
Hadoop完全分散式安裝教程
最近開始學習大資料課程,便開始自己安裝搭建完全分散式,下面是自己一步一步的安裝方式,期間會遇到各種問題,但還是自己查詢資料解決了:
1.在安裝hadoop2.0之前,需要準備好以下軟體(如下圖1)
圖1:
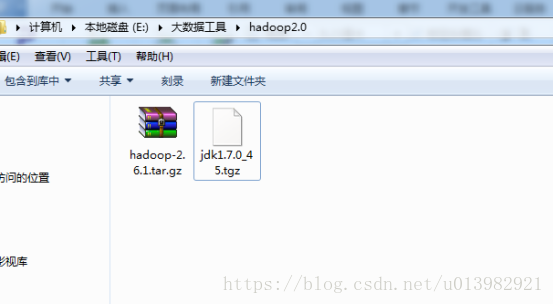
然後將這兩個軟體共享到centos上(如下圖2,圖3所示)
在vm這上面有個虛擬機器,點選虛擬機器後有個硬體和選項,點選項,下面有個共享資料夾
圖2:
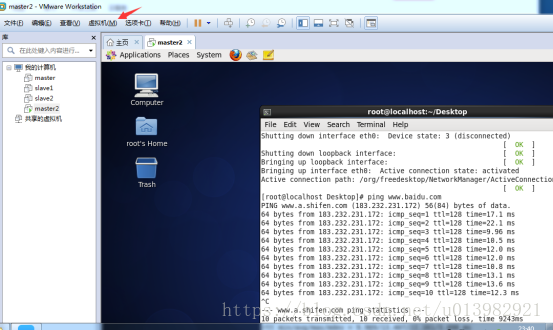
圖3:
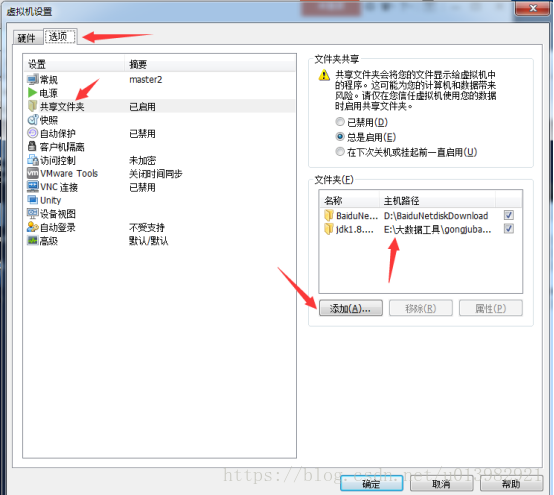
然後為了有個叢集的概念,我們把一臺linux機器複製成有三份!如下圖4所示:
注:在複製前,必須要把linux的機器要在關機或者掛起狀態,否則資料可能會丟失。
圖4:
然後開啟這三個虛擬映象並且啟動三個映象(如下圖5所示)
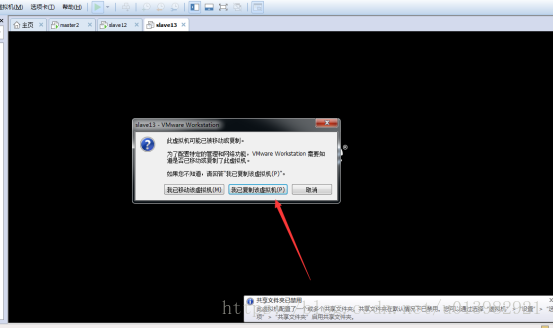
如果出現說:此虛擬機器可能已被移動或複製,那你點選:我已複製該虛擬機器
圖5:
然後命令列輸入:su //進入管理員模式
然後命令列再輸入:cd /etc/sysconfig/network-scripts/ifcfg-eth0
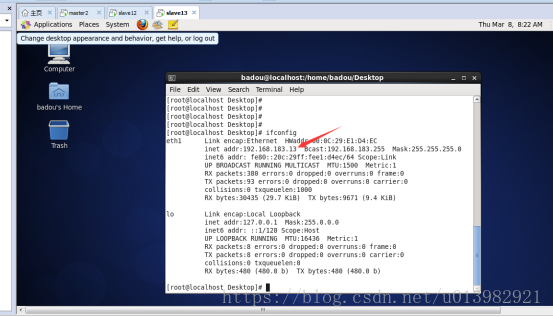
然後將三個虛擬機器的其中兩個虛擬機器的ip更改,因為三個虛擬機器的ip不能都一樣。
如下圖5,6,7,8的圖:
master圖6:
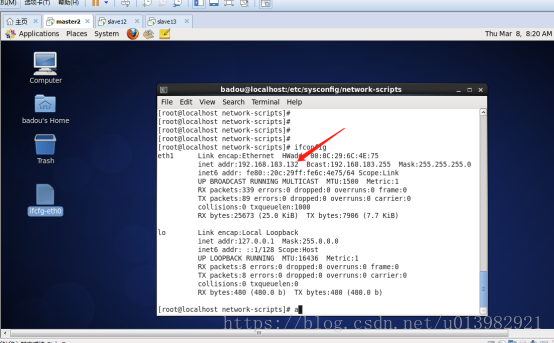
Slave1圖7:

Slave2圖8:
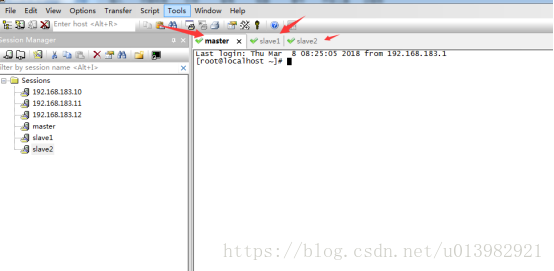
然後開啟secureCRT遠端控制軟體連線三臺虛擬機器(如下圖8)
圖9:
1.我們開始配置本地網路配置(修改hosts檔案)
命令列輸入:vim /etc/hosts

然後在hosts這個檔案裡面把主節點的ip地址寫入進去
192.168.183.10 master
192.168.183.11 slave1
192.168.183.12 slave2
然後儲存退出
但是host還沒有生效,需要生效
在命令列輸入:hostname master
然後再輸入:hostname 檢視
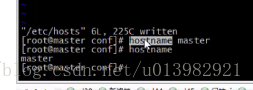
但是這個生效只是臨時生效,我們需要改為永久生效:
在命令列輸入:vim /etc/sysconfig/network
然後原先network裡面的是:HOSTNAME=localhost
我們改為:HOSTNAME=master //其他節點也是一樣這麼操作,這裡就不演示了
