
python學習-字元編碼區別
一、字元編碼
ASCII編碼127個字元,佔8bit位,1byte。
GB2312編碼7445個字元,包括6763和漢字和682個其他符號。(1980年)
GB18030編碼27484個字元,同時收錄了藏文、蒙文、維吾爾文等少數民族文字,PC必須支援,嵌入式可以例外。(2000年)
從ASCII、GB2312、GBK到GB18030,這些編碼方法是向下相容的,即相同字元編碼相同,後面標準支援更多的額字元。在這些編碼中,英文和中文可以統一地處理。
區分方法是高位元組的最高位不為0,按照程式設計師的稱呼,BG2312、GBK到GB18030都屬於雙位元組字符集(BDCS)。
為了統一字元編碼,國際標準化組織新出一種可以代表所有字元和符號的編碼:Unicode
Unidode預設每個字元(不管中文,英文都)佔2byte即16bit。
utf-8可變長字元編碼,utf-8中文佔3byte,英文佔1byte。
python 3中預設支援utf-8
python 2中要寫中文要宣告字符集:“# -*- coding:utf-8 -*-”
二、字元編碼轉換關係:
三、使用者互動程式
使用者輸入
1.註釋單行:#
註釋多行: '''開始 '''結束, 或者"""開始 """結束。
shell 指令碼中單引號和雙引號有區別: ‘’不會 轉義 “”會轉義
python中單引號和雙引號作用一樣。
2.格式化輸出
#!/bin/bash/env python
#author liliang
name = input("name:")
age = int(input("age:"))
print(type(age))
#age = (input("age:")))
#print(type(age),type( str(age) ))
job = input("job:")
salary = input("salary:")
info = '''
------------ info of %s ----------------
Name:%s
Age:%d
Job:%s
Salary:%s
''' % (name,name,age,job,salary)
#%s是字元string %d是數字digital %f是浮點小數float
print(info)
#括號中帶“”是變數,不帶“”是數值
第一種方法:
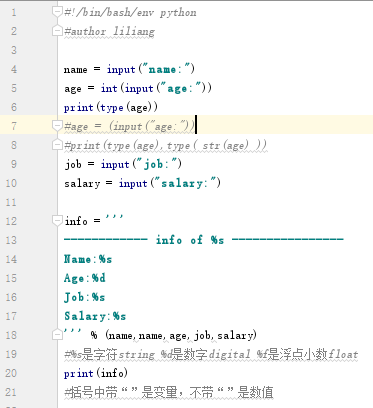
第二種方法:官網建議
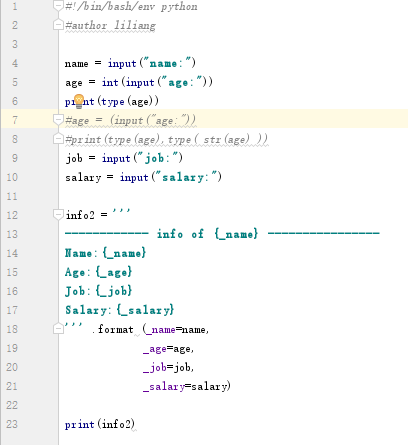
info2 = '''
------------ info of {_name} ----------------
Name:{_name}
Age:{_age}
Job:{_job}
Salary:{_salary}
''' .format (_name=name,
_age=age,
_job=job,
_salary=salary)
print(info2)
第三種方法:

info3 = '''
-------------info of {0} ------------------
Name:{0}
Age:{1}
Job:{2}
Salary:{3}
'''.format(name,age,job,salary)
print(info3)