
圖像檢索——VLAD
今天主要回顧一下關於圖像檢索中VLAD(Vector of Aggragate Locally Descriptor)算法,免得時間一長都忘記了。關於源碼有時間就整理整理。
一、簡介
雖然現在深度學習已經基本統一了圖像識別與分類這個江湖,但是我覺得在某些小型數據庫上或者小型的算法上常規的如BoW,FV,VLAD,T-Embedding等還是有一定用處的,如果專門做圖像檢索的不知道這些常規算法也免得有點貽笑大方了。
如上所說的這些算法都大同小異,一般都是基於局部特征(如SIFT,SURF)等進行特征編碼獲得一個關於圖像的feature,最後計算feature之間的距離,即使是CNN也是這個過程。下面主要就是介紹一下關於VLAD算法,它主要是得優點就是相比FV計算量較小,相比BoW碼書規模很小,並且檢索精度較高。
二、VLAD算法
- 第一步自然是提取局部特征,有了OpenCV這一步就僅僅是函數調用的問題了:
SurfFeatureDetector detector; SurfDescriptorExtractor extractor; detector.detect( image_0, keypoints ); extractor.compute( image_0, keypoints, descriptors );
如果對特征有什麽要求也可以根據OpenCV的源碼或者網上的源碼進行修改,最終的結果就是提取到了一幅圖像的局部特征(還有關於局部特征參數的控制);
- 第二步本應是量化的過程,但是在量化之前需要事先訓練一本碼書,而碼書同BoW一樣是用K-means算法訓練得到的,同樣OpenCV裏面也集成了這個算法,所以這個過程也再簡單不過了:
kmeans(descriptors, numClusters, labels, TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 10, 0.01 ), 3, KMEANS_PP_CENTERS, centers);需要做的就是定義一些參數,如果自己寫的話就不清楚了。另外碼書的大小從64-256甚至更大不等,理論上碼書越大檢索精度越高。
- 第三步就是量化每一幅圖像的特征了,其實如果數據庫較小,可以直接使用全部圖像的特征作訓練,然後Kmeans函數中的labels中存儲的就是量化的結果:即每一個特征距離那一個聚類中心最近。但是通常訓練和量化是分開的,在VLAD算法中使用的是KDTree算法,KDTree算法是一種快速檢索算法,OpenCV裏同樣集成了KDTree算法:
const int k=1, Emax=INT_MAX;
KDTree T(centers,false); T.findNearest(descriptors_row, k, Emax, idx_t, noArray(), noArray());通過KDTree下的findNearest函數找到與之最近的聚類中心,需要註意的是輸入的STL的vector類型,返回的是centers的索引值;
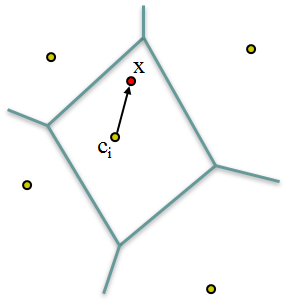
- 量化結束之後就是計算特征和中心的殘差,並對每一幅圖像落在同一個聚類中心上的殘差進行累加求和,並進行歸一化處理,最後每一個聚類中心上都會得到一個殘差的累加和,進行歸一化時需要註意正負號的問題(針對不同的特征)。假設有k個聚類中心,則每一個聚類中心上都有一個128維(SIFT)殘差累加和向量;
- 把這k個殘差累加和串聯起來,獲得一個超長向量,向量的長度為k*d(d=128),然後對這個超長矢量做一個power normolization處理可以稍微提升檢索精度,然後對這個超長矢量再做一次歸一化,現在這個超長矢量就可以保存起來了。
- 假設對N幅圖像都進行了上面的編碼處理之後就會得到N個超長矢量,為了加快距離計算的速度通常需要進行PCA降維處理,關於PCA降維的理論同KDTree一樣都很成熟,OpenCV也有集成,沒有時間自己寫就可以調用了:
PCA pca( vlad, noArray(), CV_PCA_DATA_AS_ROW, 256 );
pca.project(vlad,vlad_tt);輸入訓練矩陣,定義按照行或列進行降維,和降維之後的維度,經過訓練之後就可以進行投影處理了,也可以直接調用特征向量進行矩陣乘法運算。這裏有一點就是PCA的過程是比較費時的,進行查詢的時候由於同樣需要進行降維處理,所以可以直接保存投影矩陣(特征值矩陣),也可以把特征向量、特征值、均值都保存下來然後恢復出訓練的pca,然後進行pca.project進行投影處理;
- 如果不考慮速度或者數據庫規模不是很大時,就可以直接使用降維後的圖像表達矢量進行距離計算了,常用的距離就是歐式距離和余弦距離,這裏使用余弦距離速度更快。當然進行距離計算的基礎就是已經設計好了訓練過程和查詢過程。
三、總結
可以看到,整個VLAD算法結合OpenCV實現起來還是非常簡單的,並且小型數據庫上的檢索效果還可以,但是當數據庫規模很大時只使用這一種檢索算法檢索效果會出現不可避免的下降。另外在作者的原文中,針對百萬甚至千萬級的數據庫時單單使用PCA降維加速距離的計算仍然是不夠的,所以還會使用稱之為積量化或乘積量化(Product Quantization)的檢索算法進行加速,這個也是一個很有意思的算法,以後有機會再介紹它。
圖像檢索——VLAD