
Flink 環境部署
Flink 原理與實現:架構和拓撲概覽
架構
要了解一個系統,一般都是從架構開始。我們關心的問題是:系統部署成功後各個節點都啟動了哪些服務,各個服務之間又是怎麽交互和協調的。下方是 Flink 集群啟動後架構圖。
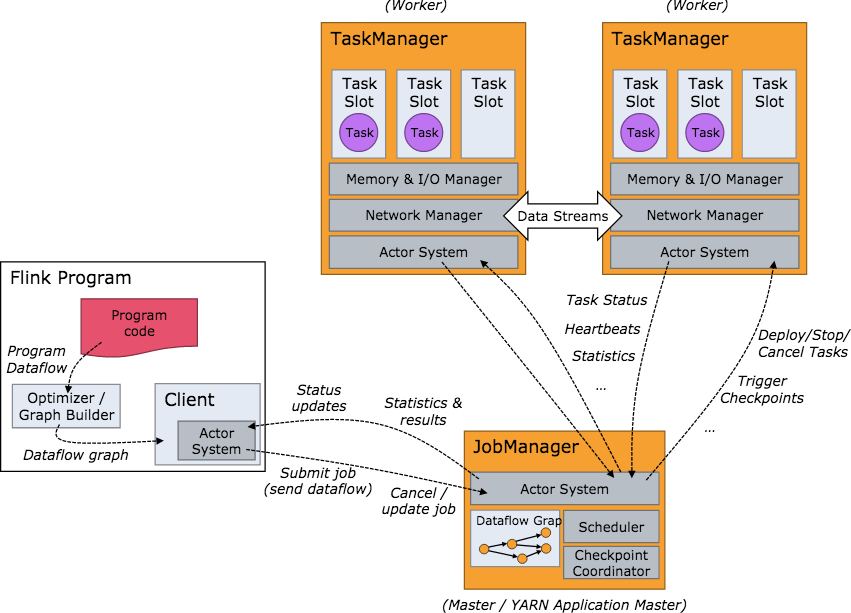
當 Flink 集群啟動後,首先會啟動一個 JobManger 和一個或多個的 TaskManager。由 Client 提交任務給 JobManager,JobManager 再調度任務到各個 TaskManager 去執行,然後 TaskManager 將心跳和統計信息匯報給 JobManager。TaskManager 之間以流的形式進行數據的傳輸。上述三者均為獨立的 JVM 進程。
Client 為提交 Job 的客戶端,可以是運行在任何機器上(與 JobManager 環境連通即可)。提交 Job 後,Client 可以結束進程(Streaming的任務),也可以不結束並等待結果返回。
JobManager 主要負責調度 Job 並協調 Task 做 checkpoint,職責上很像 Storm 的 Nimbus。從 Client 處接收到 Job 和 JAR 包等資源後,會生成優化後的執行計劃,並以 Task 的單元調度到各個 TaskManager 去執行。
TaskManager 在啟動的時候就設置好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為線程。從 JobManager 處接收需要部署的 Task,部署啟動後,與自己的上遊建立 Netty 連接,接收數據並處理。
可以看到 Flink 的任務調度是多線程模型,並且不同Job/Task混合在一個 TaskManager 進程中。雖然這種方式可以有效提高 CPU 利用率,但是個人不太喜歡這種設計,因為不僅缺乏資源隔離機制,同時也不方便調試。類似 Storm 的進程模型,一個JVM 中只跑該 Job 的 Tasks 實際應用中更為合理。
Job 例子
本文所示例子為 flink-1.0.x 版本
我們使用 Flink 自帶的 examples 包中的 SocketTextStreamWordCount,這是一個從 socket 流中統計單詞出現次數的例子。
首先,使用 netcat 啟動本地服務器:
$ nc -l 9000
然後提交 Flink 程序
$ bin/flink run examples/streaming/SocketTextStreamWordCount.jar \--hostname 10.218.130.9 \--port 9000
在netcat端輸入單詞並監控 taskmanager 的輸出可以看到單詞統計的結果。
SocketTextStreamWordCount 的具體代碼如下:
public static void main(String[] args) throws Exception {// 檢查輸入final ParameterTool params = ParameterTool.fromArgs(args);...// set up the execution environmentfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// get input dataDataStream<String> text =env.socketTextStream(params.get("hostname"), params.getInt("port"), ‘\n‘, 0);DataStream<Tuple2<String, Integer>> counts =// split up the lines in pairs (2-tuples) containing: (word,1)text.flatMap(new Tokenizer())// group by the tuple field "0" and sum up tuple field "1".keyBy(0).sum(1);counts.print();// execute programenv.execute("WordCount from SocketTextStream Example");} |
我們將最後一行代碼 env.execute 替換成 System.out.println(env.getExecutionPlan()); 並在本地運行該代碼(並發度設為2),可以得到該拓撲的邏輯執行計劃圖的 JSON 串,將該 JSON 串粘貼到http://flink.apache.org/visualizer/ 中,能可視化該執行圖。

但這並不是最終在 Flink 中運行的執行圖,只是一個表示拓撲節點關系的計劃圖,在 Flink 中對應了 SteramGraph。另外,提交拓撲後(並發度設為2)還能在 UI 中看到另一張執行計劃圖,如下所示,該圖對應了 Flink 中的 JobGraph。
Graph
看起來有點亂,怎麽有這麽多不一樣的圖。實際上,還有更多的圖。Flink 中的執行圖可以分成四層:StreamGraph -> JobGraph -> ExecutionGraph -> 物理執行圖。
StreamGraph:是根據用戶通過 Stream API 編寫的代碼生成的最初的圖。用來表示程序的拓撲結構。
JobGraph:StreamGraph經過優化後生成了 JobGraph,提交給 JobManager 的數據結構。主要的優化為,將多個符合條件的節點 chain 在一起作為一個節點,這樣可以減少數據在節點之間流動所需要的序列化/反序列化/傳輸消耗。
ExecutionGraph:JobManager 根據 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的並行化版本,是調度層最核心的數據結構。
物理執行圖:JobManager 根據 ExecutionGraph 對 Job 進行調度後,在各個TaskManager 上部署 Task 後形成的“圖”,並不是一個具體的數據結構。
例如上文中的2個並發度(Source為1個並發度)的 SocketTextStreamWordCount 四層執行圖的演變過程如下圖所示(點擊查看大圖):
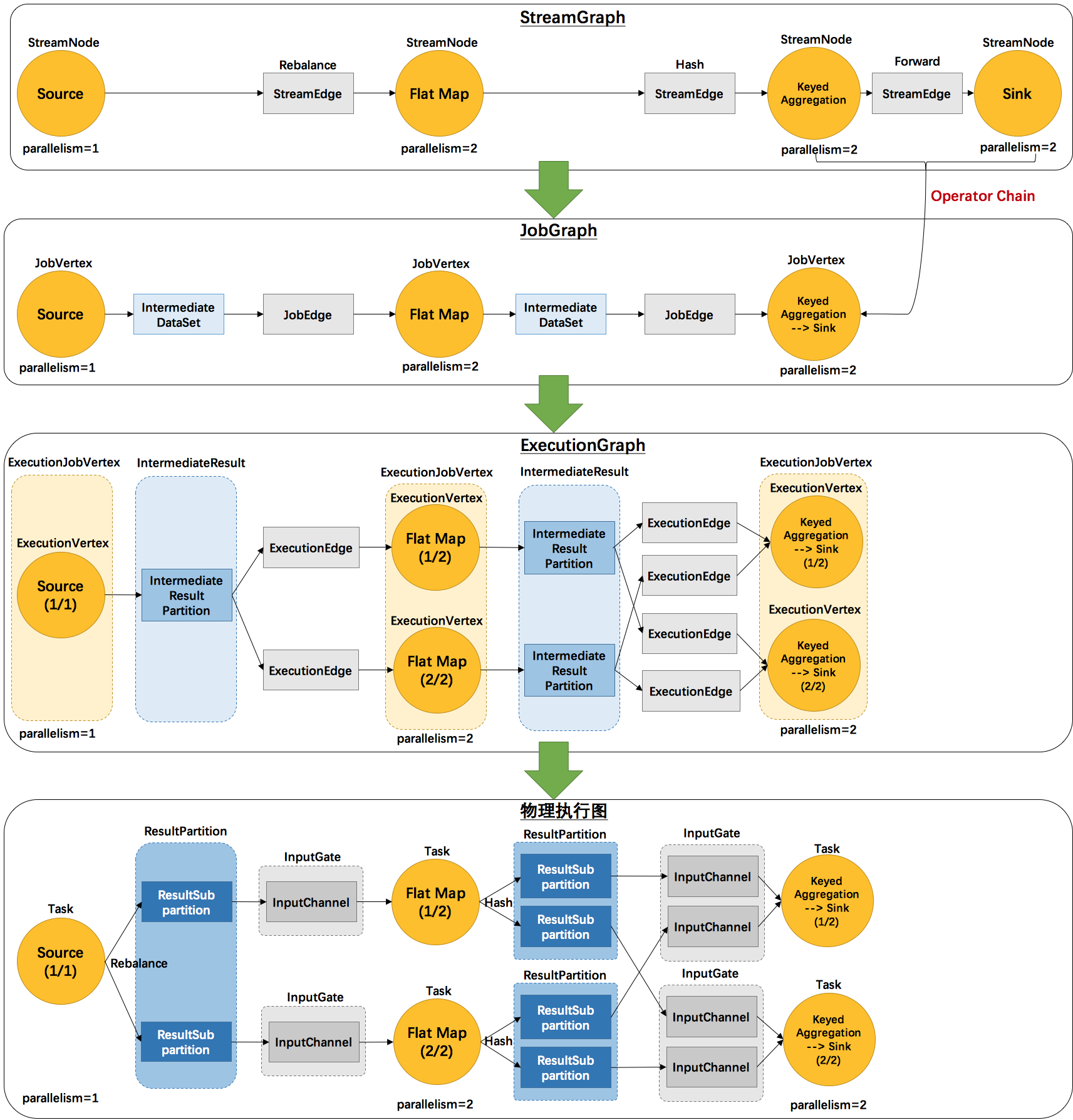
這裏對一些名詞進行簡單的解釋。
StreamGraph:根據用戶通過 Stream API 編寫的代碼生成的最初的圖。
StreamNode:用來代表 operator 的類,並具有所有相關的屬性,如並發度、入邊和出邊等。
StreamEdge:表示連接兩個StreamNode的邊。
JobGraph:StreamGraph經過優化後生成了 JobGraph,提交給 JobManager 的數據結構。
JobVertex:經過優化後符合條件的多個StreamNode可能會chain在一起生成一個JobVertex,即一個JobVertex包含一個或多個operator,JobVertex的輸入是JobEdge,輸出是IntermediateDataSet。
IntermediateDataSet:表示JobVertex的輸出,即經過operator處理產生的數據集。producer是JobVertex,consumer是JobEdge。
