
轉載:
阿新 • • 發佈:2017-06-06
組合 百萬 python 抽象 哪些 sta gic 有用 語義網 之前研究的CRF算法,在中文分詞,詞性標註,語義分析中應用非常廣泛。但是分詞技術只是NLP的一個基礎部分,在人機對話,機器翻譯中,深度學習將大顯身手。這篇文章,將展示深度學習的強大之處,區別於之前用符號來表示語義,深度學習用向量表達語義。這篇文章的最大價值在於,為初學者指明了研究方向。下面為轉載的原文:
在深度學習出現之前,文字所包含的意思是通過人為設計的符號和結構傳達給計算機的。本文討論了深度學習如何用向量來表示語義,如何更靈活地表示向量,如何用向量編碼的語義去完成翻譯,以及有待改進的地方。
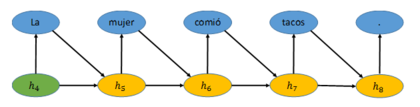
【編者按】Jonathan Mugan寫了兩篇博文來解釋計算機如何理解我們在社交媒體平臺上使用的語言,以及能理解到何種程度。本文是其中的第二篇。 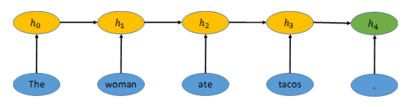 一旦信息被編碼為一個向量,我們就能將其解碼為另一種形式[2],如下圖所示。比如,RNN隨後可以將向量h4表示的句子翻譯(解碼)成西班牙語。它先根據已有向量h4生成一個最有可能的單詞。向量h4與新生成的單詞“La”一起又產生了向量h5。在向量h5的基礎上,RNN推出下一個最有可能出現的單詞,“mujer”。重復進行這個過程直到產生句號,網絡結構也到此為止。
一旦信息被編碼為一個向量,我們就能將其解碼為另一種形式[2],如下圖所示。比如,RNN隨後可以將向量h4表示的句子翻譯(解碼)成西班牙語。它先根據已有向量h4生成一個最有可能的單詞。向量h4與新生成的單詞“La”一起又產生了向量h5。在向量h5的基礎上,RNN推出下一個最有可能出現的單詞,“mujer”。重復進行這個過程直到產生句號,網絡結構也到此為止。
 使用這種編碼器—解碼器模型來做語言轉換,需要用一個包含大量源語言與目標語言的語料庫,基於這個語料庫訓練RNN網絡。這些RNN通常含有非常復雜的內部節點[3>,整個模型往往有幾百萬個參數需要學習。
我們可以將解碼的結果以任何形式輸出,例如解析樹(parse tree)[6],或是圖像的描述,假設有足夠多包含描述的圖像素材。當給圖片添加描述時,你可以用圖片訓練一個神經網絡來識別圖像中的物體。然後,把神經網絡輸出層的權重值作為這幅圖像的向量表示,再將這個向量用解碼器解析出圖像的描述[4,7]。(點擊這裏和這裏查看示例)
從合成語義到關註、記憶和問答
剛才的編碼器—解碼器方法似乎像是小把戲,我們接著就慢慢的來看看其在實際場景的應用。我們可以把解碼的過程想象成回答問題,“這句話該怎麽翻譯?”或者,已經有了待翻譯的句子,並且一部分內容已經翻譯了,那麽“接下去該怎麽寫?”
