
SIFT+BOW 實現圖像檢索
原文地址:https://blog.csdn.net/silence2015/article/details/77374910
本文概述
圖像檢索是圖像研究領域中一個重要的話題,廣泛應用於醫學,電子商務,搜索,皮革等。本文主要是探討學習基於局部特征和詞袋模型的圖像檢索設計。
圖像檢索概述
圖像檢索按照描述圖像不同方式可以分為兩類,一類是基於文本的圖像檢索(Text Based Image Retrieval),另一類是基於內容的圖像檢索(Content Based Image Retrieval)
基於文本的圖像檢索
基於文本的圖像檢索主要是利用文本標註的方式為圖像添加關鍵詞,比如圖像的物體,場景等。在檢索圖像時候直接根據所要搜索的關鍵詞就可以檢索到想要的圖像。這種方式實現起來簡單,但是非常耗費人工(需要人為給每一張圖像標註),對於大型數據庫檢索不太現實。此外,人工標註存在人為認知誤差,對相同圖像,人理解不一樣,也到導致標註不一致,這使得基於文本的圖像檢索逐漸失去光彩。
基於內容圖像檢索
基於內容的圖像檢索技術是基於圖像自身的內容特征來檢索圖像,這免去人為標註圖像的過程。基於內容的圖像檢索技術是采用某種算法來提取圖像中的特征,並將特征存儲起來,組成圖像特征數據庫。當需要檢索圖像時,采用相同的特征提取技術提取出待檢索圖像的特征,並根據某種相似性準則計算得到特征數據庫中圖像與待檢索圖像的相關度,最後通過由大到小排序,得到與待檢索圖像最相關的圖像,實現圖像檢索。這種方式使得檢索過程自動化,圖像檢索的結果優劣取決於圖像特征提取的好壞,在面對海量數據檢索環境中,我們還需要考慮到圖像比對(圖像相似性考量)的過程,采用高效的算法快速找到相似圖像也至關重要。
圖像檢索主要流程
1、設計預處理流程,對圖像數據進行預處理(增強,旋轉,濾波,切分等)
2、設計特征提取模塊,對圖像數據進行高效穩定可重復的特征提取(比如SIFT,SURF,CNN等)
3、對圖像數據庫建立圖像特征數據庫
4、抽取檢索圖像特征,構建特征向量
5、設計檢索模塊,包含相似性度量準則,排序,搜索
6、返回相似性較高的結果
圖像檢索所面臨的挑戰
- 圖像光照變化
- 尺度變化
- 視角變化
- 遮擋
- 背景混亂
- 仿射變換
本文實現流程
圖像數據集的讀取
自己從網上下了十來張圖片,有幾個美女,有幾條狗,有幾只貓,還有一本自己拍的書(三個角度拍的)
SIFT提取圖像局部特征
SIFT算法是提取特征的一個重要算法,該算法對圖像的扭曲,光照變化,視角變化,尺度旋轉都具有不變性。SIFT算法提取的圖像特征點數不是固定值,維度是統一的128維。SIFT算法我之前也總結過(SIFT算法學習總結)。
KMeans聚類獲得視覺單詞,構建視覺單詞詞典
現在得到的是所有圖像的128維特征,每個圖像的特征點數目還不一定相同(大多有差異)。現在要做的是構建一個描述圖像的特征向量,也就是將每一張圖像的特征點轉換為特征向量。這兒用到了詞袋模型,詞袋模型源自文本處理,在這兒用在圖像上,本質上是一樣的。詞袋的本質就是用一個袋子將所有維度的特征裝起來,在這兒,詞袋模型的維度需要我們手動指定,這個維度也就確定了視覺單詞的聚類中心數。
這兒可以這麽理解