建立每臺機器的互信關係(這樣方便我們日後一臺機器對另外一臺機器的操作)
重點:是每個機器都要輸入:ssh-keygen
在命令列輸入:ssh-keygen 然後回車然後回車,回車(回三次車)。(如下圖
然後再輸入:ssh-keygen 然後有個選項讓你選擇yes/no的,你選擇yes,因為直到有個yes/no的選項出現你才能正式的互信。
圖10:

然後進入隱藏目錄
在命令列輸入:cd ~/.ssh/ 然後ls(如下圖11)
圖11:
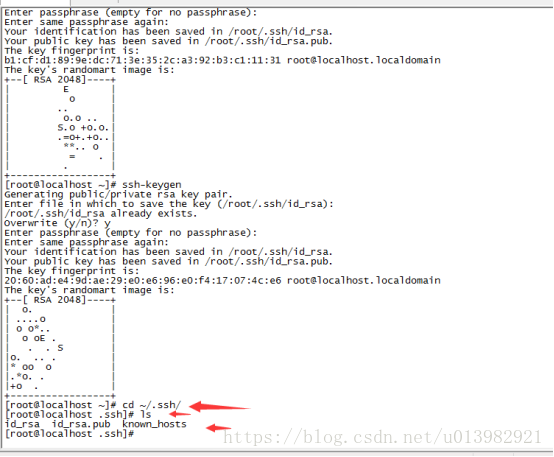
Id_rsa.pub是共鑰檔案,id_rsa是金鑰檔案
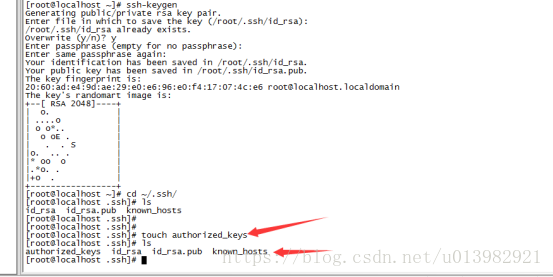
我們要對id_rsa.pub這個公鑰檔案的內容拷貝給authorized_keys這個檔案(在此說明:如果沒有authorized_keys這個檔案,請自己建立!!)
建立檔案的命令:touch authorized_keys (如下圖12所示)
圖12:
我們看一下id_rsa.pub這個公鑰檔案的內容
輸入命令列:cat id_rsa.pub 看看這公鑰
然後把slave1的公鑰複製到主機節點master的authorized_keys上
在master命令列輸入:vim authorized_keys
然後接下來把然後把slave1的公鑰複製到authorized_keys這裡(如下圖13,14,15)
圖13:
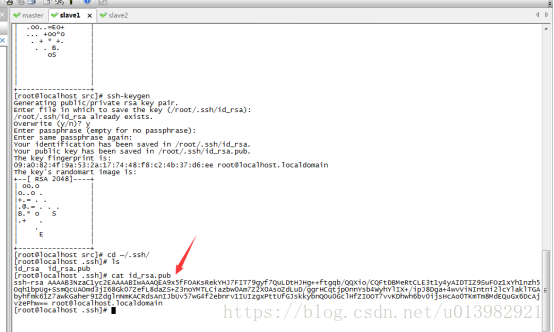
圖14:
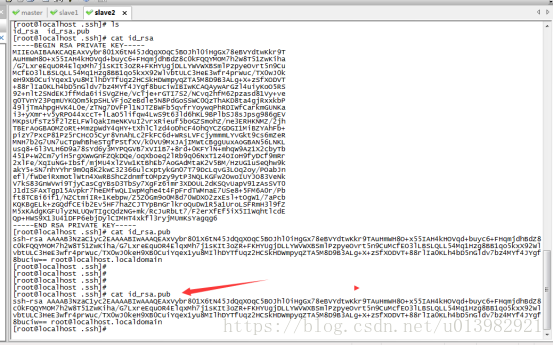
圖15:把三個機器的公鑰密碼全部放入master的authorized_keys檔案中
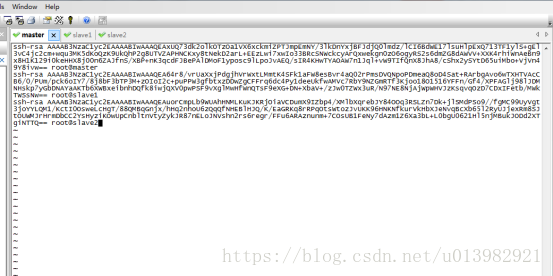
然後下一步操作就是把主節點上的authorized_keys分別複製給slave1和slave2這兩個節點上 (這是我的ip,你們要複製下面的命令列的時候請先把自個的機器ip修改上去)
命令列輸入:scp -rp authorized_keys 192.168.183.20:~/.ssh/
命令列輸入:scp -rp authorized_keys 192.168.183.13:~/.ssh/ (如下圖16)
圖16:

然後分別給slave1和slave2檢查一下是否有主節點傳過來的公鑰檔案
在slave1和slave2的命令列上分別輸入:cat authorized_keys
然後我們就可以給三臺機器互相登入而且不需要密碼了
那麼我們試一下:在主節點上命令列上輸入:ssh 192.168.183.20 如果要退出的話就是輸入:exit
