
presto0.176概述
presto是什麽
是Facebook開源的,完全基於內存的並?計算,分布式SQL交互式查詢引擎
是一種Massively parallel processing (MPP)架構,多個節點管道式執?
?持任意數據源(通過擴展式Connector組件),數據規模GB~PB級
使用的技術,如向量計算,動態編譯執?計劃,優化的ORC和Parquet Reader等
presto不太支持存儲過程,支持部分標準sql
presto的查詢速度比hive快5-10倍
上面講述了presto是什麽,查詢速度,現在來看看presto適合幹什麽
適合:PB級海量數據復雜分析,交互式SQL查詢,?持跨數據源查詢
不適合:多個大表的join操作,因為presto是基於內存的,多張大表在內存裏可能放不下
和hive的對比:
hive是一個數據倉庫,是一個交互式比較弱一點的查詢引擎,交互式沒有presto那麽強,而且只能訪問hdfs的數據
presto是一個交互式查詢引擎,可以在很短的時間內返回查詢結果,秒級,分鐘級,能訪問很多數據源
hive在查詢100Gb級別的數據時,消耗時間已經是分鐘級了
但是presto是取代不了hive的,因為p全部的數據都是在內存中,限制了在內存中的數據集大小,比如多個大表的join,這些大表是不能完全放進內存的,實際應用中,對於在presto的查詢是有一定規定條件的,比比如說一個查詢在presto查詢超過30分鐘,那就kill掉吧,說明不適合在presto上使用,主要原因是,查詢過大的話,會占用整個集群的資源,這會導致你後續的查詢是沒有資源進行查詢的,這跟presto的設計理念是沖突的,就像是你進行一個查詢,但是要等個5分鐘才有資源繼續查詢,這是很不合理的,交互式就變得弱了很多
presto基本架構
在談presto架構之前,先回顧下hive的架構
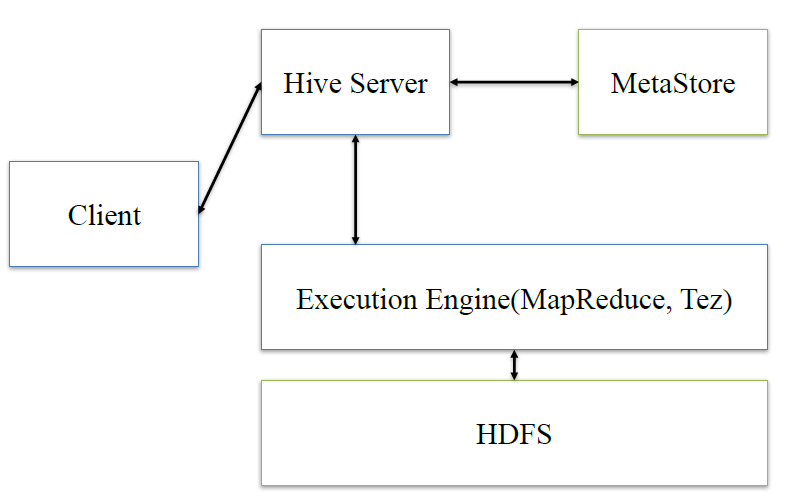
hive:client將查詢請求發送到hive server,它會和metastor交互,獲取表的元信息,如表的位置結構等,之後hive server會進行語法解析,解析成語法樹,變成查詢計劃,進行優化後,將查詢計劃交給執行引擎,默認是MR,然後翻譯成MR
presto:presto是在它內部做hive類似的邏輯
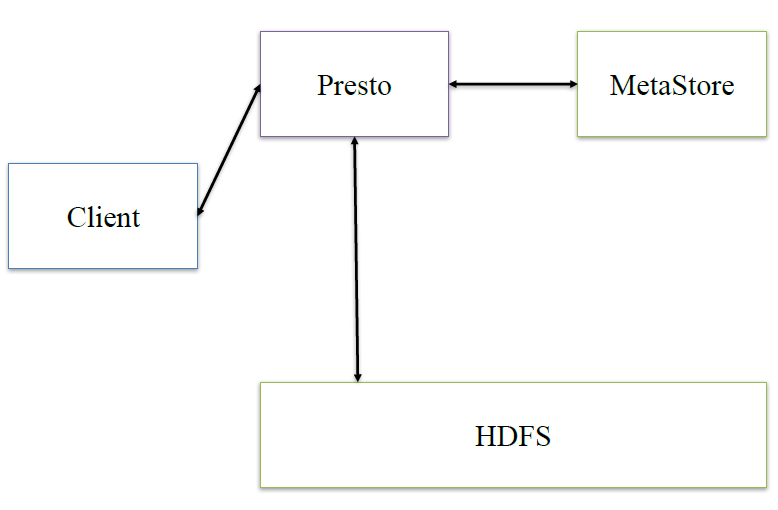
接下來,深入看下presto的內部架構
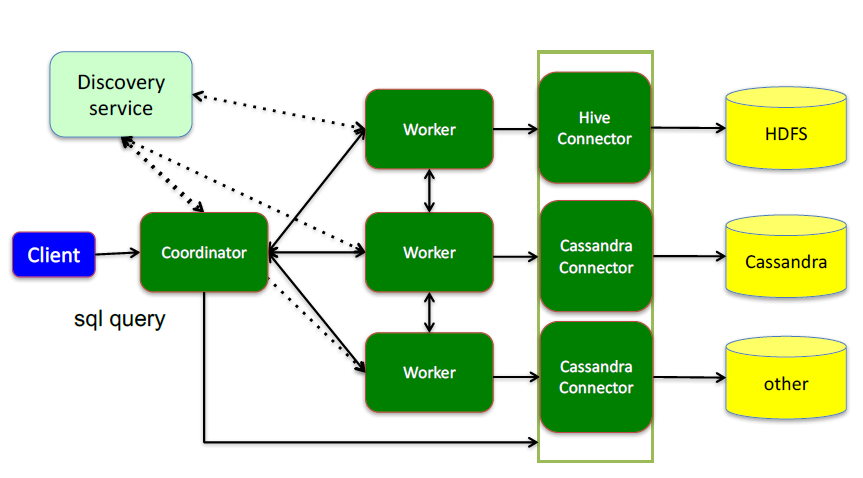
這裏面三個服務:
Coordinator,是一個中心的查詢角色,它主要的一個作用是接受查詢請求,將他們轉換成各種各樣的任務,將任務拆解後分發到多個worker去執行各種任務的節點
1、解析SQL語句
2、?成執?計劃
3、分發執?任務給Worker節點執?
Worker,是一個真正的計算的節點,執行任務的節點,它接收到task後,就會到對應的數據源裏面,去把數據提取出來,提取方式是通過各種各樣的connector:
