
Spark環境安裝部署及詞頻統計例項
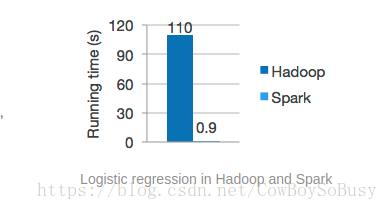
Spark是一個高效能的分散式計算框架,由於是在記憶體中進行操作,效能比MapReduce要高出很多.
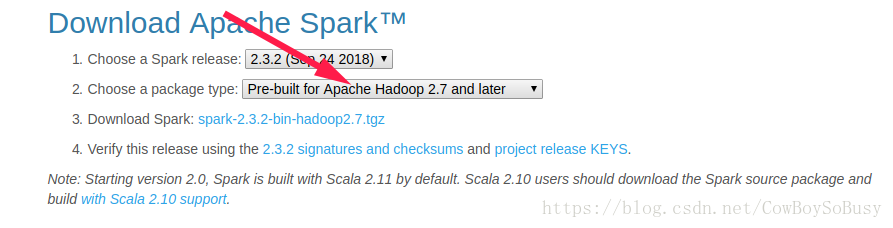

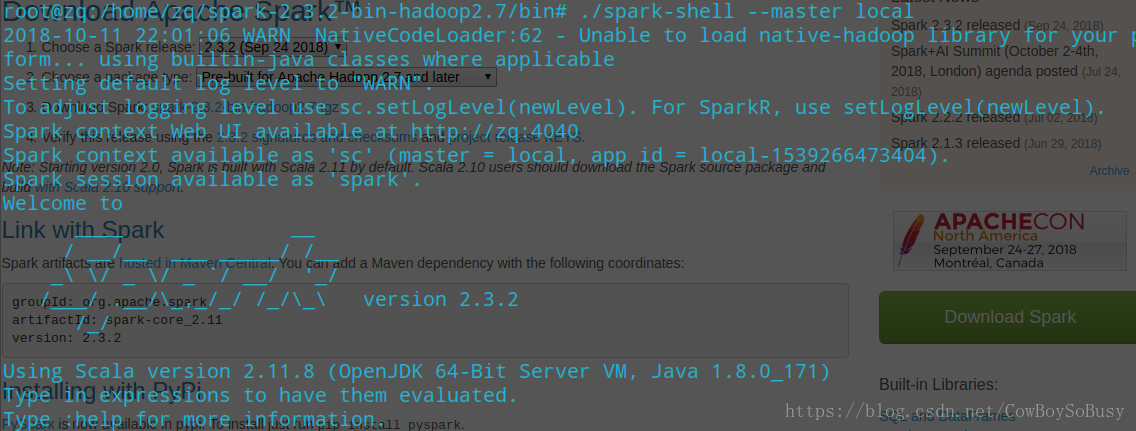
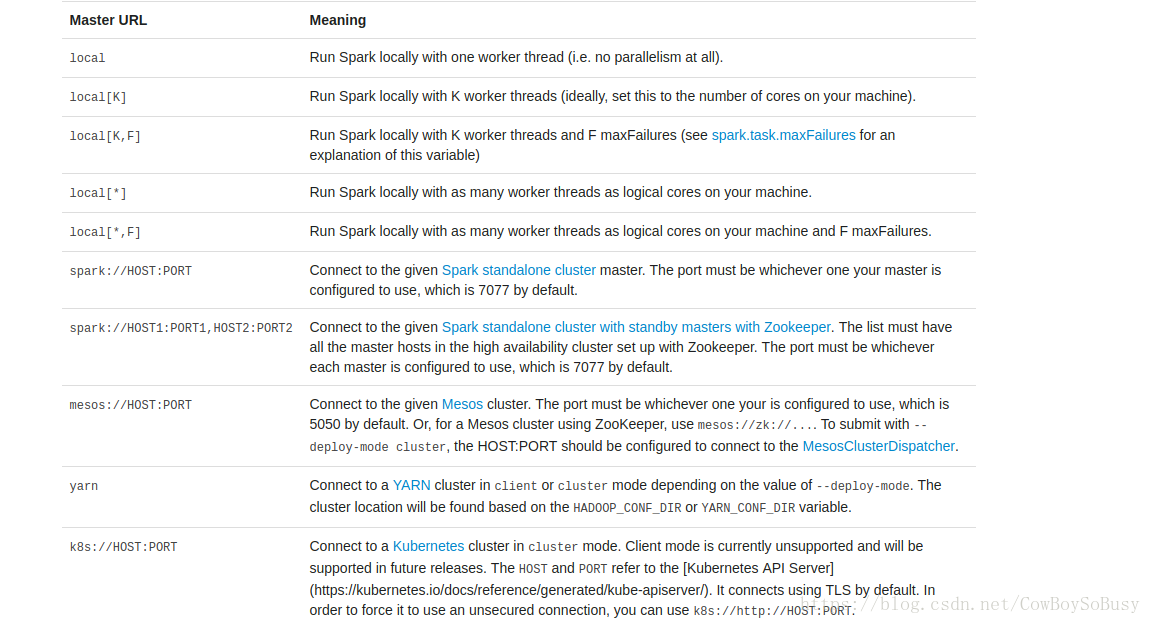
./spark-shell --master local[ 2代表開兩個執行緒,*代表開本地所有執行緒
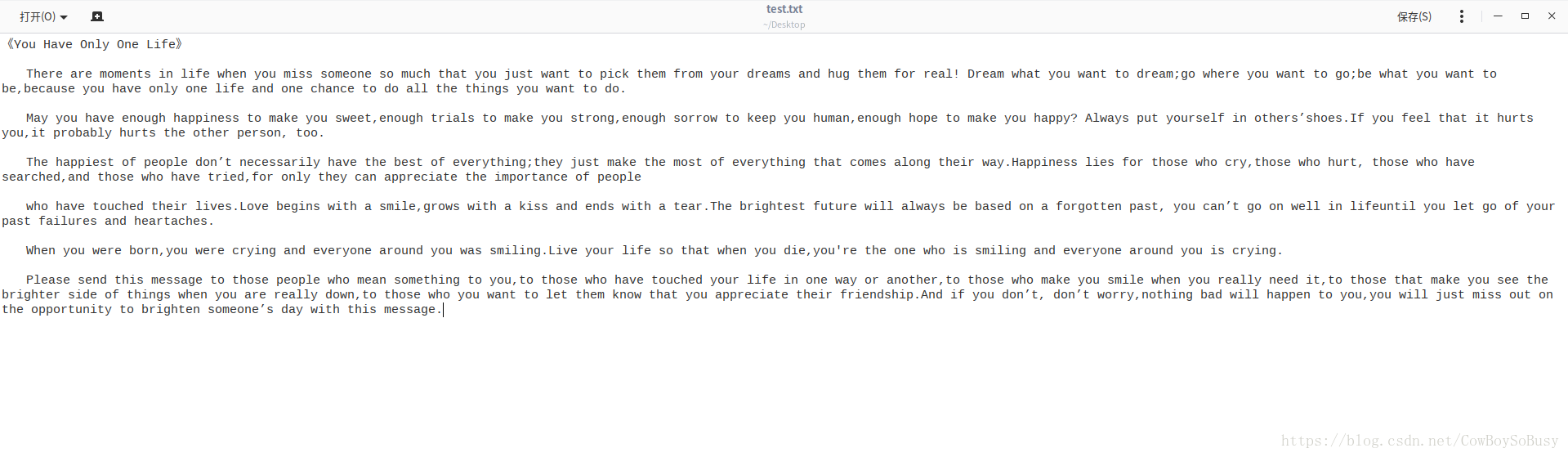
