
R語言hist繪圖函數
hist 用於繪制直方圖,下面介紹每個參數的作用;
1)x: 用於繪制直方圖的數據,該參數的值為一個向量
代碼示例:
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data)
效果圖如下:

從圖中可以看出,橫坐標為不同的區間,縱坐標為落入該區間內的頻數;
2) break : 該參數的指定格式有很多種
第一種: 指定一個向量,給出不同的斷點
代碼示例:
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5))
效果圖如下:

第二種:指定分隔好的區間的個數,會根據區間個數自動去計算區間的大小
代碼示例:
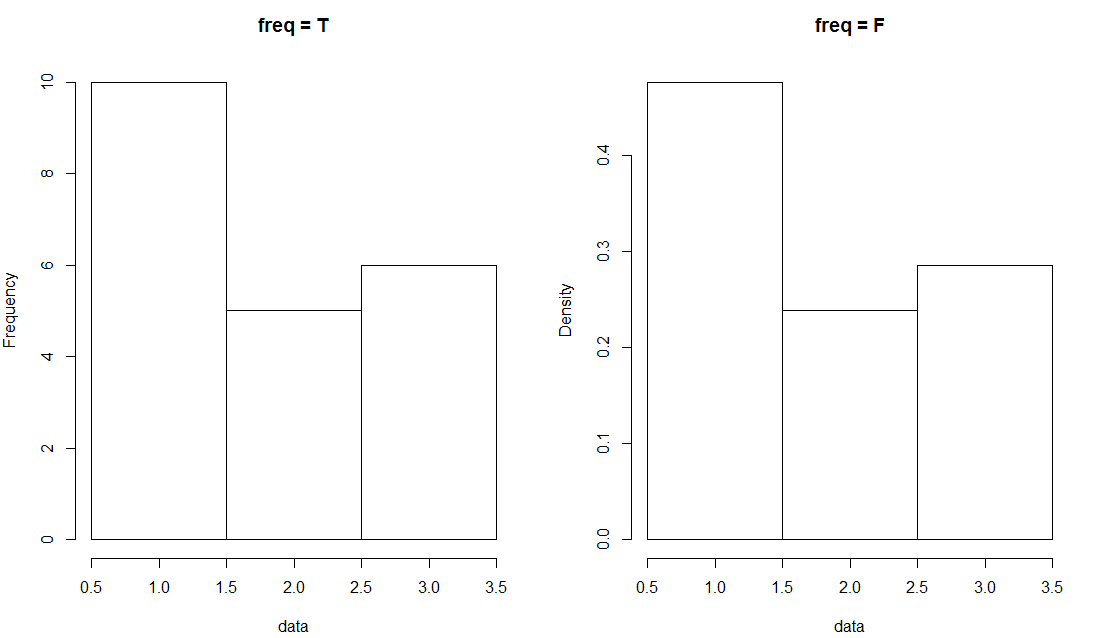
3)freq: 邏輯值,默認值為TRUE , y軸顯示的是每個區間內的頻數,FALSE, 代表顯示的是頻率(= 頻數/ 總數)
代碼示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), freq = T, main = "freq = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), freq = F, main = "freq = F")
效果圖如下:
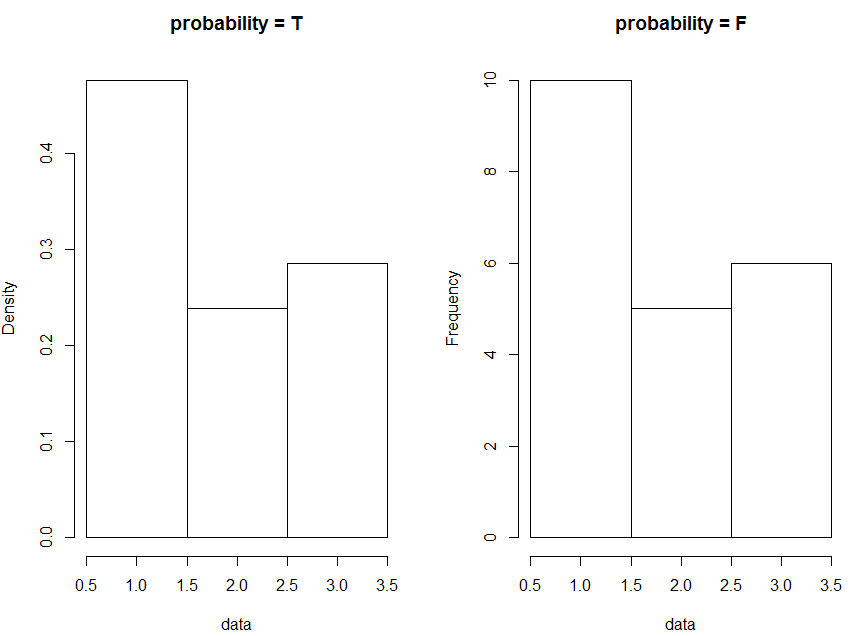
4)probability : 邏輯值,和 freq 參數的作用正好相反,TRUE 代表頻率, FALSE 代表頻數