然後我們在主機節點上登入子節點:ssh 192.168.183.13 如果要退出的話就是輸入:exit
然後在master裡面輸入:cd /mnt/hdfs //檢視在linux下共享的檔案(如下圖17)
圖17:
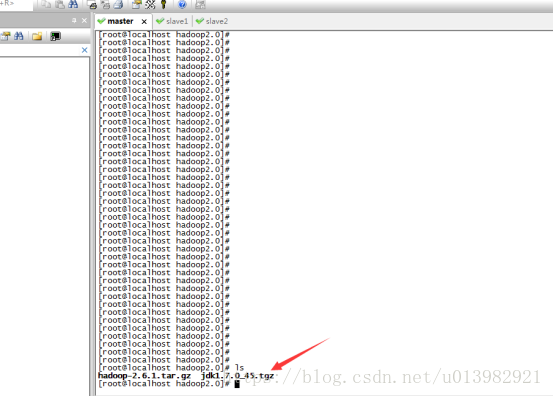
看到了把?你共享的檔案就已經在linux上有了。
然後我們把jdk和hadoop2.0工具包放入linux下的/usr/local/src/下(如下圖18所示)
命令列輸入:cp hadoop-2.6.1.tar.gz /usr/local/src/
命令列輸入:cp jdk1.7.0_45.tgz /usr/local/src/
然後去/usr/local/src/下去檢視有沒有拷貝過來的檔案
圖18:

然後解壓hadoop2.0以及jdk7的檔案(如下圖19所示)
命令列輸入:tar xvzf hadoop-2.6.1.tar.gz
命令列輸入:tar xvzf jdk1.7.0_45.tgz
圖19:
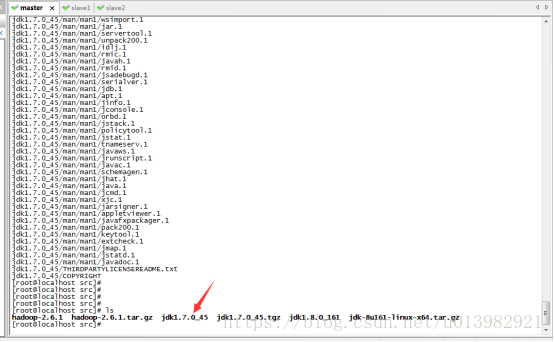
然後進入jdk,命令列輸入:cd jdk1.7.0_45/
然後檢視當前的一個目錄路徑,命令列輸入:pwd
然後將改路徑寫入配置檔案當中,命令列輸入:vim ~/.bashrc (如下圖20所示)
圖20:

複製我這個配置命令: export JAVA_HOME=/usr/local/src/jdk1.7.0_45 (如下圖21)
然後再配置CLASSPATH,複製配置命令:export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
然後再配置path,複製配置命令:export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
圖21:
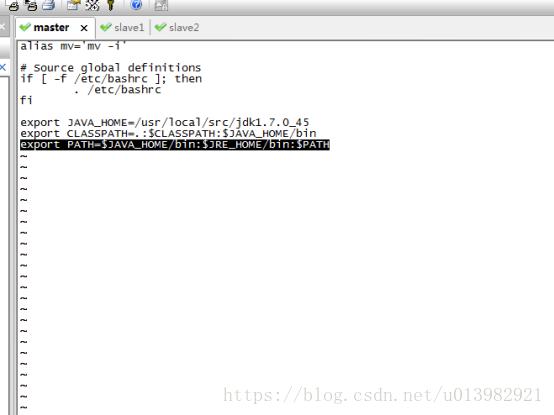
然後退出該修改介面(退出介面請先按Esc鍵,然後點Shift鍵加分號;鍵然後輸入wq然後再按Enter鍵退出)
然後在命令列輸入: source ~/.bashrc重置一下
然後我們直接執行java,在命令列直接輸入:java 然後這個java已經被系統自動識別了,然後我們看看java這個位置在哪裡,命令列輸入: which java(如下圖22所示)
圖22:
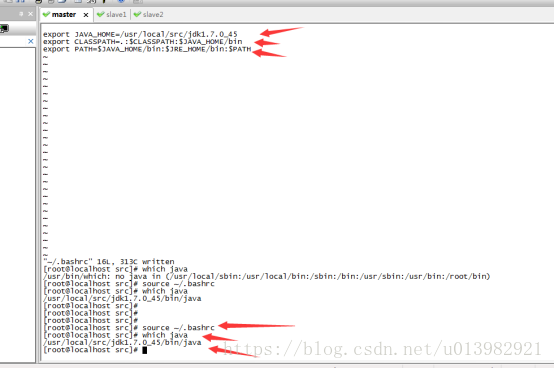
2.那麼接下來我們也要把剩下兩個節點也要安裝java環境
在主節點輸入:cd /usr/local/src/
再輸入:ls
然後將java包複製一份到slave1和slave2這兩個節點上去
