
python基礎之IO模型
IO模型分類
五種IO Model
blocking IO 阻塞IO
nonblocking IO 非阻塞IO
IO multiplexing IO多路復用
signal driven IO 信號驅動IO
asynchronous IO 異步IO
signal driven IO(信號驅動IO)在實際中並不常用,所以只剩下四種IO Model。
網絡IO的兩個過程
對於一個network IO ,會涉及到兩個系統對象,一個是調用這個IO的process (or thread),另一個就是系統內核(kernel)。當一個read操作發生時,它會經歷兩個階段:
- 等待數據準備 (Waiting for the data to be ready):等待系統接收數據
- 將數據從內核拷貝到進程中 (Copying the data from the kernel to the process):進程從系統緩存中拿到數據
同步IO:在這兩個過程中有任意階段出現阻塞狀態。
阻塞IO、非阻塞IO、IO多路復用都是同步IO
異步IO:全程無阻塞的IO
異步IO屬於異步IO(真的沒毛病)
阻塞IO(Blocking IO)
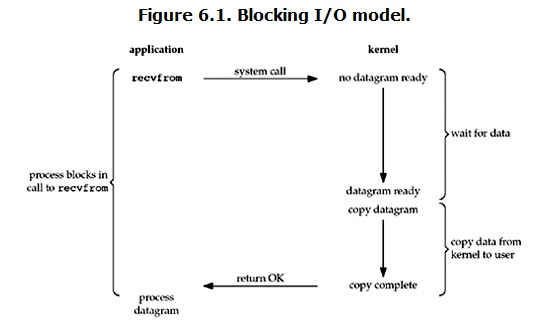
UDP包:當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據。對於network io來說,很多時候數據在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的數據到來。而在用戶進程這邊,整個進程會被阻塞。當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然後kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
blocking IO的特點就是在IO執行的兩個階段都被block了。
示例:
1 #服務端
2 import socket
3 sock=socket.socket() #默認是TCP
4 sock.bind(("127.0.0.1",8088))
5
6 sock.listen(5)
7 while True:
8 conn,addr=sock.accept() #默認是就是阻塞的方式,監聽等待客戶端連接(階段一):等待中的阻塞
9 #客戶端連接後接收數據(階段二):socket對象和客戶端地址,雖然接收數據的過程很快但是實際上也是阻塞
10 while True:
11 data=conn.recv(1024) #也是兩個階段的阻塞
12 print(data.decode(‘utf8‘))
13 if data.decode(‘utf8‘) ==‘q‘:
14 break
15 respnse=input(‘>>>>‘)
16 conn.send(respnse.encode(‘utf8‘))
17
18
19 #客戶端
20 import socket
21 sock=socket.socket()
22 sock.connect(("127.0.0.1",8088))
23
24 while True:
25 data=input(‘>>>‘).strip()
26 sock.send(data.encode(‘utf8‘))
27 s_data = sock.recv(1024) #兩個階段的阻塞
28 print(s_data.decode(‘utf8‘))
非阻塞IO(Non-blocking IO)