var file = sc.textFile("file:///home/zq/Desktop/test.txt")
file.collect
file.count
file.first()
val a = file.flatMap(line=>line.split(" "))
val b = 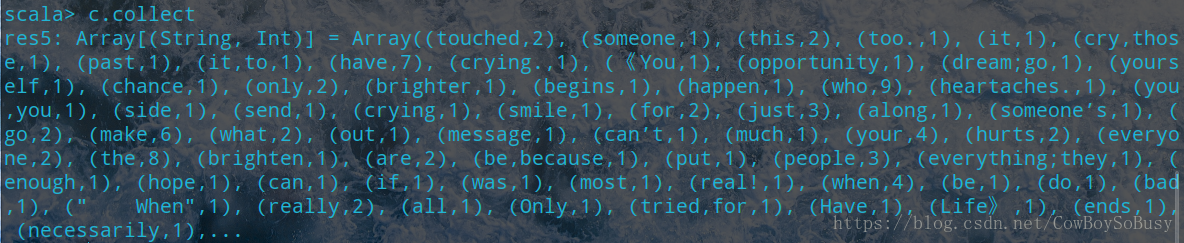
sc.textFile("file:///home/zq/Desktop/test.txt").flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_ + _).collect
在啟動的時候發現一條語句顯示如下