1、負責實際執?查詢任務
Discovery service,是將coordinator和woker結合到一起的服務:
1、Worker節點啟動後向Discovery Server服務註冊
2、Coordinator從Discovery Server獲得Worker節點
coordinator和woker之間的關系是怎麽維護的呢?是通過Discovery Server,所有的worker都把自己註冊到Discovery Server上,Discovery Server是一個發現服務的service,Discovery Server發現服務之後,coordinator便知道在我的集群中有多少個worker能夠給我工作,然後我分配工作到worker時便有了根據
最後,presto是通過connector plugin獲取數據和元信息的,它不是?個數據存儲引擎,不需要有數據,presto為其他數據存儲系統提供了SQL能?,客戶端協議是HTTP+JSON
Presto支持的數據源和存儲格式
Hadoop/Hive connector與存儲格式:
HDFS,ORC,RCFILE,Parquet,SequenceFile,Text
開源數據存儲系統:
MySQL & PostgreSQL,Cassandra,Kafka,Redis
其他:
MongoDB,ElasticSearch,HBase
最後,一些零散的知識點
presto適合pb級的海量數據查詢分析,不是說把pb的數據放進內存,比如一張pb表,查詢count,vag這種有個特點,雖然數據很多,但是最終的查詢結果很小,這種就不會把數據都放到內存裏面,只是在運算的過程中,拿出一些數據放內存,然後計算,在拋出,在拿,這種的內存占用量是很小的,但是join這種,在運算的中間過程會產生大量的數據,或者說那種查詢的數據不大,但是生成的數據量很大,這種也是不合適用presto的,但不是說不能做,只是會占用大量內存,消耗很長的時間,這種hive合適點
presto算是hive的一個補充,需要盡快得出結果的用presto,否則用hive
work是部署的時候就事先部署好的,work啟動100個,使用的work不一定100個,而是根據coordinator來決定拆分成多少個task,然後分發到多少個work去
一個coordinator可能同時又多個用戶在請求query,然後共享work的去執行,這是一個共享的集群
coordinator和discovery server可以啟動在一個節點一個進程,也可以放在不同的node上,但是現在公司大部分都是放在一個節點上,一個launcher start會同時把上述兩個啟動起來
對於presto的容錯,如果某個worker掛掉了,discovery server會發現並通知coordinator
但是對於一個query,是沒有容錯的,一旦一個work掛了,那麽整個qurey就是敗了
對於coordinator和discovery server節點的單點故障,presto還沒有開始處理這個問題貌似
presto0.176概述