為了回答這些問題,算法首先需要記住一些狀態。在之前提到的例子中,系統只記住當前向量狀態h以及最後寫下的單詞。若是我們想讓它能運用之前全部所見所學該怎麽辦?在機器翻譯的例子裏,這就意味著在選擇下一個單詞時,要能夠回溯之前的狀態向量h0、h1、h2和h3。Bahdanau et al. [1]創造了能滿足這種需求的網絡結構。神經網絡學習如何在每個決策點確定之前哪個記憶狀態是最相關的。我們可以認為這是一個關註記憶的焦點。
它的意義在於,由於我們可以將概念和語句編碼為向量,並且我們可以使用大量的向量作為記憶元素,通過搜索能找到問題的最佳答案,那麽深度學習技術就能用文字來回答問題了。舉一個最簡單的例子[8],用表示問題的向量與表示記憶的向量做內積運算,把最吻合的結果作為問題的最佳回答。另一種方法是把問題和事實用多層神經網絡進行編碼,並把最後一層輸出傳給一個函數,函數的輸出即為答案。這些方法都是基於模擬問答的數據來訓練,然後用下文Weston[8]所示的方法回答問題。
使用這種編碼器—解碼器模型來做語言轉換,需要用一個包含大量源語言與目標語言的語料庫,基於這個語料庫訓練RNN網絡。這些RNN通常含有非常復雜的內部節點[3>,整個模型往往有幾百萬個參數需要學習。
我們可以將解碼的結果以任何形式輸出,例如解析樹(parse tree)[6],或是圖像的描述,假設有足夠多包含描述的圖像素材。當給圖片添加描述時,你可以用圖片訓練一個神經網絡來識別圖像中的物體。然後,把神經網絡輸出層的權重值作為這幅圖像的向量表示,再將這個向量用解碼器解析出圖像的描述[4,7]。(點擊這裏和這裏查看示例)
從合成語義到關註、記憶和問答
剛才的編碼器—解碼器方法似乎像是小把戲,我們接著就慢慢的來看看其在實際場景的應用。我們可以把解碼的過程想象成回答問題,“這句話該怎麽翻譯?”或者,已經有了待翻譯的句子,並且一部分內容已經翻譯了,那麽“接下去該怎麽寫?”
為了回答這些問題,算法首先需要記住一些狀態。在之前提到的例子中,系統只記住當前向量狀態h以及最後寫下的單詞。若是我們想讓它能運用之前全部所見所學該怎麽辦?在機器翻譯的例子裏,這就意味著在選擇下一個單詞時,要能夠回溯之前的狀態向量h0、h1、h2和h3。Bahdanau et al. [1]創造了能滿足這種需求的網絡結構。神經網絡學習如何在每個決策點確定之前哪個記憶狀態是最相關的。我們可以認為這是一個關註記憶的焦點。
它的意義在於,由於我們可以將概念和語句編碼為向量,並且我們可以使用大量的向量作為記憶元素,通過搜索能找到問題的最佳答案,那麽深度學習技術就能用文字來回答問題了。舉一個最簡單的例子[8],用表示問題的向量與表示記憶的向量做內積運算,把最吻合的結果作為問題的最佳回答。另一種方法是把問題和事實用多層神經網絡進行編碼,並把最後一層輸出傳給一個函數,函數的輸出即為答案。這些方法都是基於模擬問答的數據來訓練,然後用下文Weston[8]所示的方法回答問題。
![技術分享]() 下一個前沿方向是準確理解語義
剛剛討論的方法是關於如何以讀故事的方式回答問題,但是故事的一些重要情節一目了然,我們不必都寫下來。設想桌上放著一本書。計算機如何才能知道你挪動桌子的同時也挪動了書本?同樣的,計算機怎麽知道屋外只是下雨了呢?就如Marvin Minsky所問,計算機如何知道你能用一根繩索拉箱子而不是推箱子呢?因為這些事實我們不會都寫下來,故事將只限於能被我們算法所表示的知識。為了獲取這部分知識,我們的機器人(robot)將通過實景體驗或者模擬體驗來學習。
機器人必須經歷這種實景體驗,並用深度神經網絡編碼,基於此可以構建通用語義。如果機器人總是看到箱子從桌上掉下來,它則會根據這一事件創建一條神經回路。當媽媽說“天啊,箱子跌落下來了”,這條回路將會和單詞“跌落”結合。然後,作為一個成熟的機器人,當它再遇到句子“股票跌落了10個點”,根據這條神經回路,它就該理解其中的意思了。
