
計算機中的編碼問題
計算機中的編碼問題
因為計算機只能處理數字,如果要處理文本,就必須先把文本轉換為數字才能處理。最早的計算機在設計時采用8個比特(bit)作為一個字節(byte),所以,一個字節能表示的最大的整數就是255(二進制11111111=十進制255),如果要表示更大的整數,就必須用更多的字節。比如兩個字節可以表示的最大整數是65535,4個字節可以表示的最大整數是4294967295。
一、目前常用的編碼
ASCII編碼:由於計算機是美國人發明的,因此,最早只有127個字母被編碼到計算機裏,也就是大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A的編碼是65,小寫字母
GB系列編碼:但是要處理中文顯然一個字節是不夠的,至少需要兩個字節,而且還不能和ASCII編碼沖突,所以,中國制定了GB2312編碼,用來把中文編進去。進而全世界有上百種語言,日本把日文編到Shift_JIS裏,韓國把韓文編到Euc-kr裏,各國有各國的標準,就會不可避免地出現沖突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。GB系列編碼是我國的國標編碼,用來存儲漢字,分為GB2312,GBK,GB18030,基本都能向前兼容,其中GBK是目前最通用的。
Unicode編碼:Unicode把所有語言都統一到一套編碼裏,這樣就不會再有亂碼問題了。Unicode標準也在不斷發展,但最常用的是用兩個字節表示一個字符(如果要用到非常偏僻的字符,就需要4個字節)。現代操作系統和大多數編程語言都直接支持Unicode。不過他只規定了字符的編碼,卻沒有規定字符以何種方式存儲或者傳輸。所以UTF系列編碼規定了Unicode編碼的存儲和傳輸方式。
UTF編碼系列:目前最常用的UTF編碼分為3種,UTF-8,UTF-16和UTF-32,我們知道計算機是以8位為一個字節來存儲數據的,而UTF-16,UTF-32分別用2字節和4字節來表示一個字符,所以這裏就涉及到字節的存儲順序,是低位在前還是高位在前,這樣,BOM就產生了。
BOM是文本文件開頭的一個特殊標記,用一組特殊數字來標記文本文件的字節序。雖然UTF-8字節順序是固定的,但為了兼容UTF-16和UTF-32也規定了UTF-8的BOM,用於標記UTF-8編碼。不過UTF-8的BOM在不同平臺的規定不同,要小心使用。BOM規定如下:
UTF-8 EF BB BF
UTF-16(LE) FF FE
UTF-16(BE) FE FF
UTF-32(LE) FF FE 00 00
UTF-32(BE) 00 00 FE FF
UTF-8編碼:如果統一成Unicode編碼,亂碼問題從此消失了。但是,如果你寫的文本基本上全部是英文的話,用Unicode編碼比ASCII編碼需要多一倍的存儲空間,在存儲和傳輸上就十分不劃算。所以,本著節約的精神,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字符根據不同的數字大小編碼成1-6個字節,常用的英文字母被編碼成1個字節,漢字通常是3個字節,只有很生僻的字符才會被編碼成4-6個字節。如果你要傳輸的文本包含大量英文字符,用UTF-8編碼就能節省空間:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | X | 01001110 00101101 | 11100100 10111000 10101101 |
二、計算機系統中的編碼應用
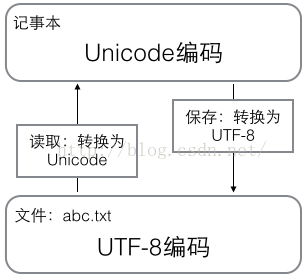
在計算機內存中,統一使用Unicode編碼,當需要保存到硬盤或者需要傳輸的時候,就轉換為UTF-8編碼;用記事本編輯的時候,從文件讀取的UTF-8字符被轉換為Unicode字符到內存裏,編輯完成後,保存的時候再把Unicode轉換為UTF-8保存到文件:
瀏覽網頁的時候,服務器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器:

