
python學習_day39_並發編程之IO模型
對於一個network IO (這裏我們以read舉例),它會涉及到兩個系統對象,一個是調用這個IO的process (or thread),另一個就是系統內核(kernel)。當一個read操作發生時,該操作會經歷兩個階段:等待數據準備 (Waiting for the data to be ready);將數據從內核拷貝到進程中(Copying the data from the kernel to the process)。常見主要IO模型介紹如下:
一、阻塞IO(blocking IO)
在linux中,默認情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣: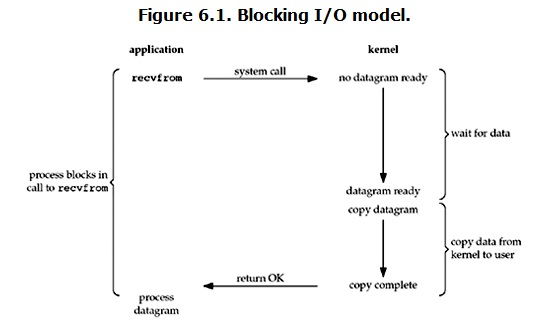
當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據。對於network io來說,很多時候數據在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的數據到來。
而在用戶進程這邊,整個進程會被阻塞。當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然後kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
實際上,除非特別指定,幾乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的。這給網絡編程帶來了一個很大的問題,如在調用recv(1024)的同時,線程將被阻塞,在此期間,線程將無法執行任何運算或響應任何的網絡請求。解決此辦法我們之前曾使用開多進程、多線程,進程池、線程池。但是開啟多進程或都線程的方式,在遇到要同時響應成百上千路的連接請求,則無論多線程還是多進程都會嚴重占據系統資源,降低系統對外界響應效率,而且線程與進程本身也更容易進入假死狀態。“線程池”和“連接池”技術也只是在一定程度上緩解了頻繁調用IO接口帶來的資源占用。而且,所謂“池”始終有其上限,當請求大大超過上限時,“池”構成的系統對外界的響應並不比沒有池的時候效果好多少。所以使用“池”必須考慮其面臨的響應規模,並根據響應規模調整“池”的大小。
對應上例中的所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“線程池”或“連接池”或許可以緩解部分壓力,但是不能解決所有問題。總之,多線程模型可以方便高效的解決小規模的服務請求,但面對大規模的服務請求,多線程模型也會遇到瓶頸,可以用非阻塞接口來嘗試解決這個問題。
二、 非阻塞IO(non-blocking IO)
Linux下,可以通過設置socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:
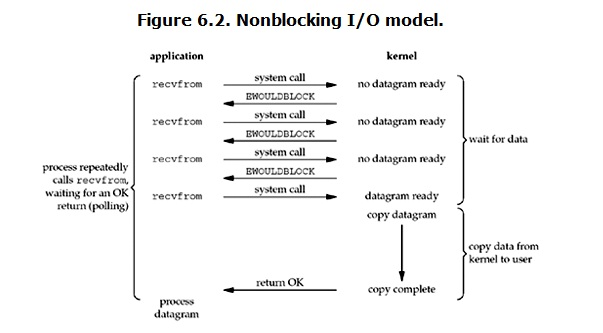
從圖中可以看出,當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那麽它並不會block用戶進程,而是立刻返回一個error。從用戶進程角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,於是用戶就可以在本次到下次再發起read詢問的時間間隔內做其他事情,或者直接再次發送read操作。一旦kernel中的數據準備好了,並且又再次收到了用戶進程的system call,那麽它馬上就將數據拷貝到了用戶內存(這一階段仍然是阻塞的),然後返回。所以,在非阻塞式IO中,用戶進程其實是需要不斷的主動詢問kernel數據準備好了沒有。
實例:
#服務端: from socket import * s=socket() s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((‘127.0.0.1‘,8090)) s.setblocking(False) #設置為非阻塞模式 s.listen(5) conn_l=[] while True: try: conn,addr=s.accept() #獲取連接,若遇到阻塞,拋出異常BlockingIOError print(‘獲得連接%s:%s‘ %(addr[0],addr[1])) conn_l.append(conn) #將連接成功的conn添加到列表 except BlockingIOError: #拋出此異常後執行以下代碼 del_l=[] print(‘沒有可以連接的‘) for conn in conn_l: #循環連接成功的conn列表進行通信 try: data=conn.recv(1024) if not data: del_l.append(conn) continue conn.send(data.upper()) except BlockingIOError: #若遇到通信阻塞,跳過 pass except ConnectionError: #若遇到連接異常,將次連接加到一個列表 del_l.append(conn) for conn in del_l: #循環刪除掉已經斷開的連接,避免下次再次拋出異常 conn_l.remove(conn) conn.close() #客戶端: from socket import * c=socket(AF_INET,SOCK_STREAM) c.connect((‘127.0.0.1‘,8090)) while True: msg=input(‘>>: ‘) if not msg:continue c.send(msg.encode(‘utf-8‘)) data=c.recv(1024) print(data.decode(‘utf-8‘))
