
python版本與編碼的區別
主要編碼介紹
python解釋器在加載 .py 文件中的代碼時,會對內容進行編碼(默認ascill)
ASCII(American Standard Code for Information Interchange,美國標準信息交換代碼)是基於拉丁字母的一套電腦編碼系統,主要用於顯示現代英語和其他西歐語言,其最多只能用 8 位來表示(一個字節),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號。
顯然ASCII碼無法將世界上的各種文字和符號全部表示,所以,就需要新出一種可以代表所有字符和符號的編碼,即:Unicode
Unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字符編碼。Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一並且唯一的二進制編碼,規定雖有的字符和符號最少由 16 位來表示(2個字節),即:2 **16 = 65536,
註:此處說的的是最少2個字節,可能更多
UTF-8,是對Unicode編碼的壓縮和優化,他不再使用最少使用2個字節,而是將所有的字符和符號進行分類:ascii碼中的內容用1個字節保存、歐洲的字符用2個字節保存,東亞的字符用3個字節保存...
GBK,也是對Unicode編碼的壓縮和優化,全稱為漢字內碼拓展規範,使用了雙字節編碼方案,由中國信息技術標準化委員會制訂。
所以,python2解釋器在加載 .py 文件中的代碼時,會對內容進行編碼(默認ascill),如果是如下代碼的話:
報錯:ascii碼無法表示中文
1 #!/usr/bin/env python 2 3 print "你好,世界"
改正:應該顯示的告訴python解釋器,用什麽編碼來執行源代碼,即:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 print "你好,世界"
而在python3中,改為使用默認ut-8進行編碼,所以在python3中不加# -*- coding: utf-8 -*-也不會出現亂碼。
編碼之間的轉化
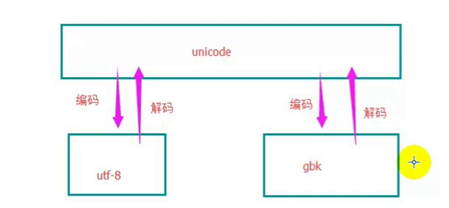
在python2.7中
如果想將UTF-8轉化為GBK編碼,那麽先要解碼成unicode,然後再編碼成GBK編碼,即:
1 temp = "李程"
2 # 解碼 需要指定原來是什麽編碼
3 temp_unicode = temp.decode("utf-8‘)
4 # 編碼 需要指定要編成什麽編碼
5 temp_gbk = temp_unicode.encode("gbk")而在python3中
移除了unicode類型的編碼,系統自動幫你完成內部一系列的轉換,你只需要一步進行編碼即可:
1 temp = "李程"
2 # 自動進行轉化
3 temp_gbk = temp.encode("gbk")
Tips:
window終端默認采用的編碼格式是GBK,所以UTF-8編碼的代碼在終端顯示會亂碼,但是window可以自動將unicode編碼的代碼轉化成自己想要的編碼格式,所以在window上你只需要將其他類型的編碼轉化成unicode即可。
python版本與編碼的區別