JobEdge:代表了job graph中的一條數據傳輸通道。source 是 IntermediateDataSet,target 是 JobVertex。即數據通過JobEdge由IntermediateDataSet傳遞給目標JobVertex。
ExecutionGraph:JobManager 根據 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的並行化版本,是調度層最核心的數據結構。
ExecutionJobVertex:和JobGraph中的JobVertex一一對應。每一個ExecutionJobVertex都有和並發度一樣多的 ExecutionVertex。
ExecutionVertex:表示ExecutionJobVertex的其中一個並發子任務,輸入是ExecutionEdge,輸出是IntermediateResultPartition。
IntermediateResult:和JobGraph中的IntermediateDataSet一一對應。一個IntermediateResult包含多個IntermediateResultPartition,其個數等於該operator的並發度。
IntermediateResultPartition:表示ExecutionVertex的一個輸出分區,producer是ExecutionVertex,consumer是若幹個ExecutionEdge。
ExecutionEdge:表示ExecutionVertex的輸入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一個。
Execution:是執行一個 ExecutionVertex 的一次嘗試。當發生故障或者數據需要重算的情況下 ExecutionVertex 可能會有多個 ExecutionAttemptID。一個 Execution 通過 ExecutionAttemptID 來唯一標識。JM和TM之間關於 task 的部署和 task status 的更新都是通過 ExecutionAttemptID 來確定消息接受者。
物理執行圖:JobManager 根據 ExecutionGraph 對 Job 進行調度後,在各個TaskManager 上部署 Task 後形成的“圖”,並不是一個具體的數據結構。
Task:Execution被調度後在分配的 TaskManager 中啟動對應的 Task。Task 包裹了具有用戶執行邏輯的 operator。
ResultPartition:代表由一個Task的生成的數據,和ExecutionGraph中的IntermediateResultPartition一一對應。
ResultSubpartition:是ResultPartition的一個子分區。每個ResultPartition包含多個ResultSubpartition,其數目要由下遊消費 Task 數和 DistributionPattern 來決定。
InputGate:代表Task的輸入封裝,和JobGraph中JobEdge一一對應。每個InputGate消費了一個或多個的ResultPartition。
InputChannel:每個InputGate會包含一個以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一對應,也和ResultSubpartition一對一地相連,即一個InputChannel接收一個ResultSubpartition的輸出。
那麽 Flink 為什麽要設計這4張圖呢,其目的是什麽呢?Spark 中也有多張圖,數據依賴圖以及物理執行的DAG。其目的都是一樣的,就是解耦,每張圖各司其職,每張圖對應了 Job 不同的階段,更方便做該階段的事情。我們給出更完整的 Flink Graph 的層次圖。
