
zookeeper與kafka安裝部署及java環境搭建
1. ZooKeeper安裝部署
本文在一臺機器上模擬3個zk server的集群安裝。
1.1. 創建目錄、解壓
|
cd /usr/ #創建項目目錄 mkdir zookeeper
cd zookeeper mkdir tmp mkdir zookeeper-1 mkdir zookeeper-2 mkdir zookeeper-3
cd tmp mkdir zk1 mkdir zk2 mkdir zk3
cd zk1 mkdir data mkdir log
cd zk2 mkdir data mkdir log
cd zk3 mkdir data mkdir log
#將壓縮包分別解壓一份到 zookeeper-1, zookeeper-2, zookeeper-3目錄下 tar -zxvf zookeeper-3.4.10.tgz |
1.2. 創建每個目錄下conf/zoo.cfg配置文件
/home/hadoop/zookeeper-1/conf/zoo.cfg 內容如下:
|
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk1/data dataLogDir=/home/hadoop/tmp/zk1/log clientPort=2181 server.1=192.168.68.128:2287:3387 server.2=192.168.68.128:2288:3388 server.3=192.168.68.128:2289:3389 |
/home/hadoop/zookeeper-2/conf/zoo.cfg 內容如下:
|
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk2/data dataLogDir=/home/hadoop/tmp/zk2/log clientPort=2182 server.1=192.168.68.128:2287:3387 server.2=192.168.68.128:2288:3388 server.3=192.168.68.128:2289:3389 |
/home/hadoop/zookeeper-3/conf/zoo.cfg 內容如下:
|
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/tmp/zk3/data dataLogDir=/home/hadoop/tmp/zk3/log clientPort=2183 server.1=192.168.68.128:2287:3387 server.2=192.168.68.128:2288:3388 server.3=192.168.68.128:2289:3389 |
註:紅色部分192.168.68.128為服務器的ip。
因為是在一臺機器上模擬集群,所以端口不能重復,這裏用2181~2183,2287~2289,以及3387~3389相互錯開。
另外每個zk的instance,都需要設置獨立的數據存儲目錄、日誌存儲目錄,所以dataDir、dataLogDir這二個節點對應的目錄,需要手動先創建好。即1.1所述的:
/usr/zookeeper/tmp/zk1/data
/usr/zookeeper/tmp/zk1/log
/usr/zookeeper/tmp/zk2/data
/usr/zookeeper/tmp/zk2/log
/usr/zookeeper/tmp/zk3/data
/usr/zookeeper/tmp/zk3/log
1.3. 創建每個目錄下data/myid文件
另外還有一個非常關鍵的設置,在每個zk server配置文件的dataDir所對應的目錄下,必須創建一個名為myid的文件,其中的內容必須與zoo.cfg中server.x中的x相同,即:
/usr/zookeeper/tmp/zk1/data/myid 中的內容為1,對應server.1中的1
/usr/zookeeper/tmp/zk1/data/myid 中的內容為2,對應server.2中的2
/usr/zookeeper/tmp/zk1/data/myid 中的內容為3,對應server.3中的3
生產環境中,分布式集群部署的步驟與上面基本相同,只不過因為各zk server分布在不同的機器,上述配置文件中的localhost換成各服務器的真實Ip即可。分布在不同的機器後,不存在端口沖突問題,可以讓每個服務器的zk均采用相同的端口,這樣管理起來比較方便。
1.4. 啟動驗證
|
/usr/zookeeper/zookeeper-1/bin/zkServer.sh start & |
|
/usr/zookeeper/zookeeper-3/bin/zkServer.sh start & |
|
/usr/zookeeper/zookeeper-3/bin/zkServer.sh start & |
註:&符號表示後臺啟動,啟動後可以退出命令行窗口。
啟用成功後,輸入 jps 看下進程:
20351 ZooKeeperMain
20791 QuorumPeerMain
20822 QuorumPeerMain
20865 QuorumPeerMain
應該至少能看到以上幾個進程。
可以啟動客戶端測試下:
|
bin/zkCli.sh -server 192.168.68.128:2181 |
註:如果是遠程連接,把localhost換成指定的IP即可。
成功後,應該會進到提示符下,類似下面這樣:
[zk: localhost:2181(CONNECTED) 0]
然後,就可以用一些基礎命令,比如 ls ,create ,delete ,get 來測試了(關於這些命令,大家可以查看文檔),特別提一個很有用的命令rmr 用來遞歸刪除某個節點及其所有子節點。
查看zk狀態:
|
bin/zkServer.sh status |
分別查看zk狀態,可以看到:
ZooKeeper JMX enabled by default
Using config: /usr/zookeeper/zookeeper-1/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
或Mode:leader
至此,zookeeper集群已經部署完成了。
2. Kafka安裝部署
2.1. 創建目錄、解壓
|
cd /usr/ #創建項目目錄 mkdir kafka cd kafka mkdir tmp cd tmp #創建kafka消息目錄,主要存放kafka消息 mkdir kafka-logs-1 mkdir kafka-logs-2 mkdir kafka-logs-3 #將壓縮包放到usr/kafka內,解壓 tar -zxvf kafka_2.10-0.10.1.0.tgz |
2.2. 修改配置文件
進入到config目錄
|
