
hadoop安裝教程
hadoop的核心
Hadoop的核心就是HDFS和MapReduce,而兩者只是理論基礎,不是具體可使用的高級應用,Hadoop旗下有很多經典子項目,比如HBase、Hive等,這些都是基於HDFS和MapReduce發展出來的。要想了解Hadoop,就必須知道HDFS和MapReduce是什麽。
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系統),它是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,適合那些有著超大數據集(large data set)的應用程序
HDFS的設計特點是:
1、大數據文件,非常適合上T級別的大文件或者一堆大數據文件的存儲,如果文件只有幾個G甚至更小就沒啥意思了。
2、文件分塊存儲,HDFS會將一個完整的大文件平均分塊存儲到不同計算器上,它的意義在於讀取文件時可以同時從多個主機取不同區塊的文件,多主機讀取比單主機讀取效率要高得多得都。
3、流式數據訪問,一次寫入多次讀寫,這種模式跟傳統文件不同,它不支持動態改變文件內容,而是要求讓文件一次寫入就不做變化,要變化也只能在文件末添加內容。
4、廉價硬件,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的計算機就可以撐起一個大數據集群。
5、硬件故障,HDFS認為所有計算機都可能會出問題,為了防止某個主機失效讀取不到該主機的塊文件,它將同一個文件塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取文件。
MapReduce
通俗說MapReduce是一套從海量·源數據提取分析元素最後返回結果集的編程模型,將文件分布式存儲到硬盤是第一步,而從海量數據中提取分析我們需要的內容就是MapReduce做的事了。
Hadoop安裝教程分布式配置_CentOS6.5/Hadoop2.6.5
1 創建hadoop用戶
su # 上述提到的以 root 用戶登錄
# useradd -m hadoop -s /bin/bash # 創建新用戶hadoop
如下圖所示,這條命令創建了可以登陸的 hadoop 用戶,並使用 /bin/bash 作為shell。
# passwd hadoop
修改用戶的密碼
# visudo
為用戶增加管理員權限
如下圖,找到 root ALL=(ALL) ALL 這行(應該在第98行,可以先按一下鍵盤上的 ESC 鍵,然後輸入 :98 (按一下冒號,接著輸入98,再按回車鍵),可以直接跳到第98行 ),然後在這行下面增加一行內容:hadoop ALL=(ALL) ALL (當中的間隔為tab),如下圖所示:
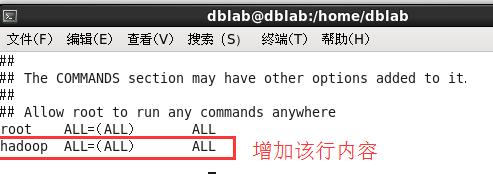
添加好內容後,先按一下鍵盤上的 ESC 鍵,然後輸入 :wq (輸入冒號還有wq,這是vi/vim編輯器的保存方法),再按回車鍵保存退出就可以了。
最後註銷當前用戶(點擊屏幕右上角的用戶名,選擇退出->註銷),在登陸界面使用剛創建的 hadoop 用戶進行登陸。(如果已經是 hadoop 用戶,且在終端中使用 su 登錄了 root 用戶,那麽需要執行 exit 退出 root 用戶狀態)
2 安裝SSH、配置SSH無密碼登陸
CentOS 默認已安裝了 SSH client、SSH server,打開終端執行如下命令進行檢驗
# rpm -qa | grep ssh
如果返回的結果如下圖所示,包含了 SSH client 跟 SSH server,則不需要再安裝

若需要安裝,則可以通過 yum 進行安裝(安裝過程中會讓你輸入 [y/N],輸入 y 即可):
$ sudo yum install openssh-clients
$ sudo yum install openssh-server
接著執行如下命令測試一下 SSH 是否可用:
$ ssh localhost
此時會有如下提示(SSH首次登陸提示),輸入 yes 。然後按提示輸入密碼 hadoop,這樣就登陸到本機了。

但這樣登陸是需要每次輸入密碼的,我們需要配置成SSH無密碼登陸比較方便。
首先輸入 exit 退出剛才的 ssh,就回到了我們原先的終端窗口,然後利用 ssh-keygen 生成密鑰,並將密鑰加入到授權中:
$ exit # 退出剛才的 ssh localhost $ cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost $ ssh-keygen -t rsa # 會有提示,都按回車就可以 $ cat id_rsa.pub >> authorized_keys # 加入授權 $ chmod 600 ./authorized_keys # 修改文件權限