Spark context Web UI available at http://zq:4040
可知本地瀏覽器訪問http://zq:4040,可以看到Web UI介面
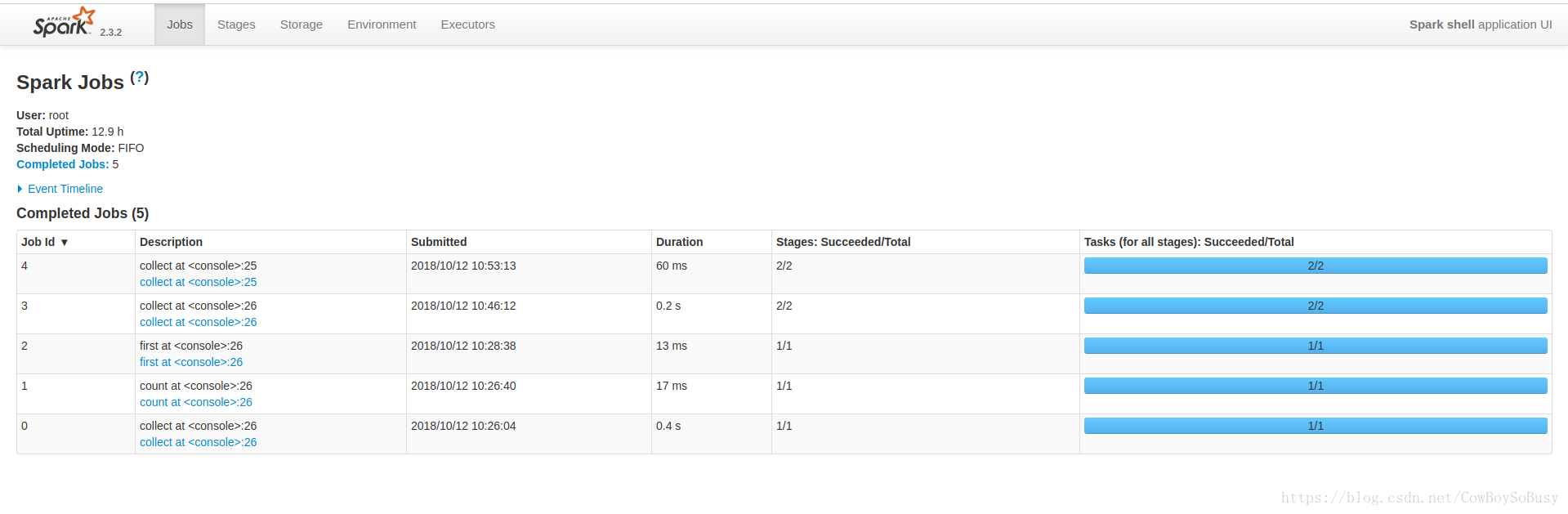
你們可以參考一下我的前面幾篇部落格,是通過Hadoop裡面的MapReduce來做的單詞統計的程式, 和spark的效果一對比,我個人感覺spark更快更方便,效率更高! 有興趣可以閱讀我的這兩篇系列部落格 基於MapReduce的詞頻統計程式WordCountApp(一) 基於MapReduce的詞頻統計程式WordCount2App(二) 再通過這篇spark的操作,你會發現它們之間的差別與各自的優缺點