所以你看到很多網頁的源碼上會有類似<meta charset="UTF-8" />的信息,表示該網頁正是用的UTF-8編碼。
三、Java中的編碼問題
直接寫一個demo來看看eclipse中java項目的編碼是怎麽樣的吧。
1、字符串轉為字節序列
1 public class EncodeDemo { 2 3 public static void main(String[] args) { 4 // TODO Auto-generated method stub 5 String s="雲開de立夏"; 6 byte[] bytes1=s.getBytes();//這是把字符串轉換成字符數組,轉換成的字節序列用的是項目默認的編碼 7 for(byte b: bytes1) 8 //toHexString這個函數是把字節(轉換成了Int)以16進制的方式顯示 9 System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是為了把前面的24個0去掉只留下後八位 10 } 11 12 }
運行結果:

分析:可以看到這個java項目的默認編碼中,漢字用2個字節表示,英文用一個字節表示。
通過查看項目的默認編碼為 GBK。
GBK。
如果不想用項目默認的編碼格式,可以用下面這種方法指定字符串轉化為想要的編碼格式:
1 byte[] bytes2=s.getBytes("utf-8");//轉換成utf-8編碼 2 for(byte b: bytes2) 3 //toHexString這個函數是把字節(轉換成了Int)以16進制的方式顯示 4 System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是為了把前面的24個0去掉只留下後八位 5 System.out.println(); 6 byte[] bytes3=s.getBytes("utf-16be");//轉換成java雙字節編碼,utf-16be編碼 7 for(byte b: bytes3) 8 //toHexString這個函數是把字節(轉換成了Int)以16進制的方式顯示 9 System.out.print(Integer.toHexString(b & 0xff)+" ");// & 0xff是為了把前面的24個0去掉只留下後八位
運行結果:

分析:兩個結果對比可以得出,
gbk編碼: 中文占用兩個字節,英文占用一個字節。
utf-8編碼:中文占用三個字節,英文占用一個字節。
utf-16be編碼:中文占用兩個字節,英文占用兩個字節。
註意:java是雙字節編碼,是utf-16be編碼。即java中的一個字符(char)占用兩個字節!
2、字節序列轉為字符串
當你的字節序列是某種編碼時,這個時候想把字節序列變成字符串,也需要用這種編碼方式,否則會出現亂碼。
1 String str1=new String(bytes1);//這時會使用項目默認的編碼來轉換,可能出現亂碼
2 System.out.println(str1);
3 String str2=new String(bytes2);
4 System.out.println(str2);
5 String str3=new String(bytes2,"utf-8");
6 System.out.println(str3);
運行結果:

四、文本文件(txt)的編碼問題
文本文件就是字節序列,可以是任意編碼的字節序列。
如果我們在中文機器上直接創建文本文件,那麽該文件只認識ANSI編碼(例如直接在電腦中右鍵創建文本文件)。
這裏要註意:只有直接創建文本文件時,該文件的編碼只認識ANSI,但是文本文件本身是可以放任意編碼的字節序列。
註意:中文系統下,ANSI編碼即是GBK編碼。
這裏舉個例子:
我們在eclipse新建一個項目,把它的默認編碼改為utf-8

那麽對於這個項目而言,它只認識utf-8的編碼文件。
接下來,我們在這個項目中新建一個文本文件utf-8.txt,並在裏面輸入內容如下:


如果直接把這個文本文件拷貝到其他項目中(默認為GBK編碼),裏面的內容將會變成亂碼!因為編碼不一樣!
但是如果是將裏面的內容復制粘貼過去,系統會自動轉化為相應的編碼,是不會出現亂碼的。

註意:如果把這個文本文件拷貝到其他地方(比如系統的桌面)上,它不會出現亂碼!!因為文本文件可以是任意的編碼序列,系統在讀取文本文件時會自動轉化為相應的編碼格式。
了解文件的編碼有什麽用呢??在Java的IO流中,我們需要對文件進行讀寫,使用字節流進行讀寫的時候,就必須根據不同的編碼方式進行讀寫。因為不同編碼方式的各個字符所占用的字節數不同,我們要按照實際情況進行操作。好了,下期預告:《Java中File類的使用》
參考博文:
http://blog.csdn.net/u012050154/article/details/50774098#t2
計算機中的編碼問題