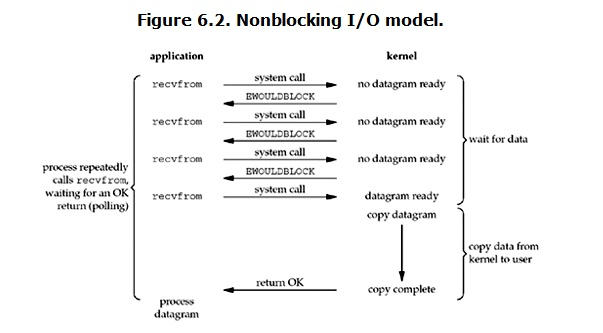
當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那麽它並不會block用戶進程,而是立刻返回一個error。所以用戶進程不需要等待,而是馬上就得到了一個結果,用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,於是它可以再次發送read操作。一旦kernel中的數據準備好了,並且又再次收到了用戶進程的system call,那麽它馬上就將數據拷貝到了用戶內存,然後返回。這個過程中,用戶進程是需要不斷的主動詢問kernel數據好了沒有。
非阻塞實際上是將大的整片時間的阻塞分成N多的小的阻塞,每次recvform系統調用之間,可以幹點別的事情,然後再發起recvform系統調用,重復的過程通常被稱之為輪詢。輪詢檢查內核數據,直到數據準備好,再拷貝數據到進程,進行數據處理。需要註意,拷貝數據整個過程,進程仍然是屬於阻塞的狀態。
優點:能夠在等待任務完成的時間裏幹其他活了(包括提交其他任務,也就是 “後臺” 可以有多個任務在同時執行)。
缺點:任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體數據吞吐量的降低。
1 #服務端
2
3 import socket
4 import time
5 sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #默認是TCP
6 sock.bind(("127.0.0.1",8088))
7 sock.listen(5)
8 sock.setblocking(False)
9
10 while True:
11 try:
12 print(‘server waiting‘)
13 conn, addr = sock.accept() # 默認是個阻塞的方式,等待客戶端連接
14 while True:
15 data = conn.recv(1024) #這邊也是阻塞的IO
16 print(data.decode(‘utf8‘))
17 if data.decode(‘utf8‘) == ‘q‘:
18 break
19 respnse = input(‘>>>>‘)
20 conn.send(respnse.encode(‘utf8‘))
21 except Exception as e:
22 print (e)
23 time.sleep(4)
24
25 #客戶端
26 import socket
27 sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #默認是TCP
28
29 while True:
30 sock.connect(("127.0.0.1", 8088)) #因為服務端recv也是非阻塞,所以要不斷重新連接
31 data=input(‘>>>‘).strip()
32 sock.send(data.encode(‘utf8‘))
33 s_data = sock.recv(1024)
34 print(s_data.decode(‘utf8‘))
IO多路復用(IO multiplexing)
IO多路復用,也叫做event driven IO,實現方式:select,poll或epoll
IO多路復用的好處就在於單個process就可以同時處理多個網絡連接的IO
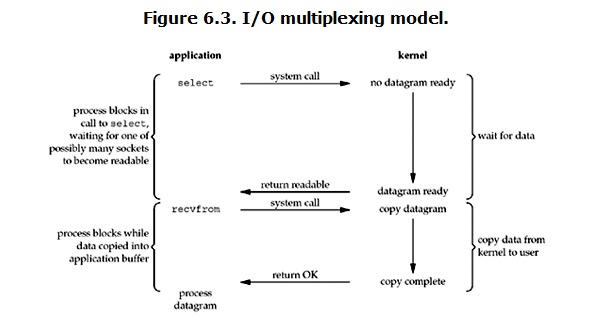