在主節點輸入:scp -rp jdk1.7.0_45 slave1:/usr/local/src/
在主節點輸入:scp -rp jdk1.7.0_45 slave2:/usr/local/src/
然後讓你輸入yes/no你輸入yes,然後讓你輸入密碼,你輸入你建立這臺機器的密碼,然後即可完成遠端複製!!(如下圖23所示)
圖23:
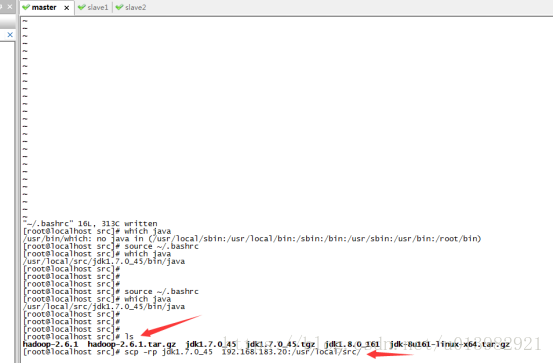
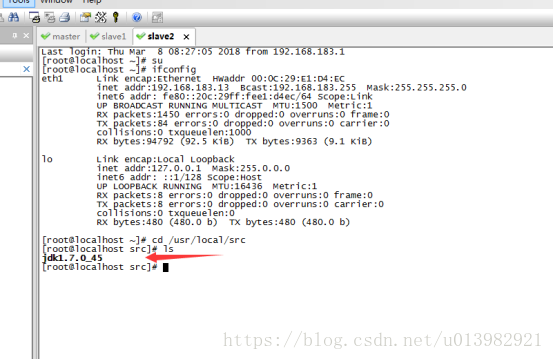
然後我們再分別切到slave1和slave2這兩個節點檢視是否將jdk檔案傳送了過來
在slave1機器上輸入:cd /usr/local/src/
然後再輸入:ls 進行檢視是否有jdk檔案(如下圖24,25)
圖24:
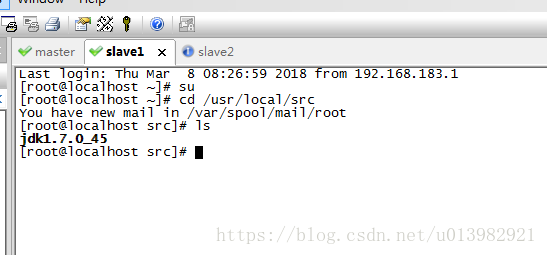
圖25:
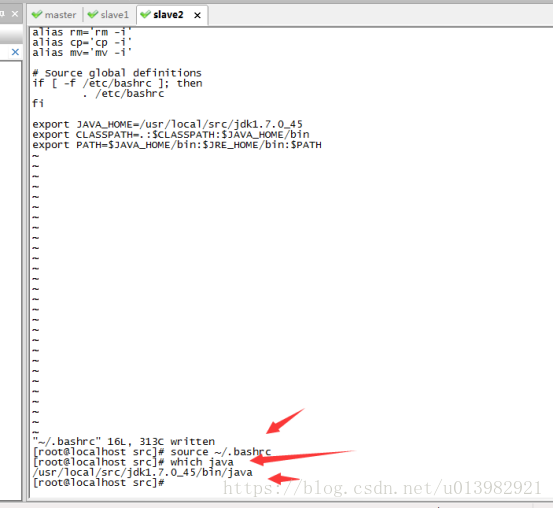
然後再分別給slave1和slave2配置環境變數。操作跟上面給主節點master配置環境變數一樣,輸入:vim ~/.bashrc 把export JAVA_HOME=/usr/local/src/jdk1.7.0_45和export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib和export PATH=$PATH:$JAVA_HOME/bin
寫在bashrc下
然後退出該修改介面(退出介面請先按Esc鍵,然後點Shift鍵加分號鍵然後輸入wq然後再按Enter鍵退出)
然後在命令列輸入: source ~/.bashrc重置一下
然後我們直接執行java,在命令列直接輸入:java 然後這個java已經被系統自動識別了
然後我們看看java這個位置在哪裡,命令列輸入: which java(如下圖26,27所示)
圖26:
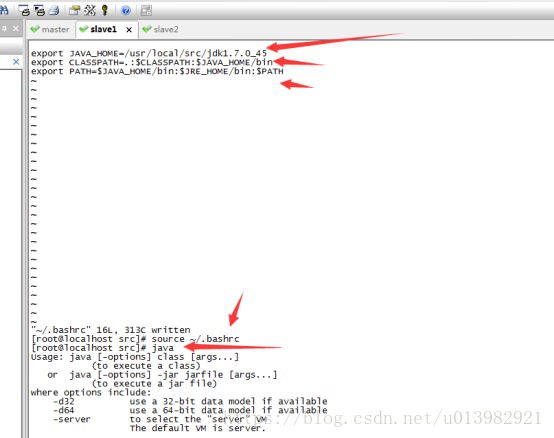
圖27:
然後我們開始準備搭建hadoop2.0叢集,在此之前需要把ssh配置好(如下操作與圖17所示)
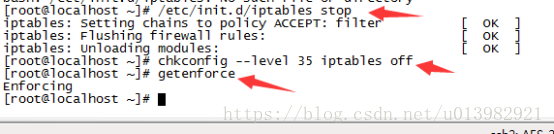
在此之前我們需要先把防火牆關閉了,以免防火牆的啟動會導致我們叢集啟動失敗
閉防火牆(在三臺機器上或者更多的機器上執行一下命令)
在命令列輸入:/etc/init.d/iptables stop (如下圖28所示)
然後檢查一下是否關閉成功:在每臺機命令列輸入:chkconfig --level 35 iptables off
然後再從命令列輸入: getenforce 檢視是否關閉了 (在每臺機器都輸入此命令)
圖28:
然後我們開啟hadoop2.0安裝包(如下圖29所示)