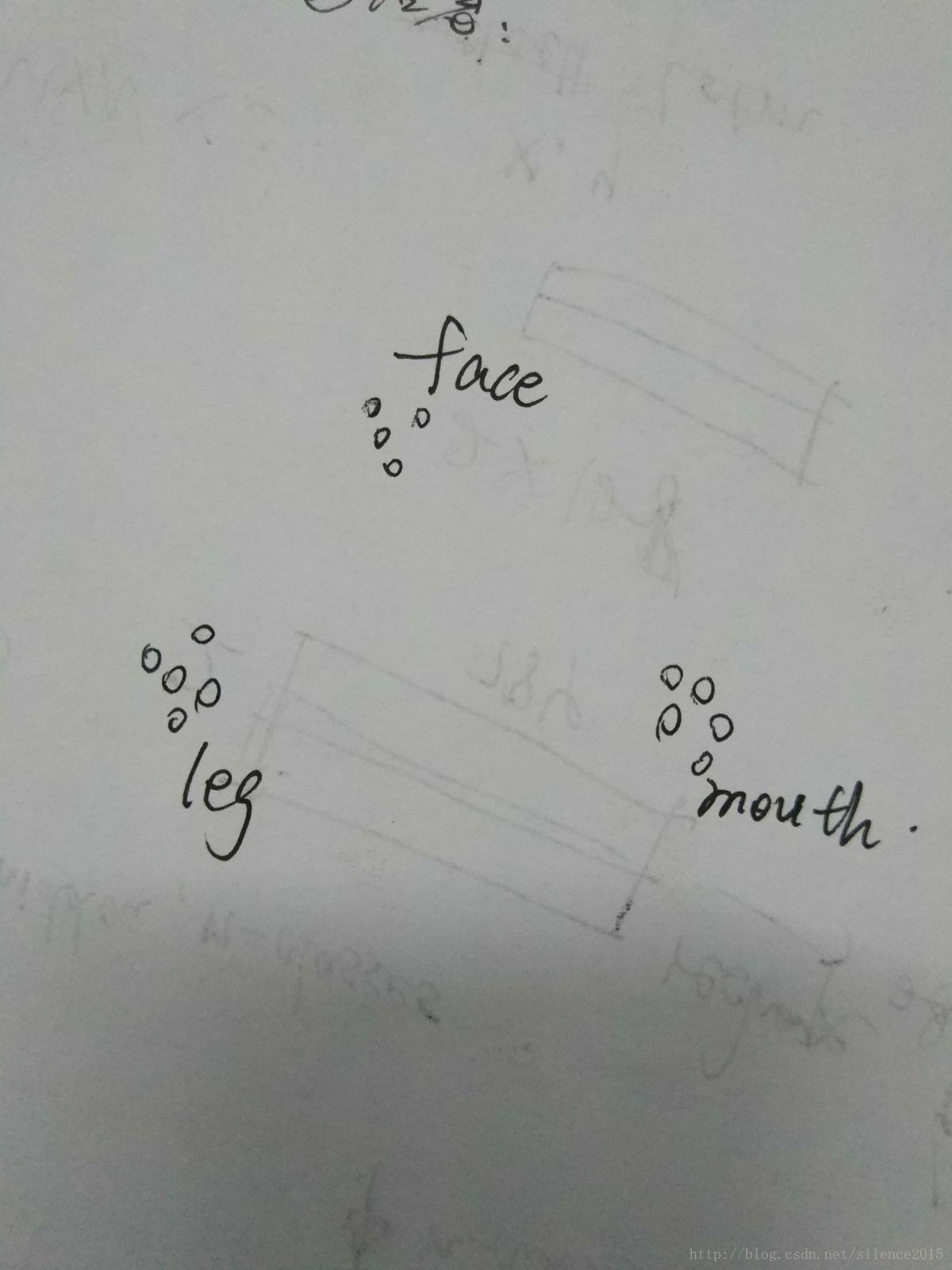
SIFT提取的特征點代表圖中的一個小圓圈,很多圖像中提取出的特征點代表的屬性是類似的,比如某些特征表征臉(這麽說很不嚴謹,但是可以粗淺的這麽理解),那麽那些表征臉的特征點就會聚集在一起,形成一個簇。那麽詞袋就是將face,leg,mouth那些特征簇框起來的袋子,一個簇其實也就代表了一個維度的特征,那麽怎麽讓計算機自動形成簇呢?繼續往下看。
構造圖像特征
熟悉聚類算法的同學已經明白了,上面講的簇就是通過聚類算法得到的,聚類算法將類別相近,屬性相似的樣本框起來,是一種無監督學習算法。在本文中,我使用了Kmeans算法來聚類得到視覺單詞(也就是face,leg等),通過聚類得到了聚類中心,通過聚類得到了表征詞袋的特征點。
ok,到現在,我們得到k個聚類中心(一個聚類中心表征了一個維度特征,k由自己手動設置)和先前SIFT得到的所有圖片的特征點,現在就是要通過這兩項來構造每一張圖像的特征向量。
在本文中,構造的思路跟簡單,就是比對特征點與所有聚類中心的距離,將特征點分配到距離最近的特征項,比如經計算某特征點距離leg這個聚類中心最近,那麽這個圖像中leg這個特征項+1。以此類推,每一張圖像特征向量也就構造完畢。
搜索目標圖像相似圖像
搜索相似圖片其實就是在高維特征空間中,尋找靠近的小夥伴的過程。這兒我使用的暴力法,也就是一個個比對檢索圖片與數據庫中所有圖片的距離(距離就用的歐式距離計算的),然後排序,得到最接近的圖片。在大型數據庫中肯定不能這麽做,簡單的優化思路是可以先將要搜尋的數據集做劃分,這兒劃分可以理解為特征空間的劃分。比如可以用哈希編碼來,也可以用神經網絡(挺fashion!)。這樣在子空間裏尋找相似圖像就快得多。還有思路就是對數據庫做索引,空間換時間。
最後得到的結果



總結
由上面檢索不同圖片的結果,可以發現,對於簡單的物體(在我如數據集中貓,狗,書)檢索的結果差強人意,對於大美女的檢索結果簡直不能看(可能背景比較復雜,還有美女姿勢啊,身材啊。。。產生了比較大的影響),最後發現對於書的檢索結果是最棒的。
不足之處
- Kmeans聚類時間長
- 詞袋表征特征的過程其實牽涉到量化的過程,這其實損失了特征的精度。
- 檢索模塊設計的太粗糙,速度太慢
- 沒有設計反饋系統,系統無法自動升級
- 主要還是慢和精度不高(這麽點圖片,聚類就花了很久)
github地址
https://github.com/zhaoxin111/imageRetrieval
參考文獻
http://yongyuan.name/blog/cbir-technique-summary.html
http://yongyuan.name/blog/CBIR-BoW-for-image-retrieval-and-practice.html
Csurka G, Dance C, Fan L, et al. Visual categorization with bags of keypoints[C]//Workshop on statistical learning in computer vision, ECCV. 2004, 1(1-22): 1-2.
SIFT+BOW 實現圖像檢索