同樣在輸出鄰接表的時候,我們也只需要把每個鏈表依次遍歷輸出就好了。
示例代碼如下(C++ 版):
const int MAX_N = 100;
vector<int> adj[MAX_N];
void insert(int u, int v) {
adj[u].push_back(v);
}
// 輸出從 u 連出的所有邊,頂點從 0 開始編號
for (int i = 0; i < adj[u].size(); ++i) {
cout << "(" << u << ", " << adj[u][i] << ")" << endl;
}
除了通過vectorArrayList)實現以外,還可以直接用數組模擬鏈表來實現鄰接表結構(常數相比使用vector來說更小,運行效率更高):
今天終於知道圖的鄰接表怎麽用數組實現了。之前都是直接vector。
const int MAX_N = 100;
const int MAX_M = 10000;
struct edge {
int v, next;
} e[MAX_M];
//存儲邊的索引
int p[MAX_N], eid;
void init() {
memset(p, -1, sizeof(p));
eid = 0;
}
void insert(int u, int
// 節點u的上一條邊的索引
e[eid].next = p[u];
p[u] = eid++;
}
?
// 輸出從 u 連出的所有邊,頂點從 0 開始編號
for (int i = p[u]; i != -1; i = e[i].next) {
cout << "(" << u << ", " << e[i].v << ")" << endl;
}
我們可以看到,鄰接矩陣存儲結構最大的優點就是簡單直觀,易於理解和實現。
其適用範圍廣泛,有向圖、無向圖、混合圖、帶權圖等都可以直接用鄰接矩陣表示。
另外,對於很多操作,比如獲取頂點度數,判斷某兩點之間是否有連邊等,都可以在常數時間內完成。
然而,它的缺點也是顯而易見的:從以上的例子我們可以看出,對於一個有 n 個頂點的圖,鄰接矩陣總是需要 O(n?*n) 的存儲空間。
當邊數很少的時候,就會造成空間的浪費。
因此,具體使用哪一種存儲方式,要根據圖的特點來決定:如果是稀疏圖(點多邊少),我們一般用鄰接表來存儲,這樣可以節省空間;
如果是稠密圖(點少邊多),當需要頻繁判斷圖中的兩點之間是否存在邊時往往用鄰接矩陣來存儲,其他時候用鄰接表或鄰接矩陣皆可。
圖的鄰接矩陣存儲