圖29:

然後在 hadoop-2.6.1這個目錄下建立一個tmp目錄,用來存放之後的一些臨時檔案
命令列輸入:mkdir tmp
然後進入hadoop-2.6.1的etc檔案裡的hadoop檔案 (如下圖30)
圖30:
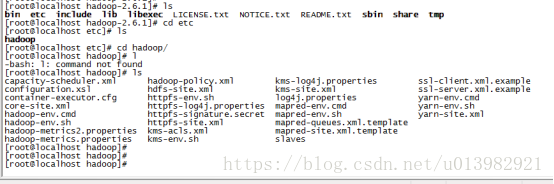
然後修改hadoop資料夾裡面的hadoop-env.sh這個檔案
命令列輸入:vim hadoop-env.sh
在hadoop-env.sh這個檔案裡面配置jdk路徑(如下圖31所示)
圖31:
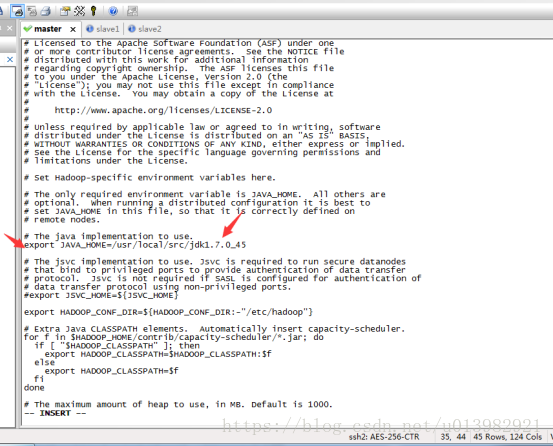
第二步修改yarn-env.sh檔案
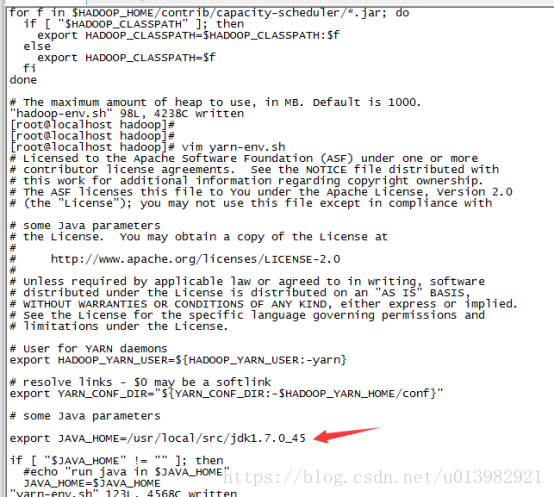
命令列輸入:vim yarn-env.sh 然後在這個檔案找到相應被註釋的export JAVA_HOME= ,將它取消註釋並把jdk路徑繼續填充上去(如下圖32所示)
圖32:
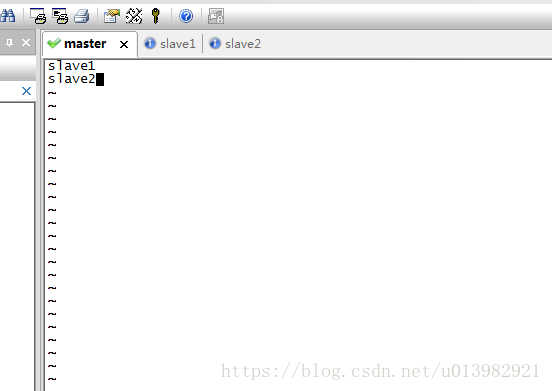
然後繼續修改,修改一個slaves檔案(如下圖33所示)
修改檔案:vim slaves
在slaves裡面填充slave1 slave2
圖33:
然後修改core-site.xml這個檔案
在configuration裡面新增資料(如下圖34所示)
圖34:
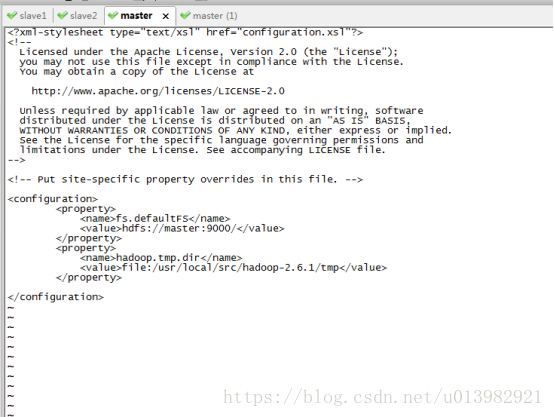
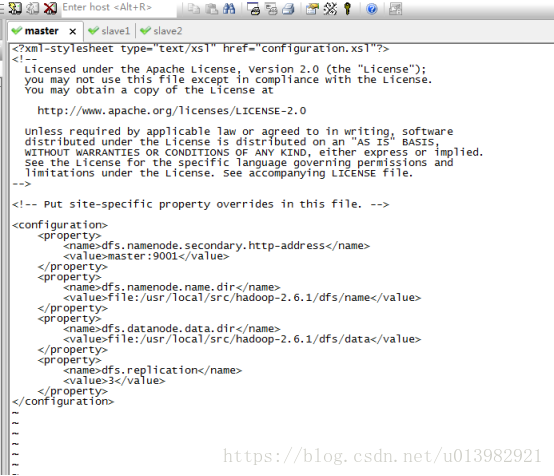
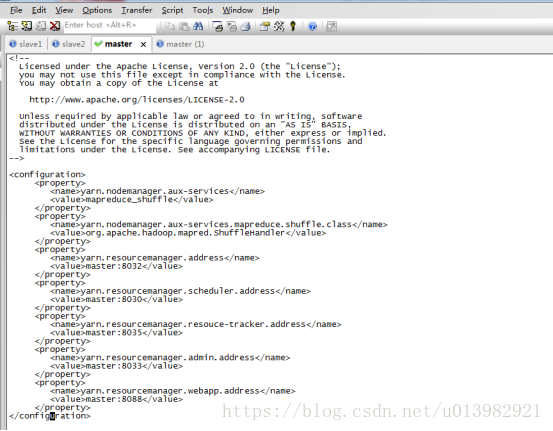
然後再修改hdfs-site.xml這個檔案(如下圖35,圖36所示)
首先先在hadoop-2.6.1目錄下建立dfs檔案,然後在dfs檔案裡面再建立name和data這兩個檔案
新增內容:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
圖35:
圖36:
然後在hadoop根目錄下有一個檔案mapred-site.xml.template模版,你需要將其拷貝一份並且改名為mapred-site.xml。(如下圖37,圖38所示)
命令列輸入:cp mapred-site.xml.template mapred-site.xml
然後修改mapred-site.xml這個檔案:vim mapred-site.xml
圖37:
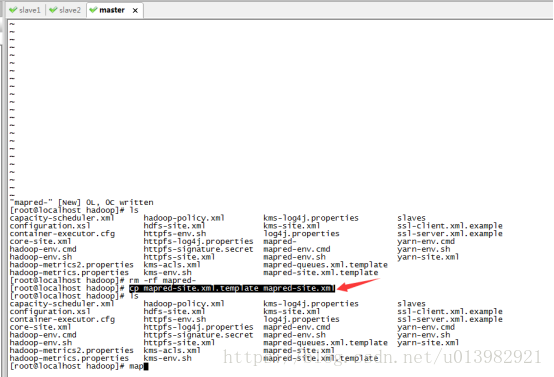
圖38:
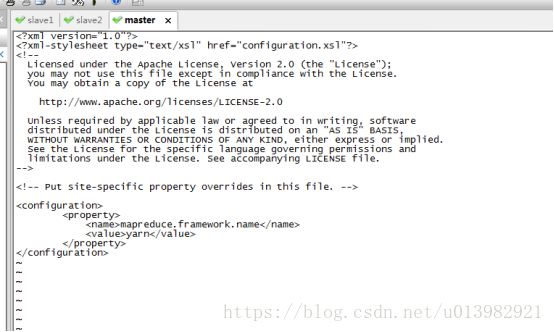
然後再修改yarn-site.xml這個檔案
