
MapReduce編程模型
MapReduce編程模型
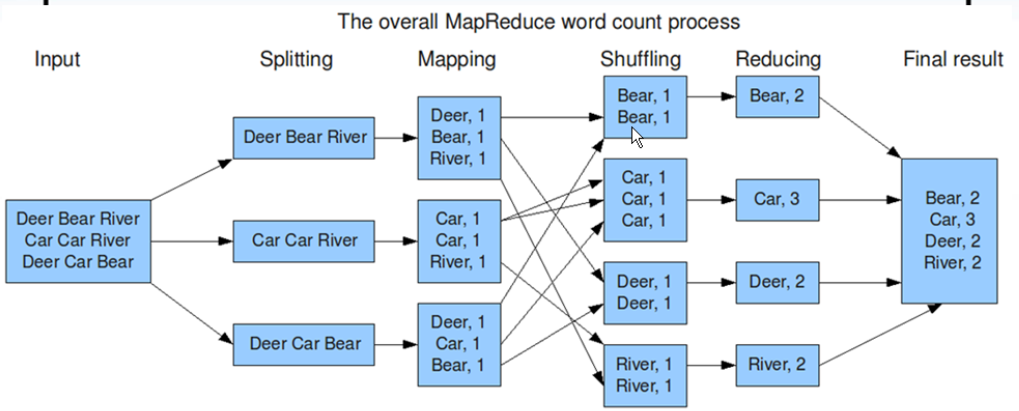
一種分布式計算模型框架,解決海量數據的計算問題
MapReduce將整個並行計算過程抽象到兩個函數
map(映射):對一些獨立元素組成的列表的每一個元素進行指定的操作,可以高度並行
reduce:對一個列表的元素進行合並
一個簡單的MapReduce程序只需要指定map(),reduce(),input和output,剩下的事有框架完成。
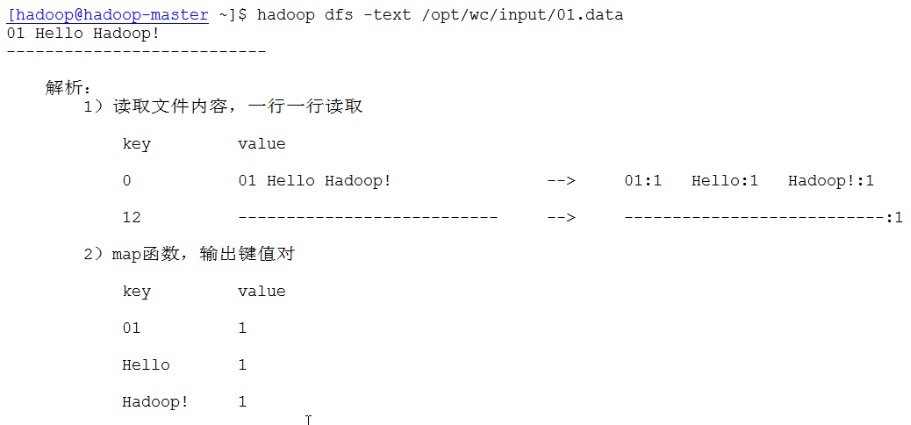
Map Task: 解析每條數據,傳遞給用戶編寫的map().
將map()輸出的數據寫入本地磁盤(如果是map-only作業則直接寫入HDFS)
Reduce Taks:從Map Task上遠程讀取輸入數據,對數據排序,將數據按照分鐘傳遞給用戶編寫的reduce程序
MapReduce編程模型
相關推薦
MapReduce編程模型
.cn map com map() alt 列表 ron 元素 過程 MapReduce編程模型 一種分布式計算模型框架,解決海量數據的計算問題 MapReduce將整個並行計算過程抽象到兩個函數 map(映射):對一些獨立元素組成的列表的每一個元素進行指定的操作,可以
MapReduce編程模型詳解(基於Windows平臺Eclipse)
lib read 找到 lin @override ext logs 設置 otf 本文基於Windows平臺Eclipse,以使用MapReduce編程模型統計文本文件中相同單詞的個數來詳述了整個編程流程及需要註意的地方。不當之處還請留言指出。 前期準備 hadoop集群
MapReduce分布編程模型之函數式編程範式
生產 負責 依賴 獨立 範式 分類 最終 名稱 同時 導讀: 計算機科學是算法與算法變換的科學,算法是計算機科學的基石。 任何一個計算問題的分析與建模,幾乎都可以歸為算法問題。 MapReduce算法模型是由Google公司針對大規模群組中的海量數據處理而提出的分布編程模型
【轉載】MapReduce編程(一) Intellij Idea配置MapReduce編程環境
.net class 上傳 -c word 指定 otl 輸出信息 resource 目錄(?)[-] 一軟件環境 二創建maven工程 三添加maven依賴 四配置log4j 五啟動Hadoop 六運行WordCount從本地讀取文件 七運行Word
Java多線程-並發編程模型
批評 -1 比較 遠程 better cal 術語 java 是我 以下內容轉自http://ifeve.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/: 並發系統可以采用多種並發編程模型來實現。並發
Dataflow編程模型和spark streaming結合
而且 拆分 元組tuple ica 目前 維度 前景 fix 好的 Dataflow編程模型和spark streaming結合 主要介紹一下Dataflow編程模型的基本思想,後面再簡單比較一下Spark streaming的編程模型 == 是什麽 ==
Storm集群組件和編程模型
連接 上傳 應用程序 系統 本地文件 src == 基礎 字段名 Storm工作原理: Storm是一個開源的分布式實時計算系統,常被稱為流式計算框架。什麽是流式計算呢?通俗來講,流式計算顧名思義:數據流源源不斷的
Spark 編程模型(中)
tool irf split exe too rdd count pil 取數 先在IDEA新建一個maven項目 我這裏用的是jdk1.8,選擇相應的骨架 這裏選擇本地在window下安裝的maven 新的項目創建成功 我的開始pom.xml