用戶進程調用了select,那麽整個進程會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。這個過程中有兩次system call(系統調用) select阻塞時候 和 recvfrom阻塞時候。用多路復用的的優勢在於它可以同時處理大批量的connection,不適用單個或少量,少量還不如multi-threading + blocking IO。
select示例:
1 #服務端
2 import socket
3 import select
4 sock=socket.socket()
5 sock.bind(("127.0.0.1",8088))
6 sock.listen(5)
7
8 inp=[sock,] #定義監聽的套接字對象列表,列表列表裏可以有多個對象
9
10 while True:
11 #字段順序:input list 、output list、error list、date(可以不寫)
12 r=select.select(inp,[],[],None) #對比的是sock.accept(),這一步只做了監聽的事情,監聽哪個socket對象活動,當沒有客戶端連接時候會阻塞
13 # 當監聽到有活動的socket對象時候,將返回值給r
14 print(‘r‘,r)
15 print(‘r‘,r[0])
16 #r接收的返回是一個元組,r[0]是活動的對象列表
17
18 for obj in r[0]:
19 if obj == sock: #如果活動的對象是sock,那麽將客戶端對象加入監聽列表,客戶端再發數據時候,觸發客戶端的對象活動
20 conn,addr=obj.accept() #accept只做第二個階段的事情,取回數據:client的socket對象和地址
21 print(conn,addr)
22 inp.append(conn)
23 else:
24 data=obj.recv(1024)
25 print(data.decode(‘utf8‘))
26 resp=input(‘>>>‘)
27 obj.send(resp.encode(‘utf8‘))
28
29 #客戶端
30 import socket
31 sock=socket.socket()
32 sock.connect(("127.0.0.1", 8088))
33 while True:
34 data=input(‘>>>‘).strip()
35 sock.send(data.encode(‘utf8‘))
36 s_data = sock.recv(1024)
37 print(s_data.decode(‘utf8‘))
因為使用的是for循環,當多個客戶端發消息給服務端,只能一個個順序處理。
在windows下只能用select實現多路復用
在Linux可以使用select、poll、epoll實現,推薦使用epoll,對比:
select和poll的監聽方式為輪詢方式,即每次都要循環一遍監聽列表,效率低,另外select有連接數限制,poll無限
epoll連接數無限,區別在於監聽方式不同,每個socket對象綁定一個回調函數,當socket對象活動了就觸發回調函數,把自己寫到活動列表中,epoll直接調用活動列表
信號驅動IO(signal driven IO)
不常用,不做說明
異步IO(Asynchronous I/O)
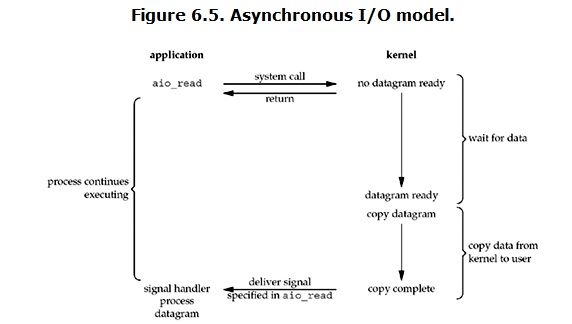