代碼示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), probability = T, main = "probability = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), probability = F, main = "probability = F")
效果圖如下:
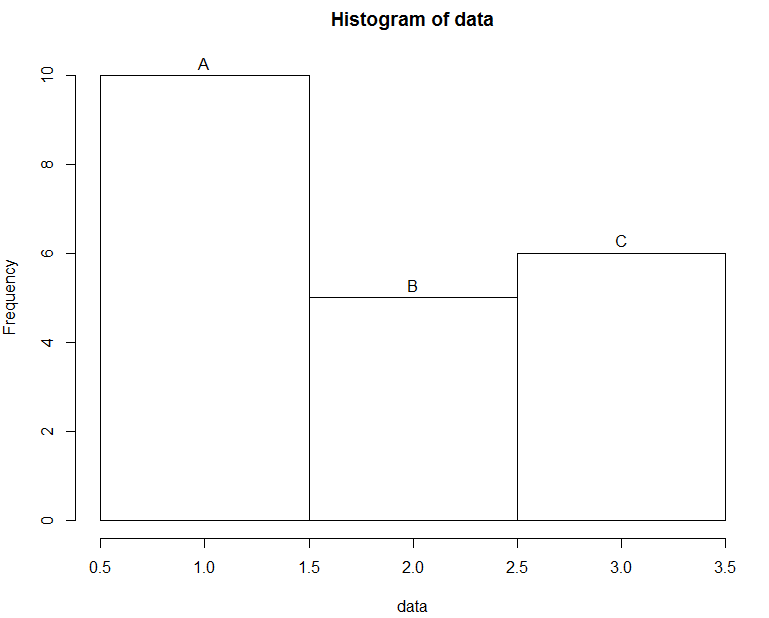
5) labels: 顯示在每個柱子上方的標簽,
代碼示例:
hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), labels = c("A", "B", "C"))
效果圖如下:
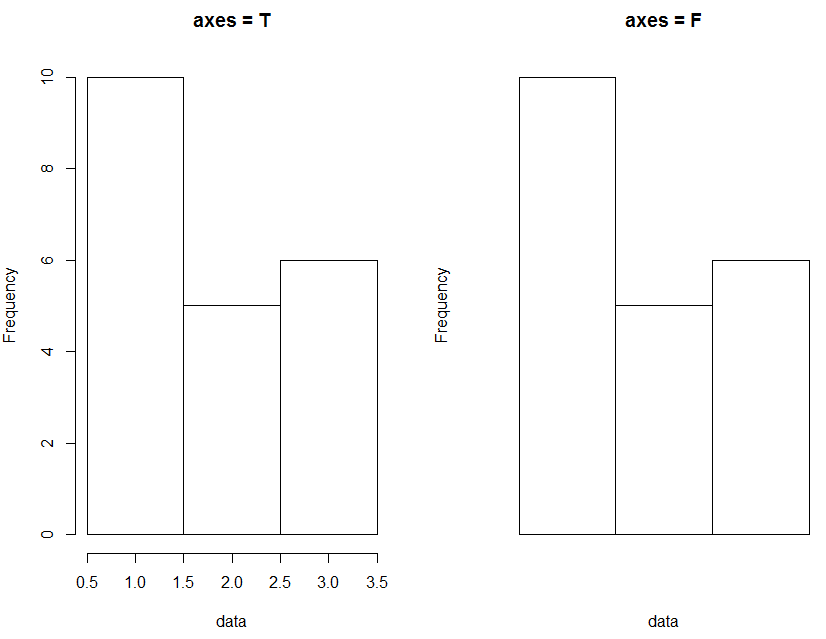
6) axes : 邏輯值,是否顯示軸線
代碼示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), axes = T, main = "axes = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), axes = F, main = "axes = F")
效果圖如下:
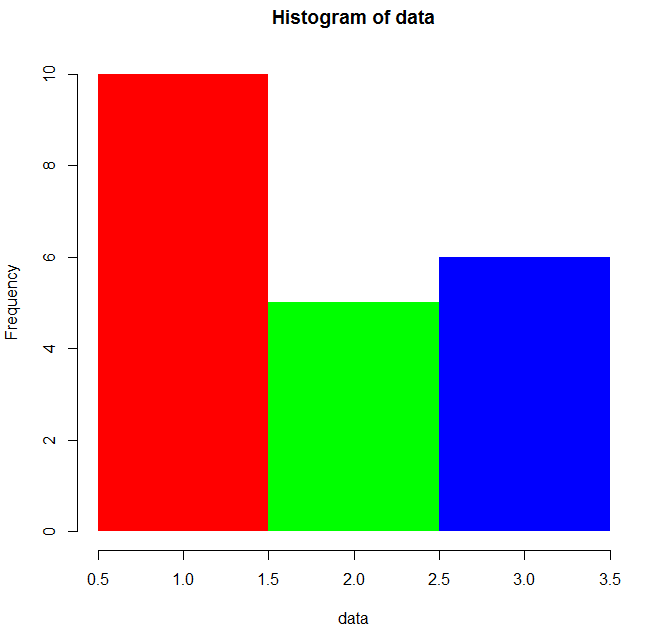
7) col : 柱子的填充色