命令列輸入:vim yarn-site.xml 新增內容(如下圖39)
圖39:
然後接下來把這個配置好的hadoop2.0安裝檔案分發到各個子節點上(如下圖40所示)
分發完以後在子節點上的/usr/lcoal/src目錄下檢視有沒有hadoop2.0檔案
圖40:

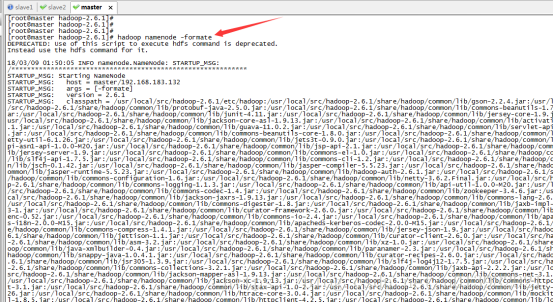
然後現在所有配置配置完畢,我們來準備啟動:(如下圖41所示)
在啟動之前必須先格式化hadoop,必須要先hadoop下的bin目錄下進行格式化
命令列輸入:hadoop namenode -formate (如下圖41所示)
圖41:
在hadoop-2.6.1的根目錄下啟動: (如下圖42所示)
命令列輸入:./sbin/start-all.sh
主節點成功啟動圖42:
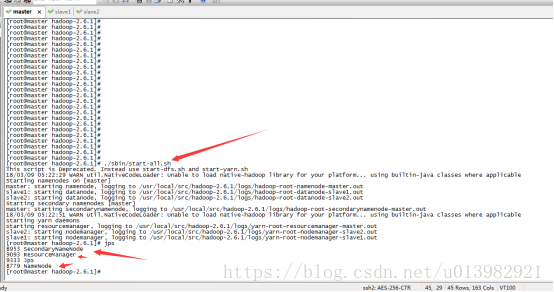
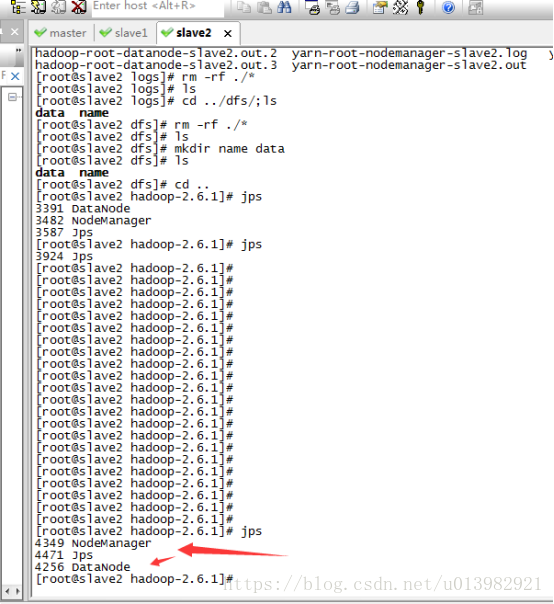
子節點成功啟動圖43:
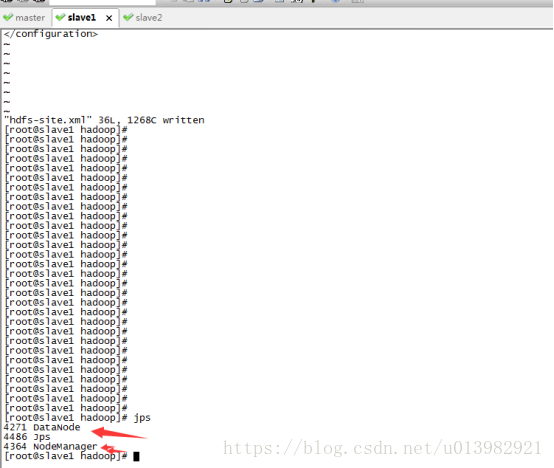
子節點成功啟動44:
恭喜,搭建完成!!
相關推薦
Hadoop完全分散式安裝教程
最近開始學習大資料課程,便開始自己安裝搭建完全分散式,下面是自己一步一步的安裝方式,期間會遇到各種問題,但還是自己查詢資料解決了:1.在安裝hadoop2.0之前,需要準備好以下軟體(如下圖1)圖1: 然後將這兩個軟體共享到centos上(如下圖2,圖3所示)在vm這上面有個
Hadoop完全分散式安裝Hive
編譯安裝 Hive 如果需要直接安裝 Hive,可以跳過編譯步驟,從 Hive 的官網下載編譯好的安裝包,下載地址為http://hive.apache.org/downloads.html。 Hive的環境配置需要MySQL的支援,所以首先需要安裝MySQL,
Hadoop完全分散式安裝zookeeper
D.1安裝 ZooKeeper D.1.1 下載 ZooKeeper ZooKeeper 是 Apache 基金會的一個開源、分散式應用程式協調服務,是 Google 的 Chubby一個開源的實現。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括配置維護、域名服務、分散式同步、
Hadoop完全分散式安裝2
hadoop簡介: 1.獨立模式(standalone|local)單機模式;所有的產品都安裝在一臺機器上且本地磁碟和副本可以在接下來的xml檔案中 nothing! &
hadoop 完全分散式安裝
一個完全的hadoop分散式安裝至少需要3個zookeeper,3個journalnode,3個datanode,2個namenode組成。 也就是說需要11個節點,但是我雲主機有限,只有3個,所以把很多節點搭在了同一個伺服器上。 步驟: 1.關閉防火牆 service