機器人還需要把一般的實景體驗與抽象推理相結合。試著來理解這句話的含義“他去了垃圾場。”(He went to the junkyard.)WordNet只能提供一組與“went”相關的單詞。ConceptNet能把“went”和“go”聯系在一起,但是永遠也不明白“go”的真正意思是什麽。FrameNet有一個self-motion的框架,已經非常接近了,但還是不夠。深度學習能把句子編碼成向量,然後回答各種問題,諸如用“垃圾場”回答“他在哪兒”的問題。然而,沒有一種方法能夠傳遞出一個人在不同位置這層意思,也就是說他既不在這裏,也不在其它地方。我們需要有一個連接自然語言和語言邏輯的接口,或者是用神經網絡對抽象的邏輯進行編碼。
實踐:深度學習的入門資源
入門的方法有很多種。斯坦福有一門用深度學習做NLP的公開課。也可以去看Hinton教授在Coursera Course的課程。另外,Bengio教授和他的朋友們也編寫了一本簡明易懂的在線教材來講解深度學習。在開始編程之前,如果你使用Python語言,可以用Theano,如果你擅長Java語言,就用Deeplearning4j。
總結
計算機性能的提升和我們生活的日益數字化,推動了深度學習的革命。深度學習模型的成功是因為它們足夠大,往往帶有上百萬的參數。訓練這些模型需要足夠多的訓練數據和大量的計算。若要實現真正的智能,我們還需要走得更深。深度學習算法必須從實景體驗中習得,並概念化這種經驗,然後將這些經驗與抽象推理相結合
關於作者
下一個前沿方向是準確理解語義
剛剛討論的方法是關於如何以讀故事的方式回答問題,但是故事的一些重要情節一目了然,我們不必都寫下來。設想桌上放著一本書。計算機如何才能知道你挪動桌子的同時也挪動了書本?同樣的,計算機怎麽知道屋外只是下雨了呢?就如Marvin Minsky所問,計算機如何知道你能用一根繩索拉箱子而不是推箱子呢?因為這些事實我們不會都寫下來,故事將只限於能被我們算法所表示的知識。為了獲取這部分知識,我們的機器人(robot)將通過實景體驗或者模擬體驗來學習。
機器人必須經歷這種實景體驗,並用深度神經網絡編碼,基於此可以構建通用語義。如果機器人總是看到箱子從桌上掉下來,它則會根據這一事件創建一條神經回路。當媽媽說“天啊,箱子跌落下來了”,這條回路將會和單詞“跌落”結合。然後,作為一個成熟的機器人,當它再遇到句子“股票跌落了10個點”,根據這條神經回路,它就該理解其中的意思了。
機器人還需要把一般的實景體驗與抽象推理相結合。試著來理解這句話的含義“他去了垃圾場。”(He went to the junkyard.)WordNet只能提供一組與“went”相關的單詞。ConceptNet能把“went”和“go”聯系在一起,但是永遠也不明白“go”的真正意思是什麽。FrameNet有一個self-motion的框架,已經非常接近了,但還是不夠。深度學習能把句子編碼成向量,然後回答各種問題,諸如用“垃圾場”回答“他在哪兒”的問題。然而,沒有一種方法能夠傳遞出一個人在不同位置這層意思,也就是說他既不在這裏,也不在其它地方。我們需要有一個連接自然語言和語言邏輯的接口,或者是用神經網絡對抽象的邏輯進行編碼。
實踐:深度學習的入門資源
入門的方法有很多種。斯坦福有一門用深度學習做NLP的公開課。也可以去看Hinton教授在Coursera Course的課程。另外,Bengio教授和他的朋友們也編寫了一本簡明易懂的在線教材來講解深度學習。在開始編程之前,如果你使用Python語言,可以用Theano,如果你擅長Java語言,就用Deeplearning4j。
總結