代碼示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = "pink") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = rainbow(3))
效果圖如下:

8) border : 柱子的邊框的顏色,默認為black, 當border = NA 時, 代表沒有邊框
代碼示例:
hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = rainbow(3), border = NA)
效果圖如下:
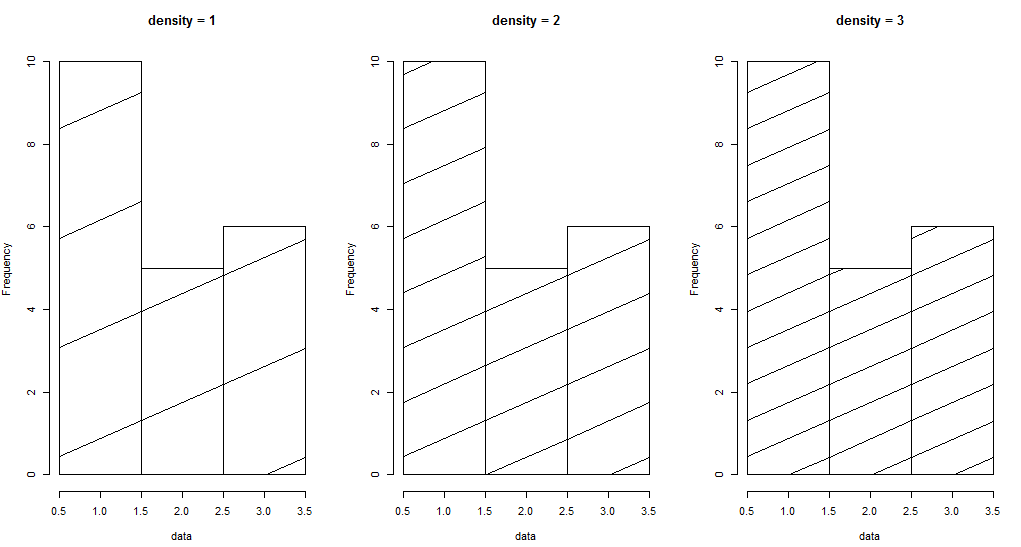
9) densitty 和 angle , 用線條填充柱子
代碼示例: density 控制填充的線條的密度
par(mfrow = c(1, 3)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 1, main = "density = 1") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, main = "density = 2") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 3, main = "density = 3")
效果圖如下:
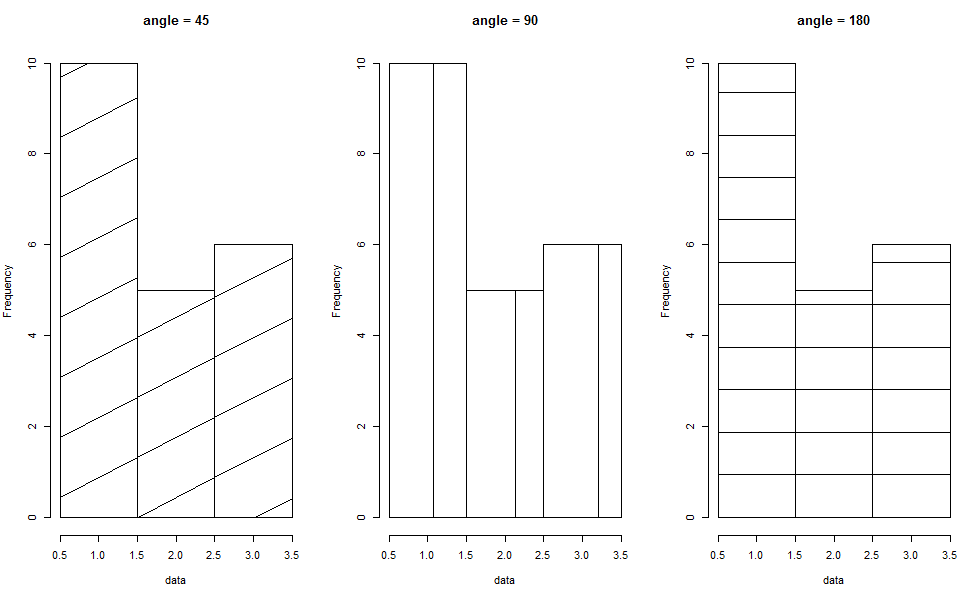
代碼示例: angle 控制線條的角度,必須和density 參數配合使用,才能發揮作用
par(mfrow = c(1, 3)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 45, main = "angle = 45") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 90, main = "angle = 90") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 180, main = "angle = 180")
效果圖如下:
最後介紹一下hist函數的返回值
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) a <- hist(data, breaks = c(0.5, 1.5, 2.5, 3.5)) a $breaks [1] 0.5 1.5 2.5 3.5 $counts [1] 10 5 6 $density [1] 0.4761905 0.2380952 0.2857143 $mids [1] 1 2 3 $xname [1] "data" $equidist [1] TRUE attr(,"class") [1] "histogram"
從代碼中的結果可以看到,返回值是一個 histogram 類型的對象, 其中breaks 是分隔的區間,counts 是每個區間的頻數,density是每個區間的頻率,mids 是每個柱子的中心點;
利用返回值,我們可以用hist函數統計一串數據在不同區間的頻數分布
R語言hist繪圖函數