【hadoop】hadoop完全分散式叢集安裝
文章目錄 前言 裝備 Core 總結 前言 後面準備更新hdfs操作(shell命令版本),hbase,hive的操作。 所以這裡先更新一下hadoop叢集安裝。 裝備 1.hadoop-2.6.5.tar.gz
(超詳細)從零開始安裝與配置hadoop完全分散式環境
強調!!! 使用者名稱稱要相同,否則可能出現稀奇古怪的錯誤!!!(我就因為這個問題,在後面快裝完的時候不得不從頭再來) 原因:Hadoop要求所有機器上Hadoop的部署目錄結構要求相同(因為在啟動時按與主節點相同的目錄啟動其它任務節點),並且都有一
Hadoop+HBase完全分散式安裝
記錄下完全分散式HBase資料庫安裝步驟 準備3臺機器:10.202.7.191 / 10.202.7.139 / 10.202.9.89 所需準備的Jar包: 1.JDK安裝 一般Linux的發行版本有預裝openjdk,這裡安裝標準sun公司的jdk。 1.1檢視當前機器安裝的jdk rp
基於hadoop-2.6.0的hbase完全分散式安裝
1.安裝環境:有一個完全分散式的hadoop-2.6.0。 2.安裝準備:需要在網上下一個hbase的壓縮包,我這兒用的是hbase-1.0.3-bin.tar.gz,下載地址here 3.解壓下載好的hbase到一個目錄下,並更改使用者及使用者組(我這兒用
Hadoop完全分散式用MapReduce實現自定義排序、分割槽和分組
經過前面一段時間的學習,簡單的單詞統計已經不能實現更多的需求,就連自帶的一些函式方法等也是跟不上節奏了;加上前面一篇MapReduce的底層執行步驟的瞭解,今天學習自定義的排序、分組、分割槽相對也特別容易。 認為不好理解,先參考一下前面的一篇:https://bl
實用貼:hadoop系統下載安裝教程
實用貼:hadoop系統下載安裝教程 在前幾篇的文章中分別就虛擬系統安裝、LINUX系統安裝以及hadoop執行伺服器的設定等內容寫了詳細的操作教程,本篇分享的是hadoop的下載安裝步驟。 在此之前有必要做一個簡單的說明:分享的所有內容是以個人的操作經驗為基礎,有的人看完可能會說跟他做過的
ubantu 16.4 Hadoop 完全分散式搭建
一個虛擬機器 1.以 NAT網絡卡模式 裝載虛擬機器 2.最好將幾個用到的虛擬機器修改主機名,靜態IP /etc/network/interface,這裡 是 s101 s102 s103 三
Hadoop完全分散式配置問題