用戶進程發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對用戶進程產生任何block。然後,kernel會等待數據準備完成,然後將數據拷貝到用戶內存,當這一切都完成之後,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
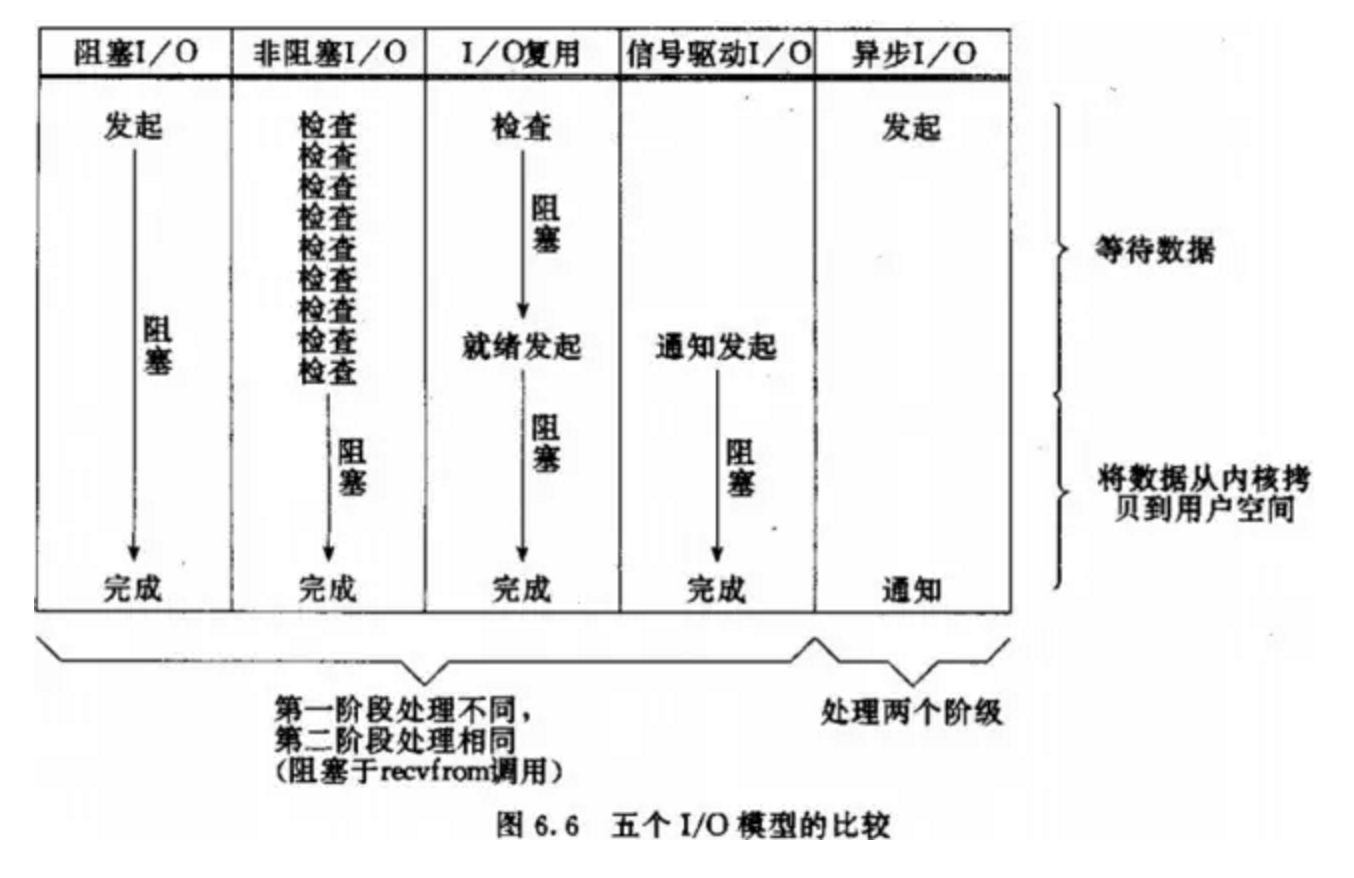
IO模型區別
selectors模塊
該模塊能夠按照系統平臺,自動選擇多路復用的方式。
1 #服務端
2 import selectors
3 import socket
4
5 sel=selectors.DefaultSelector()
6
7 def accept(sock,mask):
8 conn,addr=sock.accept() #4、獲取客戶端的conn對象和地址
9 print(‘accetped‘,conn,‘from‘,addr)
10 conn.setblocking(False)
11 sel.register(conn,selectors.EVENT_READ,read) #5、註冊conn對象,將conn對象和函數read綁定
12
13 def read(conn,mask):
14 data=conn.recv(1024) #9、服務端通過conn對象接收消息,進行下面的邏輯處理
15 if data:
16 print(‘echoing‘,repr(data),‘to‘,conn)
17 conn.send(data)
18 else:
19 print(‘closing‘,conn)
20 sel.unregister(conn)
21 conn.close()
22
23 sock=socket.socket()
24 sock.bind((‘127.0.0.1‘,8088))
25 sock.listen(100)
26 sock.setblocking(False)
27 sel.register(sock,selectors.EVENT_READ,accept) #sock對象註冊綁定accept函數
28
29 while True:
30 #不管是哪個方式,都是使用select方法監聽活動的socket對象
31 events=sel.select() #1、執行sel阻塞監聽,當有客戶端連接,激活sock對象,返回一個存放活動sock對象相關信息的列表
32 #6、客戶端通過conn對象發送消息,激活sel監聽列表中的的conn對象,返回一個存放活動conn對象相關信息的列表
33 print(events,type(events))
34 for key,mask in events:
35 print(mask)
36 print(key.data) #socket對象註冊綁定的accept函數
37 print(key.fileobj)
38 callback=key.data #2、取得返回的sock綁定的函數
39 #7、取得返回conn綁定的函數
40 callback(key.fileobj,mask) #3、key.fileobj是sock對象,執行函數
41 #8、執行函數read,並傳入conn對象
42
43
44 #客戶端
45 import socket
46 sock=socket.socket()
47 sock.connect(("127.0.0.1", 8088))
48 while True:
49 data=input(‘>>>‘).strip()
50 sock.send(data.encode(‘utf8‘))
51 s_data = sock.recv(1024)
52 print(s_data.decode(‘utf8‘))
python基礎之IO模型