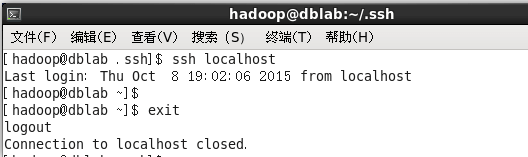
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示。
3 安裝Java環境
(1)卸載自帶OPENJDK
用 java -version 命令查看當前jdk版本信息
#java -version
用rpm -qa | grep java 命令查詢操作系統自身安裝的java
#rpm -qa | grep java
執行結果如下
python-javapackages-3.4.1-11.el7.noarch java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64 tzdata-java-2015g-1.el7.noarch javapackages-tools-3.4.1-11.el7.noarch java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64 java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
用rpm命令卸載下面這些文件(操作系統自身帶的java相關文件)
#rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64 #rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64 #rpm -e --nodeps tzdata-java-2015g-1.el7.noarch #rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64 #rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
如果卸載錯了,可使用yum install 來安裝
(2)下載解壓jdk
# wget --no-check-certificate --no-cookies --header "Cookies: oraclelicense=accept-securebackup-cookies" http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz
可以直接在終端下載也可以直接在網上下載默認的下載位置在主文件(/home/hadoop)
將"/hadoop/下載/jdk-8u141-linux-x64.tar.gz"文件拷貝到/usr/java 目錄下
[[email protected] 下載]# cp jdk-7u80-linux-x64.tar.gz /usr/java
解壓縮該壓縮文件到 /usr/java目錄
[[email protected] java]#tar -zxvf jdk-7u80-linux-x64.tar.gz
使用rm -f命令刪除該jdk壓縮文件
[[email protected] java]#rm -f jdk-7u80-linux-x64.tar.gz
(3)配置jdk環境變量
[[email protected] java]#vim /etc/profile
在最後一行加上如下值
#java environment
export JAVA_HOME=/usr/java/jdk1.7.0_80
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
註:CentOS6上面的是JAVAHOME,CentOS7是{JAVA_HOME}
source /etc/profile
#如果後卸載OPENJDK,就必須再次使用生效命令
我之前以為這樣配好就不行了後來在運行hadoop報錯找不到JAVA_HOME 還需要做一些配置
$ vim ~/.bashrc
在文件最前面添加單獨一行(註意 = 號前後不能有空格),將“JDK安裝路徑”改為上述命令得到的路徑,並保存:
export JAVA_HOME=/usr/local/java/jdk1.8.0_141
設置 HADOOP 環 境變量,執行如下命令在 ~/.bashrc 中設置:
最好在文件中配置下面的hadoop環境
# Hadoop Environment Variables export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
PATH配置hadoop環境那麽以後我們在任意目錄中都可以直接通過執行start-dfs.sh 來啟動 Hadoop 或者執行 hdfs dfs -ls input 查看 HDFS 文件了,讀者不妨現在就執行 hdfs dfs -ls input 。