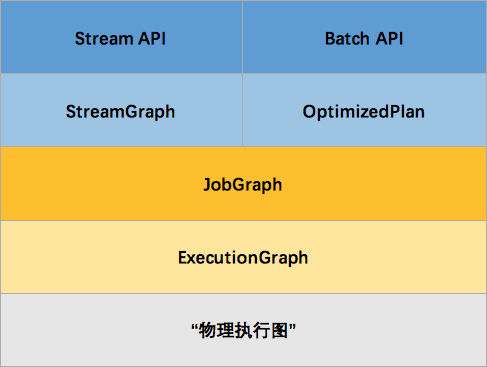
首先我們看到,JobGraph 之上除了 StreamGraph 還有 OptimizedPlan。OptimizedPlan 是由 Batch API 轉換而來的。StreamGraph 是由 Stream API 轉換而來的。為什麽 API 不直接轉換成 JobGraph?因為,Batch 和 Stream 的圖結構和優化方法有很大的區別,比如 Batch 有很多執行前的預分析用來優化圖的執行,而這種優化並不普適於 Stream,所以通過 OptimizedPlan 來做 Batch 的優化會更方便和清晰,也不會影響 Stream。JobGraph 的責任就是統一 Batch 和 Stream 的圖,用來描述清楚一個拓撲圖的結構,並且做了 chaining 的優化,chaining 是普適於 Batch 和 Stream 的,所以在這一層做掉。ExecutionGraph 的責任是方便調度和各個 tasks 狀態的監控和跟蹤,所以 ExecutionGraph 是並行化的 JobGraph。而“物理執行圖”就是最終分布式在各個機器上運行著的tasks了。所以可以看到,這種解耦方式極大地方便了我們在各個層所做的工作,各個層之間是相互隔離的。
後續的文章,將會詳細介紹 Flink 是如何生成這些執行圖的。由於我目前關註 Flink 的流處理功能,所以主要有以下內容:
如何生成 StreamGraph
如何生成 JobGraph
如何生成 ExecutionGraph
如何進行調度(如何生成物理執行圖)
Flink官方文檔翻譯:安裝部署(本地模式)
本文主要介紹如何將Flink以本地模式運行在單機上。
下載
進入下載頁面。如果你想讓Flink與Hadoop進行交互(如HDFS或者HBase),請選擇一個與你的Hadoop版本相匹配的Flink包。當你不確定或者只是想運行在本地文件系統上,請選擇Hadoop 1.2.x對應的包。
環境準備
Flink 可以運行在 Linux、Mac OS X 和 Windows 上。本地模式的安裝唯一需要的只是 Java 1.7.x或更高版本。接下來的指南假定是類Unix環境,Windows用戶請參考 Flink on Windows。
你可以執行下面的命令來查看是否已經正確安裝了Java了。
java -version |
這條命令會輸出類似於下面的信息:
java version "1.8.0_51" Java(TM) SE Runtime Environment (build 1.8.0_51-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode) |
配置
對於本地模式,Flink是可以開箱即用的,你不用去更改任何的默認配置。
開箱即用的配置會使用默認的Java環境。如果你想更改Java的運行環境,你可以手動地設置環境變量JAVA_HOME或者conf/flink-conf.yaml中的配置項env.java.home。你可以查閱配置頁面了解更多關於Flink的配置。
啟動Flink
你現在就可以開始運行Flink了。解壓已經下載的壓縮包,然後進入新創建的flink目錄。在那裏,你就可以本地模式運行Flink了:
$ tar xzf flink-*.tgz $ cd flink-* $ bin/start-local.sh Starting job manager |
你可以通過觀察logs目錄下的日誌文件來檢查系統是否正在運行了:
$ tail log/flink-*-jobmanager-*.log INFO ... - Initializing memory manager with 409 megabytes of memory INFO ... - Trying to load org.apache.flinknephele.jobmanager.scheduler.local.LocalScheduler as scheduler INFO ... - Setting up web info server, using web-root directory ... INFO ... - Web info server will display information about nephele job-manager on localhost, port 8081. INFO ... - Starting web info server for JobManager on port 8081 |
JobManager 同時會在8081端口上啟動一個web前端,你可以通過 http://localhost:8081 來訪問。
在windows上運行
Flink on Windows
如果你想要在 Windows 上運行 Flink,你需要如上文所述地下載、解壓、配置 Flink 壓縮包。之後,你可以使用使用 Windows 批處理文件(.bat文件)或者使用 Cygwin 運行 Flink 的 JobMnager。
使用 Windows 批處理文件啟動
使用 Windows 批處理文件本地模式啟動Flink,首先打開命令行窗口,進入 Flink 的 bin/ 目錄,然後運行 start-local.bat 。
註意:Java運行環境必須已經加到了 Windows 的%PATH%環境變量中。按照本指南添加 Java 到%PATH%環境變量中。
$ cd flink $ cd bin $ start-local.bat Starting Flink job manager. Webinterface by default on http://localhost:8081/. Do not close this batch window. Stop job manager by pressing Ctrl+C. |
之後,你需要打開新的命令行窗口,並運行flink.bat。
使用 Cygwin 和 Unix 腳本啟動
使用 Cygwin 你需要打開 Cygwin 的命令行,進入 Flink 目錄,然後運行start-local.sh腳本:
$ cd flink $ bin/start-local.sh Starting Nephele job manager |
從 Git 安裝 Flink
如果你是從 git 安裝的 Flink,而且使用的 Windows git shell,Cygwin會產生一個類似於下面的錯誤:
c:/flink/bin/start-local.sh: line 30: $‘\r‘: command not found |
這個錯誤的產生是因為 git 運行在 Windows 上時,會自動地將 UNIX 換行轉換成 Windows 換行。問題是,Cygwin 只認 Unix 換行。解決方案是調整 Cygwin 配置來正確處理換行。步驟如下:
1. 打開 Cygwin 命令行
2. 確定 home 目錄,通過輸入
3. cd ;pwd
它會返回 Cygwin 根目錄下的一個路徑。
在home目錄下,使用 NotePad, WordPad 或者其他編輯器打開.bash_profile文件,然後添加如下內容到文件末尾:(如果文件不存在,你需要創建它)
1. Export SHELLOPTS
2. Set -o igncr
保存文件,然後打開一個新的bash窗口。
本文出自 “李世龍” 博客,謝絕轉載!
Flink 環境部署