cd /usr/kafka/kafka_2.10-0.10.1.0/config |
主要關註:server.properties 這個文件即可。拷貝三份到同級目錄:
config/server-1.properties
config/server-3.properties
config/server-2.properties
以下為默認配置:
|
# distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker. broker.id=0
# Switch to enable topic deletion or not, default value is false #delete.topic.enable=true
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = security_protocol://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 #listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set, # it uses the value for "listeners" if configured. Otherwise, it will use the value # returned from java.net.InetAddress.getCanonicalHostName(). #advertised.listeners=PLAINTEXT://your.host.name:9092
# The number of threads handling network requests num.network.threads=3
# The number of threads doing disk I/O num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk #log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush #log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log.
# The minimum age of a log file to be eligible for deletion log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don‘t drop below log.retention.bytes. #log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000 |
需要修改的只有四處:
broker.id=0
#listeners=PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs
zookeeper.connect=localhost:2181
分別修改三個配置文件,修改上面四處為:
config/server-1.properties
|
broker.id=1 listeners=PLAINTEXT://192.168.68.128:9092 log.dirs=/usr/kafka/tmp/kafka-logs-1 zookeeper.connect=192.168.68.128:2181,192.168.68.128:2182,192.168.68.128:2183 |
config/server-2.properties
|
broker.id=2 listeners=PLAINTEXT://192.168.68.128:9092 log.dirs=/usr/kafka/tmp/kafka-logs-2 zookeeper.connect=192.168.68.128:2181,192.168.68.128:2182,192.168.68.128:2183 |
config/server-3.properties
|
broker.id=3 listeners=PLAINTEXT://192.168.68.128:9092 log.dirs=/usr/kafka/tmp/kafka-logs-3 zookeeper.connect=192.168.68.128:2181,192.168.68.128:2182,192.168.68.128:2183 |
註:紅色部分為服務器的ip。
2.3. 啟動驗證
進入kafka目錄,後臺啟動kafka集群:
|
bin/kafka-server-start.sh ./config/server-1.properties & |
|
bin/kafka-server-start.sh ./config/server-2.properties & |
|
bin/kafka-server-start.sh ./config/server-3.properties & |
執行命令jps驗證是否啟動:
2820 QuorumPeerMain
9366 Kafka
9655 Kafka
9924 Kafka
2877 QuorumPeerMain
2923 QuorumPeerMain
10189 Jps
至此,kafka集群已經部署完成了。
3. Kafka的java開發環境搭建
3.1. 導入jar包
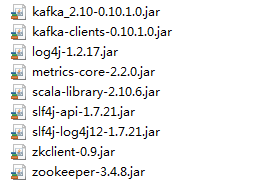
解壓kafka壓縮包,進入kafka_2.10-0.10.1.0\libs,拷貝一下jar包到java工程的lib目錄下:
3.2. Producer
|
package com.pers.producer;
import java.util.Properties; import java.util.concurrent.TimeUnit;
import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; import kafka.serializer.StringEncoder;
/** * @author liangyadong * @date 2017年5月26日 下午3:04:07 * @version 1.0 */ public class KafkaProducer {
private String topic; public KafkaProducer(String topic){ super(); this.topic = topic; }
public void run(){
Producer producer = createProducer();
int i = 0; while(true){ producer.send(new KeyedMessage<Integer, String>(topic, "message:" + i++));
