
storm 學習教程
轉自:http://blog.csdn.net/hrn1216/article/details/51538962
翻譯太累了,再也不想去翻譯了,真的太累了:
在這個教程中, 你將學到如何創建一個Storm topologies以及怎樣把它部署到storm集群上。本教程中,Java將作為主要使用的語言,但在一小部分示例中將會使用Python來闡述storm處理多語言的能力。
預備工作
本教程使用的例子來自於 storm-starter 項目. 我們建議你拷貝該項目並跟隨這個例子來進行學習。 請閱讀 Setting up a development environment 和 Creating a new Storm project 創建好相應的基礎環境。
Storm集群的組件
Storm集群在表面上與Hadoop集群相似。在hadoop上運行"MapReduce jobs",而在Storm上運行的是"topologies"。 "Jobs" and "topologies" 它們本身非常的不同 -- 一個關鍵的不同的是MapReduce job最終會完成並結束,而topology的消息處理將無限期進行下去(除非你kill它)。
在storm集群中,有兩類節點。Master節點運行守護進程稱為"Nimbus",它有點像 Hadoop 的 "JobTracker"。Nimbus負責集群的代碼分發,任務分配,故障監控。
每個工作節點運行的守護進程稱為"Supervisor"。Supervisor 負責監聽分配到它自己機器的作業,根據需要啟動和停止相應的工作進程,當然這些工作進程也是Nimbus分派給它的。每個工作進程執行topology的一個子集;一個運行的topology是由分布在多個機器的多個工作進程組成的。
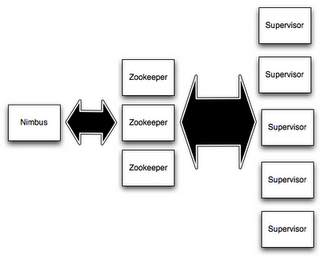
Nimbus 與 Supervisors 所有的協調工作是由 Zookeeper 集群完成的. 此外,Nimbus 守護進程 和 Supervisor 守護進程 是無狀態的,快速失敗的機制。 所有的狀態保存在Zookeeper上或者本地磁盤中。這就是說,你用kill -9殺掉Nimbus 或者Supervisors,它們重新啟動後就像什麽都沒有發生一樣,這樣的設計讓storm集群擁有令人難以置信的穩定性。
Topologies
在Storm上進行實時計算,你需要創建名為 "topologies" 的這麽個東西。一個topology是一個計算的圖,每個在topology中的節點(以下部分也稱作“組件”)包含了處理邏輯,以及多個節點間數據傳送的聯系和方式。運行一個topology很直接簡單的。第一,你把你的java code和它所有的依賴打成一個單獨的jar包。然後,你用如下的命令去運行就可以了。
storm jar all-my-code.jar org.apache.storm.MyTopology arg1 arg2
這個例子中運行的類是 org.apache.storm.MyTopology 且帶著兩個參數 arg1 和 arg2. 這個類的主要功能是定義topology,並被提交到Nimbus中。命令 storm jar 就是用來加載這個topology jar的。
因為topology的定義方式就是Thrift的結構,Nimbus也是一個Thrift服務,所以你可以用任何語言去創建topologies並提交。以上的例子是最簡單的方式去使用基於JVM的語言(比如java)創建的topology。請閱讀 Running topologies on a production cluster 來獲得更多的信息關於topology的啟動和停止。
流
Storm裏的核心抽象就是 "流"。流 是一個無界的 元組序列。Storm提供原始地、分布式地、可靠地方式 把一個流轉變成一個新的流。舉例來說,
你可以把一個 tweet 流 轉換成一個 趨勢主題 的流。
Storm中提供 流轉換 的最主要的原生方式是 "spouts" and "bolts"。Spouts 和 bolts 有相應的接口,你需要用你的應用的特定邏輯實現接口即可。
Spout是 流 的源頭。舉例來說,一個spout也許會從 Kestrel 隊列中讀取數據並以流的方式發射出來,亦或者一個spout也許會連接Twitter的API,
並發出一個關於tweets的流。
一個bolt可以消費任意數量的輸入流,並做一些處理,也可以由此發出一個新的流。復雜流的轉換,像從一個tweet流中計算出一個關於趨勢話題的流,它要求多個步驟,因此也需要多個bolt。Bolts 能做任何事情,運行方法,過濾元組,做流的聚合,流的連接,寫入數據庫等。
Spouts 和 bolts 組成的網絡 打包到 "topology" 中,它是頂級的抽象,是你需要提交到storm集群執行的東西。一個topology是一個由spout和bolt組成的 做流轉換 的圖,其中圖中的每個節點都可以是一個spout或者一個bolt。圖中的邊表明了bolt訂閱了哪些流,亦或是當一個spout或者bolt發射元組到流中,它發出的元組數據到訂閱這個流的所有bolt中去。
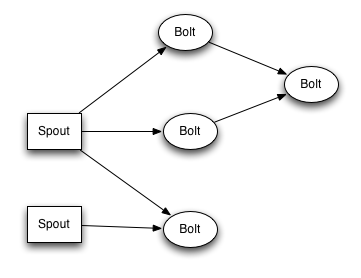
topology中節點之間的聯系表明了元組數據是怎樣去傳送的。舉例來說,Spout A 和 Bolt B 相連(A 到 B),Spout A 和 Bolt C 相連(A 到 C),Bolt B 和 Bolt C相連(B 到 C)。每當Spout A發出元組數據時,它會同時發給Bolt B 和 Bolt C。再者,所有Bolt B的輸出元組,也會發給Bolt C。
在topology中的每個節點都是並行運行的。因此在你的topology中,你可以為每個節點指定並行運行的數量,然後storm集群將會產生相應數量的線程來執行。
一個topology無限運行,直到你殺掉它才會停止。Storm將自動地重新分配失敗過的任務。此外,Storm保證不會有數據丟失,即便是機器掛掉,消息被丟棄。
數據模型
Storm用元組作為它的數據模型。一個元組是一個命名的,有值的,一般由過個字段組成的序列,序列中的每個字段可以是任何類型的對象。在沙箱之外,Storm提供所有的原始類型,字符串,byte數組作為元組的字段值。如果想用一個其他類型的對象,你需要實現a serializer 接口。
每個topology節點必須聲明輸出元組的字段。舉例來說,這個bolt聲明它將輸出帶有"double" and "triple"兩個字段的元組:
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
}
declareOutputFields 方法聲明了該bolt的輸出的字段 ["double", "triple"] .這個bolt的剩余部分將在接下來進行說明。
一個簡單topology
讓我們去看一個簡單的 topology,去探索更多的概念,去看一下它的代碼到底長什麽樣。讓我們看一下 ExclamationTopology 的定義,來自storm-starter的項目:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1");
這個topology包含了一個spout和兩個bolt,這個spout發出words,然後每個bolt都在自己的讀入字符串上加上"!!!"。
這些節點被安排成一條線:spout發給第一個bolt,第一個bolt發給第二個bolt。如果spout發出的元組數據是["bob"] 和 ["john"],通過第二個
bolt後,將發出["bob!!!!!!"] 和 ["john!!!!!!"]。
代碼中用 setSpout 和 setBolt 方法定義了節點。這些方法的輸入是 一個用戶指定的id,包含處理邏輯的對象,你希望該節點並行計算的數量。在這個例子中,這個 spout 的id是 "words" ,兩個bolt的id分別為 "exclaim1" 和 "exclaim2"。
包含處理邏輯的spout對象實現了 IRichSpout 接口,bolt對象實現了 IRichBolt 接口。
最後一個參數,是你希望該節點並行計算的數量是多少,這是可選的。它表明了會有多少線程會通過storm集群來執行這個組件(spout或bolt)。
如果你忽略它,Storm集群會分配單線程給該節點。
setBolt 返回一個 InputDeclarer 對象,它用來定義bolt的輸入。在這裏,bolt "exclaim1" 聲明了它希望通過shuffle分組的方式讀取 spout "words"中的所有元組。同理,Bolt "exclaim2" 聲明了它希望通過shuffle分組的方式讀取 bolt "exclaim1" 所發出的元組數據。
"shuffle 分組" 指元組數據 將會 隨機分布地 從輸入任務 到bolt任務中。在多個組件(spout或bolt)之間,這裏有很多數據分組的方式。
這在接下來的章節中會說明。
如果你希望bolt "exclaim2" 從 spout "words" 和 bolt "exclaim1" 讀取所有的元組數據,你需要像下面這樣定義:
builder.setBolt("exclaim2", new ExclamationBolt(), 5)
.shuffleGrouping("words")
.shuffleGrouping("exclaim1");
如你所見,輸入的定義可以是鏈式的,bolt可以指定多個源。
讓我們深入了解一下spout和bolt在topology中的實現。Spout負責發送新的數據到topology中。 TestWordSpout 在topology中每隔 100ms 發送了一個隨機的單詞,單詞來自列表["nathan", "mike", "jackson", "golda", "bertels"]。在 TestWordSpout 中的 nextTuple() 的實現細節如下:
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
如你所見,這個實現非常簡單明了。
ExclamationBolt 給輸入的字符串追加上 "!!!" 。 讓我們看一下 ExclamationBolt 的完整實現吧:
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
prepare 方法提供了一個 OutputCollector 對象,它用來發出元組數據給下遊節點。元組數據可以在任意時間從bolt發出 -- 可以在 prepare,execute, 或者 cleanup 方法,或者 在另一個線程,異步地發送。 這裏的 prepare 實現很簡單,初始化並保存了 OutputCollector 的引用,該引用將在接下來的execute 方法中使用。
execute 方法從該bolt的輸入中接收一個元組數據, ExclamationBolt 對象提取元組中的第一個字段,並追加字符串 "!!!" 。如果你實現的bolt訂閱了多個輸入源,你可以用 Tuple 中的 Tuple#getSourceComponent 方法來獲取你當前讀取的這個元組數據來自於哪個源。
在 execute 方法中,還有一點東西需要說明。 即輸入的元組作為第一個參數 發出 ,然後在最後一行中發出確認消息。這是Storm保證可靠性的API的一部分,它保證數據不會丟失,這在之後的教程會說明。
當一個Bolt將要停止、關閉時,它需要關閉當前打開的資源,此時 cleanup 方法可以被調用。 需要註意的是,這並不保證這個方法在storm集群中一定會被調用:舉例來說,如果機器上的任務爆發,這就不會調用這個方法。 cleanup 方法打算用於,當你在 local mode 上運行你的topology(模擬storm集群的仿真模式), 你能夠啟動和停止很多topology且不會遭受任何資源泄露的問題。
declareOutputFields 方法聲明 ExclamationBolt 發出一個名稱為 "word" 的帶一個字段的元組。
getComponentConfiguration 方法允許你從很多方面配置這個組件怎樣去運行。更多高級的話題,深入的解釋,請參見 Configuration.
通常像 cleanup 和 getComponentConfiguration 方法,在bolt中並不是必須去實現的。你可以用一個更為簡潔的方式,通過使用一個提供默認實現的基本類去定義bolt,這也許更為合適一些。 ExclamationBolt 可以通過繼承 BaseRichBolt,這會更簡單一點,就像這樣:
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
在local mode上運行ExclamationTopology
讓我們來看一下如何在本地模式上運行 ExclamationTopology ,看到它工作起來。
Storm有兩種操作模式:本地模式和分布式模式。在本地模式中,Storm通過線程模擬工作節點並在一個進程中完成執行。本地模式在用於開發和測試topology時是很有用處的。當你在本地模式中運行 storm-starter 項目中的 topology 時,你就能看到每個組件發送了什麽信息。你可以獲取更多關於在本地模式上運行topology的信息,請參見 Local mode。
在分布式模式中,Storm操作的是機器集群。當你提交一個topology給master,你也需要提交運行這個topology所必須的代碼。Master將會關註於分發你的代碼並分配worker去運行你的topology。如果worker掛掉,master將會重新分配這些代碼、topology到其他地方。你可以獲取更多關於在分布式模式上運行topology的信息,請參見 Running topologies on a production cluster。
這是在本地模式上運行 ExclamationTopology 的代碼:
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
首先,代碼中定義了單進程的偽集群,通過創建 LocalCluster 對象實現。提交topology到虛擬集群,和提交topology到真正的分布式集群是相同的。提交topology使用LocalCluster 的 submitTopology 方法。它需要的參數為 topology的名字,topology的配置,topology本身。
topology的名稱是為了標識topology,以便你之後可以停掉它。一個topology將無限期運行,直到你停掉它。
topology的配置可以從多個方面調整topology運行時的形態。這裏給出了兩個最為常見的配置:
- TOPOLOGY_WORKERS (用
setNumWorkers方法來設置) 表明你希望在storm集群中分配多少進程來執行你的topology。每個在topology中的組件(spout 或 bolt)將會被分配多個線程去執行。線程數的設置是通過組件的setBolt和setSpout方法。這些線程存在於worker進程中。 每個worker進程包含了處理一些組件的一些線程,例如,你橫跨集群指定了300個線程處理所有的組件,且指定了50個worker進程。也就是說,每個工作進程將執行6個線程, 其中的每一個可能又屬於不同的組件。調整topology的性能需要通過調整每個組件的並行線程數 和 工作進程中運行的線程數量。 - TOPOLOGY_DEBUG (用
setDebug方法來設置), 當設為true的時候,它將告訴Storm打印組件發出的每條信息。這在本地模式測試topology的時候很有用處。但是當你的topology在集群中運行的時候,或許你應該關掉它。
這裏有很多其他的topology的配置,更多細節請參見 the Javadoc for Config.
學習如何建立自己的開發環境,以便你能用本地模式運行你的topology(比如在eclipse裏),請參見 Creating a new Storm project.
流的分組方式
流的分組方式告訴一個topology,兩個組件是通過怎樣的方式傳遞元組數據。記住,spout 和 bolt 是並行執行在集群上的多個任務中的。如果你想知道一個topology是如何在任務層執行的,它也許就是這樣的:
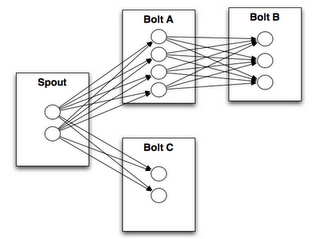
從上圖可知,bolt A 有4個task,bolt B有3個task。當bolt A的1個task 發出一個元組給 bolt B,那麽bolt A的這個task應該發給bolt B的哪個task呢?
流的分組方式通過告訴storm在兩個任務集(上圖的 bolt A 的任務集 合 bolt B的任務集)發送元組信息的方式 回答了這個問題。
在我們深入研究不同的流的分組策略前,我們先看一下另一個來自 storm-starter 項目的例子。 WordCountTopology 從spout讀取一句話,並分流給 WordCountBolt ,並統計句子中每個詞兒出現的次數:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));
SplitSentence 發出的元組來自於它接收到的每個句子的每個單詞,WordCount 在內存中保留一個map統計單詞的次數。每當WordCount
收到一個單詞,它將更新map的狀態並發出最新的單詞統計。
這裏有幾種不同的流的分組方式。
最簡單的分組方式稱作 "shuffle grouping" ,這種方式是將元組數據發送給隨機的任務。shuffle grouping 用於 WordCountTopology 中,RandomSentenceSpout 發送元組數據給 SplitSentence bolt 的部分。它很有效地把元組數組 均勻分給所有的 SplitSentence bolt 的任務。
一個更有趣的分組方式叫做 "fields grouping"。在本例中,字段分組用於 SplitSentence bolt 和 WordCount bolt 之間。它對 WordCount 的功能至關重要,它保證了相同的單詞只會去相同的任務中。否則,會有多個任務接收到相同的單詞,它們各自發出的單詞統計也是不正確的,因為它們獲得的都是不全的信息。 fields grouping 讓你可以通過字段來進行數據流的分組,這樣就導致了相同的字段值會進入到相同的任務中去。 WordCount 訂閱了 SplitSentence 的輸出流,並且是通過fields grouping的方式,本例針對 "word" 字段進行分組, 使相同的單詞進入了相同的任務,bolt 就可以給出正確的結果了。
Fields groupings 是 流的連接 和 聚合 的基礎實現,它也有其他很多的例子。
在底層, fields groupings 使用 mod hashing 算法來實現的。
這裏還有一些其他的分組方式,更多信息請參見 Concepts.
用其他語言定義Bolts
Bolts 可以用任何語言定義。用其他語言寫的 Bolts ,是以子進程的方式運行,storm與子進程通信的方式是 通過輸入輸出 JSON 數據來實現的。通信協議只需要1個100行的適配器代碼的庫, Storm附帶了 Ruby, python, and Fancy 的適配器的庫。
這是 SplitSentence bolt 的定義,來自於 WordCountTopology:
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super("python", "splitsentence.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
SplitSentence 覆蓋 ShellBolt 並聲明用 python ,運行文件為 splitsentence.py. 這是 splitsentence.py的實現:
import storm
class SplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
SplitSentenceBolt().run()
更多關於用其他語言編寫 spout 和 bolt 的信息,創建topology的信息 (以及完全避免 JVM 的方式), 請參見 Using non-JVM languages with Storm.
保證消息的處理
本教程前面部分,我們跳過了一些方面如元組是怎麽發出的,這些方面涉及了Storm的可靠性的API:Storm是如何保證每條來自於spout的消息會被完全完整地被處理。 參見 Guaranteeing message processing 信息看它是如何工作的,以及作為用戶的你,如何使用storm的可靠性能的這一優點。
事務型的topologies
Storm 保證每條信息至少被處理一次. 一個大眾化的問題被提出: "你怎麽在storm頂層上進行計數操作?計數值會不會超量?" Storm 有一個特性稱作事務型topologies,在絕大部分的計算場景中,它的實現可以讓消息只傳遞一次。獲取更多事務型的topologies的信息: here.
分布式 RPC
本教程介紹了storm頂層的核心流的處理過程。storm原生部分 是有很多的事情可以去做的,其中最有意思的應用就是storm的分布式RPC,它具有很強的並行計算的性能。獲取更多的關於分布式RPC的信息: here.
結論
這個教程給出了一個關於storm開發,測試,部署的概覽,剩余的文檔將深入storm的每個方面。
storm 學習教程