著還需要讓該環境變量生效,執行如下代碼:
$ source ~/.bashrc # 使變量設置生效
設置好後我們來檢驗一下是否設置正確:
$ echo $JAVA_HOME # 檢驗變量值 $ java -version $ $JAVA_HOME/bin/java -version # 與直接執行 java -version 一樣
如果設置正確的話,$JAVA_HOME/bin/java -version 會輸出 java 的版本信息,且和 java -version 的輸出結果一樣
4 安裝 Hadoop 2.6.5
下載hadoop-2.6.5.tar.gz 解壓到
$ sudo tar -zxf ~/下載/hadoop-2.6.5.tar.gz -C /usr/local # 解壓到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-2.6.5/ ./hadoop # 將文件夾名改為hadoop
$ sudo chown -R hadoop:hadoop ./hadoop # 修改文件權限
Hadoop 解壓後即可使用。輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本信息
$ cd /usr/local/hadoop
$ ./bin/hadoop version
5 hadoop集群配置
完成上面的基礎為配置hadoop集群的基礎。準備兩臺機子Master(主節點),slave1(子節點)在兩個節點上配置hadoop用戶,java環境,ssh無密碼登錄,hadoop安裝。
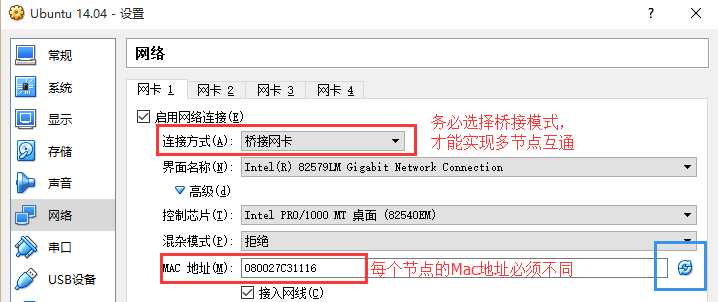
如果使用的是虛擬機安裝的系統,那麽需要更改網絡連接方式為橋接(Bridge)模式,才能實現多個節點互連,例如在 VirturalBox 中的設置如下圖。此外,如果節點的系統是在虛擬機中直接復制的,要確保各個節點的 Mac 地址不同(可以點右邊的按鈕隨機生成 MAC 地址,否則 IP 會沖突)
為了便於區分,可以修改各個節點的主機名(在終端標題、命令行中可以看到主機名,以便區分)。在 Ubuntu/CentOS 7 中,我們在 Master 節點上執行如下命令修改主機名(即改為 Master,註意是區分大小寫的)
$ sudo vim /etc/hostname
如果是用 CentOS 6.x 系統,則是修改 /etc/sysconfig/network 文件,改為 HOSTNAME=Master,如下圖所示:

然後執行如下命令修改自己所用節點的IP映射:
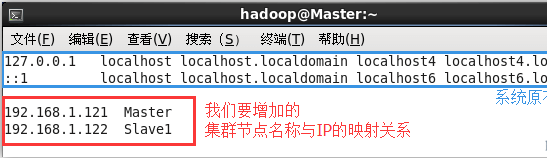
$ sudo vim /etc/hosts
我們在 /etc/hosts 中將該映射關系填寫上去即可,如下圖所示(一般該文件中只有一個 127.0.0.1,其對應名為 localhost,如果有多余的應刪除,特別是不能有 “127.0.0.1 Master” 這樣的記錄):
修改完成後需要重啟一下,重啟後在終端中才會看到機器名的變化。接下來的教程中請註意區分 Master 節點與 Slave 節點的操作。

配置好後需要在各個節點上執行如下命令,測試是否相互 ping 得通,如果 ping 不通,後面就無法順利配置成功
ping Master -c 3 # 只ping 3次,否則要按 Ctrl+c 中斷
ping Slave1 -c 3
例如我在 Master 節點上 ping Slave1,ping 通的話會顯示 time,顯示的結果如下圖所示
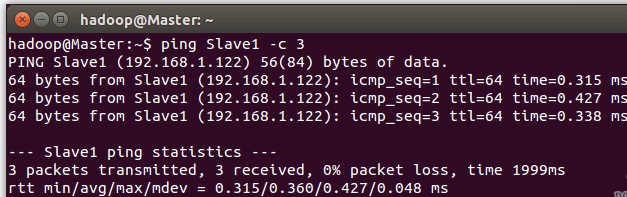
繼續下一步配置前,請先完成所有節點的網絡配置,修改過主機名的話需重啟才能生效。
SSH無密碼登陸節點
這個操作是要讓 Master 節點可以無密碼 SSH 登陸到各個 Slave 節點上。
首先生成 Master 節點的公匙,在 Master 節點的終端中執行(因為改過主機名,所以還需要刪掉原有的再重新生成一次)
$ cd ~/.ssh # 如果沒有該目錄,先執行一次ssh localhost $ rm ./id_rsa* # 刪除之前生成的公匙(如果有) $ ssh-keygen -t rsa # 一直按回車就可以
讓 Master 節點需能無密碼 SSH 本機,在 Master 節點上執行:
cat ./id_rsa.pub >> ./authorized_keys