Spark 編程模型(下)
spa pan -s mage 編程 編程模型 rdd alt img
MapReduce編程之Semi Join多種應用場景與使用
得出 mon comm exception strong 相關 path 區別 rep Map Join 實現方式一 ● 使用場景:一個大表(整張表內存放不下,但表中的key內存放得下),一個超大表 ● 實現方式:分布式緩存 ● 用法: SemiJoin就是所謂的半
C#異步編程模型
操作 null 參數 編程模型 spa zh-cn 完全 times ras 什麽是異步編程模型 異步編程模型(Asynchronous Programming Model,簡稱APM)是C#1.1支持的一種實現異步操作的編程模型,雖然已經比較“古老”了,但是依然可以學習一
網絡編程模型
1.5 height 編程模型 -1 style lin 網絡編程 網絡 ron 網絡編程:socket套接字 TCP編程模型 udp編程模型 網絡編程模型
SparkStreaming 的編程模型
could not 輸出 receive clas tar there int des .org 依賴管理 基本套路 Dstream輸入源 ---input DStream Dstream輸入源--
MapReduce編程實例5
ont inter 運行 ide comm rabl ron interrupt fileinput 前提準備: 1.hadoop安裝運行正常。Hadoop安裝配置請參考:Ubuntu下 Hadoop 1.2.1 配置安裝 2.集成開發環境正常。集成開發環境配置請參考 :U
Socket編程模型之完畢port模型
value result received 在那 void 系統性能 dcom 查詢 tails 轉載請註明來源:viewmode=contents">http://blog.csdn.net/caoshiying?vi
4.並發編程模型
class 優化 agents tro ria img 追蹤 rac 種類 並發系統可以采用多種並發編程模型來實現。並發模型指定了系統中的線程如何通過協作來完成分配給它們的作業。不同的並發模型采用不同的方式拆分作業,同時線程間的協作和交互方式也不相同。這篇並發模型教程將會較
暴力破解MD5的實現(MapReduce編程)
pen brush apt ktr 思想 必須 upd 大文件 file 本文主要介紹MapReduce編程模型的原理和基於Hadoop的MD5暴力破解思路。 一、MapReduce的基本原理 Hadoop作為一個分布式架構的實現方案,它的核心思想包括以下幾個方面:HDFS
ASP.NET MVC編程——模型
找到 sage bool pda nbsp 字符串 轉載 存在 wid 1 ViewModel 是一種專門提供給View使用的模型,使用ViewModel的理由是實體或領域模型所包含的屬性比View使用的多或少,這種情況下實體或領域模型不適合View使用。 2模型綁定
MapReduce 編程模板編寫【分析網站基本指標UV】程序
地址 自動 trace spa bool this try reducer CI 1.網站基本指標的幾個概念 PV: page view 瀏覽量 頁面的瀏覽次數,用戶每打開一次頁面就記錄一次。 UV:unique visitor 獨立訪客數 一天內訪問某站點的人數(以coo
大數據MapReduce 編程實戰
大數據 程序員 hadoop MapReduce 編程實戰 一、大數據的起源1、舉例:(1)商品推薦 問題1:大量訂單如何存儲?問題2:大量訂單如何計算?(2)天氣預報: 問題1:大量的天氣數據如何存儲?問題2:大量的天氣數據如何計算? 2、大數據核心的問題: (1)數據的存儲:分布式