try{ TimeUnit.SECONDS.sleep(1); } catch(InterruptedException e) { e.printStackTrace(); } } }
private Producer createProducer(){
Properties properties = new Properties(); properties.put("zookeeper.connect", "192.168.68.128:2181,192.168.68.128:2182,192.168.68.128:2183");// 聲明zookeeper properties.put("serializer.class", StringEncoder.class.getName()); properties.put("metadata.broker.list", "192.168.68.128:9092,192.168.68.128:9093,192.168.68.128:9094");// 聲明kafka
return new Producer<Integer,String>(new ProducerConfig(properties)); }
public static void main(String[] args) { new KafkaProducer("test111").run();// 創建主題,發送消息 }
} |
3.3. Consumer
|
package com.pers.consumer;
import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties;
import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector;
/** * @author liangyadong * @date 2017年5月26日 下午4:01:37 * @version 1.0 */ public class KafkaConsumer extends Thread{
private String topic;
public KafkaConsumer(String topic){ super(); this.topic = topic; }
public void run() { ConsumerConnector consumer = createConsumer(); Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic, 1); // 一次從主題中獲取一個數據 Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumer.createMessageStreams(topicCountMap); KafkaStream<byte[], byte[]> stream = messageStreams.get(topic).get(0);// 獲取每次接收到的這個數據 ConsumerIterator<byte[], byte[]> iterator = stream.iterator(); while(iterator.hasNext()){ String message = new String(iterator.next().message()); System.out.println("接收到: " + message); } }
private ConsumerConnector createConsumer(){
Properties properties = new Properties(); properties.put("zookeeper.connect", "192.168.68.128:2181,192.168.68.128:2182,192.168.68.128:2183");// 聲明zookeeper properties.put("group.id", "group5");// 必須要使用別的組名稱, 如果生產者和消費者都在同一組,則不能訪問同一組內的topic數據 return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
public static void main(String[] args) { new KafkaConsumer("test111").run();// 使用kafka集群中創建好的主題 test
}
} |
3.4. 啟動驗證
1、啟動生產者
運行KafkaProducer.java中的main方法。
2、啟動消費者
運行KafkaConsumer.java中的main方法。
控制臺輸出內容如下:
|
接收到: message:1 接收到: message:2 接收到: message:3 接收到: message:4 接收到: message:5 接收到: message:6 ... |
至此,搭建完成。
4. 常用命令
4.1. Zookeeper
4.1.1. 啟動服務
|
bin/kafka-server-start.sh ./config/server-1.properties & |
4.1.2. 關閉服務
|
zkServer.sh stop |
4.2. Kafka
4.2.1. 啟動服務(先啟動zookeeper)
|
bin/kafka-server-start.sh ./config/server-1.properties & |
4.2.2. 關閉服務(先關閉zookeeper,再關閉kafka)
|
kafka-server-stop.sh |
4.2.3. 查看當前主題列表
|
./kafka-topics.sh --zookeeper 192.168.68.128:2181 --list |
4.2.4. 創建主題(註意partitions分區數目)
|
kafka-topics.sh --zookeeper 192.168.68.128:2181 --create --topic XXX --partitions 2 --replication-factor 1 |
4.2.5. 刪除主題
|
kafka-topics.sh --zookeeper 192.168.68.128:2181 --delete --topic XXX |
4.2.6. 創建生產者
|
kakfa-console-producer.sh --broker-list 192.168.68.128:9092 --topic XXX |
4.2.7. 創建消費者
|
kafka-console-consumer.sh --zookeeper 192.168.68.128:2181 --topic XXX [--from-beginning 添加改選項則重置offset從頭開始接收,若不配置,從啟動時開始接收] |
zookeeper與kafka安裝部署及java環境搭建