關於搭建Hadoop完全分散式時配置的問題 配置hadoop的配置檔案core-site.xml, hdfs-site.xml, mapred-site.xml,yarn-site.xml,slaves(workers)(都在Hadoop安裝目錄/etc/hadoop資料夾下) 1、co
hadoop完全分散式遇到的問題總結
第一步、確保你的jdk、hadoop、SSH免密已經配置好了,開啟2臺以上的虛擬機器,並且能正常上網(後面放大招啦) 第二部、配置/etc/hosts檔案(如下格式) 192.168.244.128 hadoop02 192.168.244.129 hadoop0
安裝HBase--單節點、偽分散式、完全分散式安裝
1.下載HBase 連結:http://mirrors.cnnic.cn/apache/hbase/ 選擇 stable 目錄,下載 bin 檔案: 在Linux上解壓,部落格中解壓在/home/hadoop 目錄下: 進入解壓目錄: 2.修改配置 修改JD
VMware上部署Hadoop完全分散式&spark
相信大多數初學者和我一樣,對配置環境頭疼的一批; 我在這裡簡單介紹一下hadoop基於虛擬機器的完全分散式部署; 1 首先說一下我的電腦配置吧: win10作業系統;8g記憶體;i5六代處理器;配置越高越好吧(要不然容易卡頓); Ubuntu 16.04(這個映象大家可以去網上下
史上最簡單詳細的Hadoop完全分散式叢集搭建
一.安裝虛擬機器環境 Vmware12中文官方版 連結:https://pan.baidu.com/s/1IGKVfaOtcFMFXNLHUQp41w 提取碼:6rep 啟用祕鑰:MA491-6NL5Q-AZAM0-ZH0N2-AAJ5A 這個安裝就十分的簡單了,只需要不斷點選下
office怎麼解除安裝乾淨,Office for Mac完全解除安裝教程
有小夥伴表示office安裝出錯?那是因為你原先安裝Office沒有解除安裝乾淨,想要完全解除安裝掉Office 2016 for Mac是一件非常複雜的事情,需要刪除安裝的應用程式,支援的檔案和鑰匙串條目等等檔案,今天小編就為大家帶來了非常詳細的Office 2016 for Mac完全解除安裝詳
Hadoop完全分散式搭建步驟
請在搭建偽分散式的基礎上搭建完全分散式 1、克隆兩臺虛擬機器(點選藍色超連結有如何克隆虛擬機器)。 2、克隆完成之後首先在三臺機器上都分別輸入 $ ifconfig 檢視是否有eth0 如下:是正確的。 【 eth0 &nbs
ZooKeeper完全分散式安裝與配置
Apache ZooKeeper是一個為分散式應用所設計開源協調服務,其設計目是為了減輕分散式應用程式所承擔的協調任務。可以為使用者提供同步、配置管理、分組和命名服務。 1.環境說明 在三臺裝有centos6.5(64位)伺服器上安裝ZooKeeper,官網建議至少3個節點,本