計算機性能的提升和我們生活的日益數字化,推動了深度學習的革命。深度學習模型的成功是因為它們足夠大,往往帶有上百萬的參數。訓練這些模型需要足夠多的訓練數據和大量的計算。若要實現真正的智能,我們還需要走得更深。深度學習算法必須從實景體驗中習得,並概念化這種經驗,然後將這些經驗與抽象推理相結合
關於作者
 Jonathan是21CT的首席科學家。他主要研究機器學習和人工智能如何使用在文本和知識中讓計算機變得更智能。他在德克薩斯農工大學獲得心理學學士學位和工商管理碩士,在德克薩斯大學獲得計算機博士學位。他也是《 Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion》一書的作者。
Jonathan是21CT的首席科學家。他主要研究機器學習和人工智能如何使用在文本和知識中讓計算機變得更智能。他在德克薩斯農工大學獲得心理學學士學位和工商管理碩士,在德克薩斯大學獲得計算機博士學位。他也是《 Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion》一書的作者。
一旦信息被編碼為一個向量,我們就能將其解碼為另一種形式[2],如下圖所示。比如,RNN隨後可以將向量h4表示的句子翻譯(解碼)成西班牙語。它先根據已有向量h4生成一個最有可能的單詞。向量h4與新生成的單詞“La”一起又產生了向量h5。在向量h5的基礎上,RNN推出下一個最有可能出現的單詞,“mujer”。重復進行這個過程直到產生句號,網絡結構也到此為止。
使用這種編碼器—解碼器模型來做語言轉換,需要用一個包含大量源語言與目標語言的語料庫,基於這個語料庫訓練RNN網絡。這些RNN通常含有非常復雜的內部節點[3>,整個模型往往有幾百萬個參數需要學習。
我們可以將解碼的結果以任何形式輸出,例如解析樹(parse tree)[6],或是圖像的描述,假設有足夠多包含描述的圖像素材。當給圖片添加描述時,你可以用圖片訓練一個神經網絡來識別圖像中的物體。然後,把神經網絡輸出層的權重值作為這幅圖像的向量表示,再將這個向量用解碼器解析出圖像的描述[4,7]。(點擊這裏和這裏查看示例)
從合成語義到關註、記憶和問答
剛才的編碼器—解碼器方法似乎像是小把戲,我們接著就慢慢的來看看其在實際場景的應用。我們可以把解碼的過程想象成回答問題,“這句話該怎麽翻譯?”或者,已經有了待翻譯的句子,並且一部分內容已經翻譯了,那麽“接下去該怎麽寫?”
為了回答這些問題,算法首先需要記住一些狀態。在之前提到的例子中,系統只記住當前向量狀態h以及最後寫下的單詞。若是我們想讓它能運用之前全部所見所學該怎麽辦?在機器翻譯的例子裏,這就意味著在選擇下一個單詞時,要能夠回溯之前的狀態向量h0、h1、h2和h3。Bahdanau et al. [1]創造了能滿足這種需求的網絡結構。神經網絡學習如何在每個決策點確定之前哪個記憶狀態是最相關的。我們可以認為這是一個關註記憶的焦點。
它的意義在於,由於我們可以將概念和語句編碼為向量,並且我們可以使用大量的向量作為記憶元素,通過搜索能找到問題的最佳答案,那麽深度學習技術就能用文字來回答問題了。舉一個最簡單的例子[8],用表示問題的向量與表示記憶的向量做內積運算,把最吻合的結果作為問題的最佳回答。另一種方法是把問題和事實用多層神經網絡進行編碼,並把最後一層輸出傳給一個函數,函數的輸出即為答案。這些方法都是基於模擬問答的數據來訓練,然後用下文Weston[8]所示的方法回答問題。
Jonathan是21CT的首席科學家。他主要研究機器學習和人工智能如何使用在文本和知識中讓計算機變得更智能。他在德克薩斯農工大學獲得心理學學士學位和工商管理碩士,在德克薩斯大學獲得計算機博士學位。他也是《 Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion》一書的作者。轉載: