
Tensorflow學習教程------過擬合
阿新 • • 發佈:2017-10-08
模型 float softmax 一個 返回 之間 zeros 函數 size
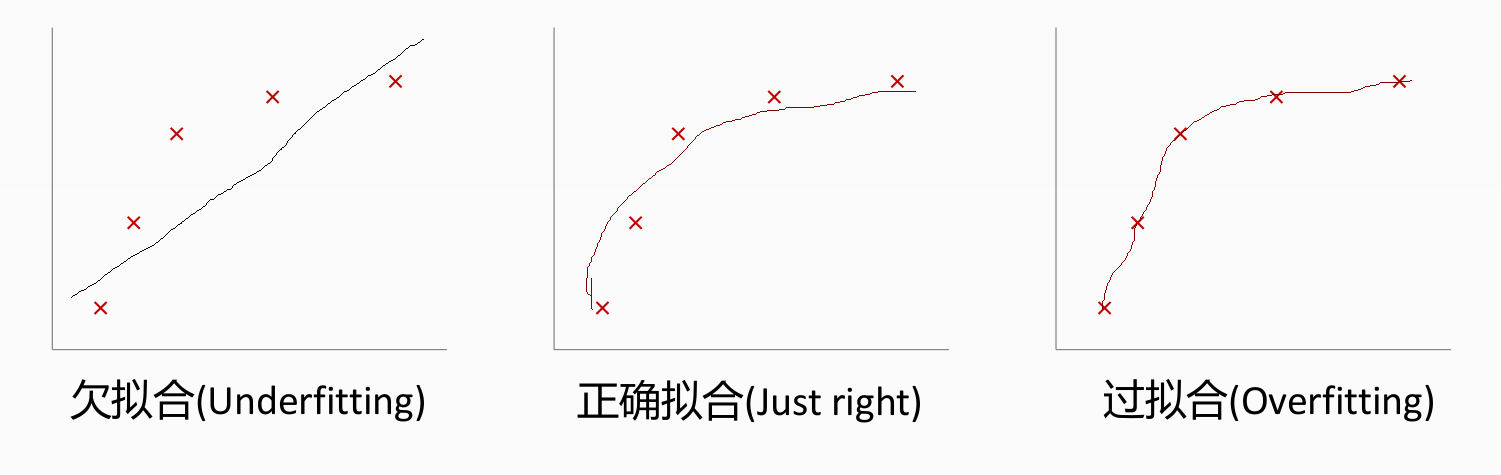
回歸:過擬合情況
/
分類過擬合
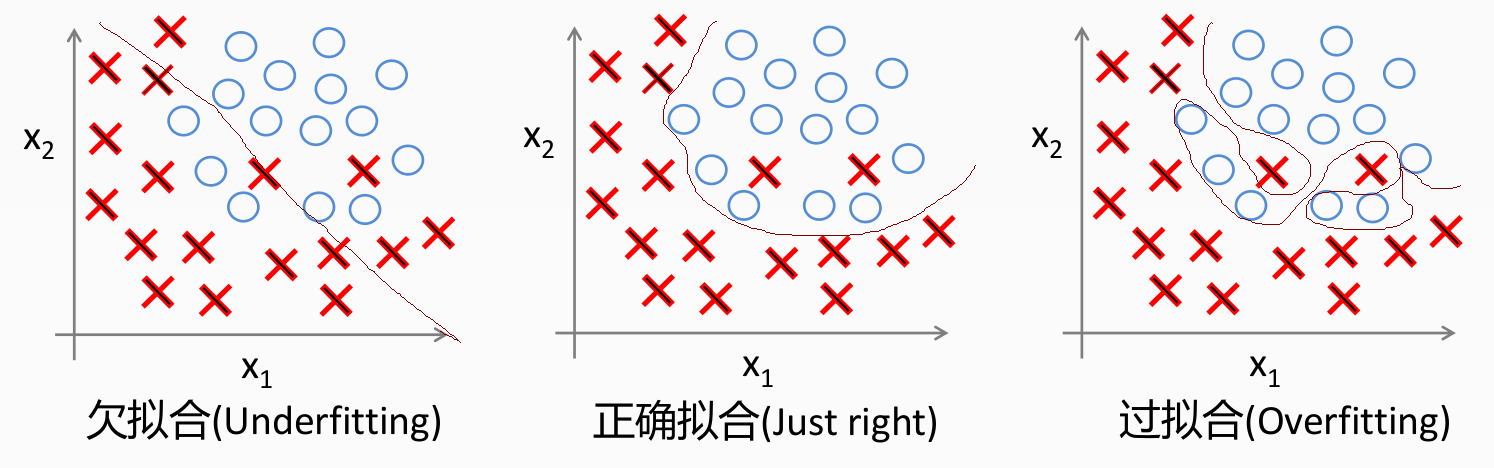
防止過擬合的方法有三種:
1 增加數據集
2 添加正則項
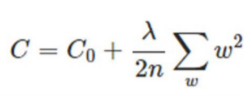
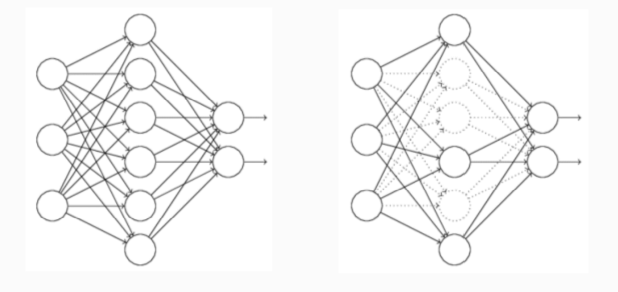
3 Dropout,意思就是訓練的時候隱層神經元每次隨機抽取部分參與訓練。部分不參與
最後對之前普通神經網絡分類mnist數據集的代碼進行優化,初始化權重參數的時候采用截斷正態分布,偏置項加常數,采用dropout防止過擬合,加三層隱層神經元,最後的準確率達到97%以上。代碼如下
# coding: utf-8 # 微信公眾號:深度學習與神經網絡 # Github:https://github.com/Qinbf # 優酷頻道:http://i.youku.com/sdxxqbf importtensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #載入數據集 mnist = input_data.read_data_sets("MNIST_data",one_hot=True) #每個批次的大小 batch_size = 100 #計算一共有多少個批次 n_batch = mnist.train.num_examples // batch_size #定義兩個placeholder x = tf.placeholder(tf.float32,[None,784]) y = tf.placeholder(tf.float32,[None,10]) keep_prob=tf.placeholder(tf.float32) #創建一個簡單的神經網絡 W1 = tf.Variable(tf.truncated_normal([784,2000],stddev=0.1)) b1 = tf.Variable(tf.zeros([2000])+0.1) L1 = tf.nn.tanh(tf.matmul(x,W1)+b1) L1_drop = tf.nn.dropout(L1,keep_prob) W2 = tf.Variable(tf.truncated_normal([2000,2000],stddev=0.1)) b2 = tf.Variable(tf.zeros([2000])+0.1) L2= tf.nn.tanh(tf.matmul(L1_drop,W2)+b2) L2_drop = tf.nn.dropout(L2,keep_prob) W3 = tf.Variable(tf.truncated_normal([2000,1000],stddev=0.1)) b3 = tf.Variable(tf.zeros([1000])+0.1) L3 = tf.nn.tanh(tf.matmul(L2_drop,W3)+b3) L3_drop = tf.nn.dropout(L3,keep_prob) W4 = tf.Variable(tf.truncated_normal([1000,10],stddev=0.1)) b4 = tf.Variable(tf.zeros([10])+0.1) prediction = tf.nn.softmax(tf.matmul(L3_drop,W4)+b4) #二次代價函數 # loss = tf.reduce_mean(tf.square(y-prediction)) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction)) #使用梯度下降法 train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化變量 init = tf.global_variables_initializer() #結果存放在一個布爾型列表中 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一維張量中最大的值所在的位置 #求準確率 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session() as sess: sess.run(init) for epoch in range(31): for batch in range(n_batch): batch_xs,batch_ys = mnist.train.next_batch(batch_size) sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7}) test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0}) train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0}) print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
結果如下
Iter 0,Testing Accuracy 0.913,Training Accuracy 0.909146 Iter 1,Testing Accuracy 0.9318,Training Accuracy 0.927218 Iter 2,Testing Accuracy 0.9397,Training Accuracy 0.9362 Iter 3,Testing Accuracy 0.943,Training Accuracy 0.940637 Iter 4,Testing Accuracy 0.9449,Training Accuracy 0.945746 Iter 5,Testing Accuracy 0.9489,Training Accuracy 0.949491 Iter 6,Testing Accuracy 0.9505,Training Accuracy 0.9522 Iter 7,Testing Accuracy 0.9542,Training Accuracy 0.956 Iter 8,Testing Accuracy 0.9543,Training Accuracy 0.957782 Iter 9,Testing Accuracy 0.954,Training Accuracy 0.959 Iter 10,Testing Accuracy 0.9558,Training Accuracy 0.959582 Iter 11,Testing Accuracy 0.9594,Training Accuracy 0.963146 Iter 12,Testing Accuracy 0.959,Training Accuracy 0.963746 Iter 13,Testing Accuracy 0.961,Training Accuracy 0.964764 Iter 14,Testing Accuracy 0.9605,Training Accuracy 0.9658 Iter 15,Testing Accuracy 0.9635,Training Accuracy 0.967528 Iter 16,Testing Accuracy 0.9639,Training Accuracy 0.968582 Iter 17,Testing Accuracy 0.9644,Training Accuracy 0.969309 Iter 18,Testing Accuracy 0.9651,Training Accuracy 0.969564 Iter 19,Testing Accuracy 0.9664,Training Accuracy 0.971073 Iter 20,Testing Accuracy 0.9654,Training Accuracy 0.971746 Iter 21,Testing Accuracy 0.9664,Training Accuracy 0.971764 Iter 22,Testing Accuracy 0.9682,Training Accuracy 0.973128 Iter 23,Testing Accuracy 0.9679,Training Accuracy 0.973346 Iter 24,Testing Accuracy 0.9681,Training Accuracy 0.975164 Iter 25,Testing Accuracy 0.969,Training Accuracy 0.9754 Iter 26,Testing Accuracy 0.9706,Training Accuracy 0.975764 Iter 27,Testing Accuracy 0.9694,Training Accuracy 0.975837 Iter 28,Testing Accuracy 0.9703,Training Accuracy 0.977109 Iter 29,Testing Accuracy 0.97,Training Accuracy 0.976946 Iter 30,Testing Accuracy 0.9715,Training Accuracy 0.977491
Testing Accuracy和Training Accuracy之間的差距為0.005991
dropout值設置為1的時候,
Iter 0,Testing Accuracy 0.9471,Training Accuracy 0.955037 Iter 1,Testing Accuracy 0.9597,Training Accuracy 0.9738 Iter 2,Testing Accuracy 0.9616,Training Accuracy 0.980928 Iter 3,Testing Accuracy 0.9661,Training Accuracy 0.985091 Iter 4,Testing Accuracy 0.9674,Training Accuracy 0.987709 Iter 5,Testing Accuracy 0.9692,Training Accuracy 0.989255 Iter 6,Testing Accuracy 0.9692,Training Accuracy 0.990146 Iter 7,Testing Accuracy 0.9708,Training Accuracy 0.991182 Iter 8,Testing Accuracy 0.9711,Training Accuracy 0.991982 Iter 9,Testing Accuracy 0.9712,Training Accuracy 0.9924 Iter 10,Testing Accuracy 0.971,Training Accuracy 0.992691 Iter 11,Testing Accuracy 0.9706,Training Accuracy 0.993055 Iter 12,Testing Accuracy 0.971,Training Accuracy 0.993309 Iter 13,Testing Accuracy 0.9717,Training Accuracy 0.993528 Iter 14,Testing Accuracy 0.9719,Training Accuracy 0.993764 Iter 15,Testing Accuracy 0.9715,Training Accuracy 0.993927 Iter 16,Testing Accuracy 0.9715,Training Accuracy 0.994091 Iter 17,Testing Accuracy 0.9714,Training Accuracy 0.994291 Iter 18,Testing Accuracy 0.9719,Training Accuracy 0.9944 Iter 19,Testing Accuracy 0.9719,Training Accuracy 0.994564 Iter 20,Testing Accuracy 0.9722,Training Accuracy 0.994673 Iter 21,Testing Accuracy 0.9725,Training Accuracy 0.994855 Iter 22,Testing Accuracy 0.9731,Training Accuracy 0.994891 Iter 23,Testing Accuracy 0.9721,Training Accuracy 0.994928 Iter 24,Testing Accuracy 0.9722,Training Accuracy 0.995018 Iter 25,Testing Accuracy 0.9725,Training Accuracy 0.995109 Iter 26,Testing Accuracy 0.9729,Training Accuracy 0.9952 Iter 27,Testing Accuracy 0.9726,Training Accuracy 0.995255 Iter 28,Testing Accuracy 0.9725,Training Accuracy 0.995327 Iter 29,Testing Accuracy 0.9725,Training Accuracy 0.995364 Iter 30,Testing Accuracy 0.9722,Training Accuracy 0.995437
Testing Accuracy和Training Accuracy之間的差距為0.23237,本次實驗中只有60000個樣本,當樣本量到達幾百萬的時候,這個差距值會更大,也就是訓練出的模型在訓練數據集中效果非常好,幾乎滿足了任意一個樣本,但是在測試數據集中效果卻很差,此時就是典型的過擬合現象。
所以一般稍微復雜的網絡中都會加入dropout,防止過擬合。
Tensorflow學習教程------過擬合