完成後可執行 ssh Master 驗證一下(可能需要輸入 yes,成功後執行 exit 返回原來的終端)。接著在 Master 節點將上公匙傳輸到 Slave1 節點:
$ scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/
scp 是 secure copy 的簡寫,用於在 Linux 下進行遠程拷貝文件,類似於 cp 命令,不過 cp 只能在本機中拷貝。執行 scp 時會要求輸入 Slave1 上 hadoop 用戶的密碼(hadoop),輸入完成後會提示傳輸完畢,如下圖所示:

接著在 Slave1 節點上,將 ssh 公匙加入授權:
$ mkdir ~/.ssh # 如果不存在該文件夾需先創建,若已存在則忽略 $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys $ rm ~/id_rsa.pub # 用完就可以刪掉了
如果有其他 Slave 節點,也要執行將 Master 公匙傳輸到 Slave 節點、在 Slave 節點上加入授權這兩步。
這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了,可在 Master 節點上執行如下命令進行檢驗,如下圖所示:
$ ssh Slave1
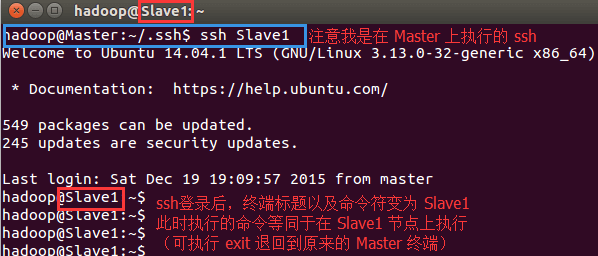
配置集群/分布式環境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5個配置文件,更多設置項可點擊查看官方說明,這裏僅設置了正常啟動所必須的設置項: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 文件 slaves,將作為 DataNode 的主機名寫入該文件,每行一個,默認為 localhost,所以在偽分布式配置時,節點即作為 NameNode 也作為 DataNode。分布式配置可以保留 localhost,也可以刪掉,讓 Master 節點僅作為 NameNode 使用。
本教程讓 Master 節點僅作為 NameNode 使用,因此將文件中原來的 localhost 刪除,只添加一行內容:Slave1。
2, 文件 core-site.xml 改為下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3, 文件 hdfs-site.xml,dfs.replication 一般設為 3,但我們只有一個 Slave 節點,所以 dfs.replication 的值還是設為 1
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4, 文件 mapred-site.xml (可能需要先重命名,默認文件名為 mapred-site.xml.template),然後配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
5, 文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好後,將 Master 上的 /usr/local/Hadoop 文件夾復制到各個節點上。因為之前有跑過偽分布式模式,建議在切換到集群模式前先刪除之前的臨時文件。在 Master 節點上執行:
$ cd /usr/local $ sudo rm -r ./hadoop/tmp # 刪除 Hadoop 臨時文件 $ sudo rm -r ./hadoop/logs/* # 刪除日誌文件 $ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再復制 $ cd ~ $ scp ./hadoop.master.tar.gz Slave1:/home/hadoop
在 Slave1 節點上執行:
$ sudo rm -r /usr/local/hadoop # 刪掉舊的(如果存在) $ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local $ sudo chown -R hadop /usr/local/hadoop
同樣,如果有其他 Slave 節點,也要執行將 hadoop.master.tar.gz 傳輸到 Slave 節點、在 Slave 節點解壓文件的操作。
首次啟動需要先在 Master 節點執行 NameNode 的格式化:
$ hdfs namenode -format # 首次運行需要執行初始化,之後不需要
hadoop安裝教程