以上非阻塞IO雖然存在降低阻塞的優點,但是也難隱藏其主要兩大缺點:循環調用查詢將大幅提高CPU的占有率;任務完成的響應延遲增大,因為可能剛好查看完成,數據就準備好,但是數據的接收只能等下次的查詢到此連接的時候。故非阻塞IO絕不被推薦。
三、多路復用IO(IO multiplexing)
它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。它的流程如圖:
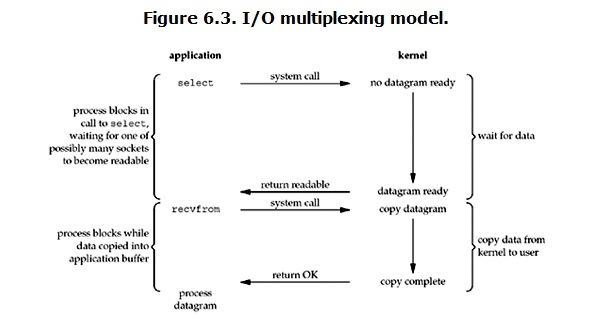
當用戶進程調用了select,那麽整個進程會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。這個圖和blocking IO的圖其實並沒有太大的不同,事實上還更差一些。因為這裏需要使用兩個系統調用(select和recvfrom),而blocking IO只調用了一個系統調用(recvfrom)。但是,用select的優勢在於它可以同時處理多個connection。
在多路復用模型中,對於每一個socket,一般都設置成為non-blocking,但是,如上圖所示,整個用戶的process其實是一直被block的。只不過process是被select這個函數block,而不是被socket IO給block。
實例:
#服務端 from socket import * import select s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((‘127.0.0.1‘,8081)) s.listen(5) s.setblocking(False) #設置socket的接口為非阻塞 read_l=[s,] while True: r_l,w_l,x_l=select.select(read_l,[],[]) print(r_l) for ready_obj in r_l: if ready_obj == s: conn,addr=ready_obj.accept() #此時的ready_obj等於s read_l.append(conn) else: try: data=ready_obj.recv(1024) #此時的ready_obj等於conn if not data: ready_obj.close() read_l.remove(ready_obj) continue ready_obj.send(data.upper()) except ConnectionResetError: ready_obj.close() read_l.remove(ready_obj) #客戶端 from socket import * c=socket(AF_INET,SOCK_STREAM) c.connect((‘127.0.0.1‘,8081)) while True: msg=input(‘>>: ‘) if not msg:continue c.send(msg.encode(‘utf-8‘)) data=c.recv(1024) print(data.decode(‘utf-8‘))
四、異步IO(Asynchronous I/O)
顧名思義,異步就是不會原地等待結果,用戶進程發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對用戶進程產生任何block。然後,kernel會等待數據準備完成,然後將數據拷貝到用戶內存,當這一切都完成之後,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
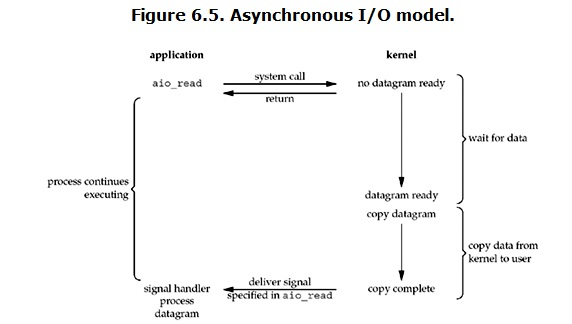
經過上面的介紹,會發現non-blocking IO和asynchronous IO的區別還是很明顯的。在non-blocking IO中,雖然進程大部分時間都不會被block,但是它仍然要求進程去主動的check,並且當數據準備完成以後,也需要進程主動的再次調用recvfrom來將數據拷貝到用戶內存。而asynchronous IO則完全不同。它就像是用戶進程將整個IO操作交給了他人(kernel)完成,然後他人做完後發信號通知。在此期間,用戶進程不需要去檢查IO操作的狀態,也不需要主動的去拷貝數據。
python學習_day39_並發編程之IO模型