
MapReduce框架Hadoop應用(一)
Google對其的定義:MapReduce是一種變成模型,用於大規模數據集(以T為級別的數據)的並行運算。用戶定義一個map函數來處理一批Key-Value對以生成另一批中間的Key-Value對,再定義一個reduce函數將所有這些中間的有相同Key的value合並起來。“Map”(映射)和“Reduce”(簡化)的概念和它們的主要思想都是從函數式編程語言借用而來的,還有從矢量編程語言借來的特性。在實現過程中,需指定一個map函數,用來把一組鍵值對映射成一組新的鍵值對,再指定並發的reduce函數,用來保證所有映射的每一個鍵值對共享相同的鍵組。在函數式編程中認為,應當保持數據不可變性,避免再多個進程或線程間共享數據,這就意味著,map函數雖然很簡單,卻可以通過兩個或多個線程再同一個列表上同時執行,由於列表本身並沒有改變,線程之間互不影響。
MapReduce模型:
Hadoop MapReduce模型主要有Mapper和Reducer兩個抽象類。Mapper主要負責對數據的分析處理,最終轉化為Key-Value的數據結構;Reducer主要負責獲取Mapper出來的結果,對結果進行進一步統計。Hadoop MapReduce 實現存儲的均衡,但為實現計算的均衡,這是其天生的缺陷,因此,通常采用規避的辦法來解決此問題,由程序員來保證。


MapReduce框架構成:

(註:TaskTracker都運行在HDFS的DataNode上)
1、JobClient
用戶編寫的MapReduce程序通過JobClient提交到JobTracker端 ;同時,用戶可通過Client提供的一些接口查看作業運行狀態。在Hadoop內部用“作業” (Job)表示MapReduce程序。一個 MapReduce程序可對應若幹個作業,而每個作業會被分解成若幹個Map/Reduce任務(Task)。每一個Job都會在用戶端通過JobClient類將應用程序以及配置參數Configuration打包成JAR文件存儲在HDFS裏,並把路徑提交到JobTracker的master服務,然後由master創建每一個Task(即MapTask和ReduceTask)並將它們分發到各個TaskTracker服務中去執行。
2、Mapper和Reducer
運行在Hadoop上的MapReduce程序最基本的組成部分包括:一個Mapper和一個Reducer以及創建的JobConf執行程序,其實還可以包括Combiner,Combiner實際上也是Reducer的實現。
3、JobTracker
JobTracker是一個master服務, 主要負責接受Job,並負責資源監控和作業調度。JobTracker 監控所有 TaskTracker 與作業Job的健康狀況,一旦發現失敗情況後,其會將相應的任務轉移到其他節點;同時,JobTracker 會跟蹤任務的執行進度、資源使用量等信息,並將這些信息告訴任務調度器,而調度器會在資源出現空閑時,選擇合適的任務使用這些資源。一般情況應該把JobTracker部署在單獨的機器上。
4、TaskTracker
TaskTracker是運行在多個節點上的slaver服務,會周期性地通過Heartbeat將本節點上資源的使用情況和任務的運行進度匯報給JobTracker,同時接收JobTracker發送過來的命令並執行相應的操作(如啟動新任務、殺死 任務等),即接受作業並負責直接執行每一個任務。
5、JobInprogress
JobClient提交Job後,JobTracker會創建一個JobInProgress來跟蹤和調度這個Job,並把它添加到Job隊列裏。JobInProgress會根據提交的任務JAR中定義的數據集來創建對應的一批TaskInProgress用於監控和調度MapTask,同事創建指定數目的TaskInProgress用於監控和調度ReduceTask。
6、TaskInProgress
JobTracker啟動任務時通過每一個TaskInProgress來運行Task,這時會把Task對象(即MapTask和ReduceTask)序列化寫入相應的TaskTracker服務中,TaskTracker收到後會創建對應的TaskInProgress用於監控和調度該Task。啟動具體的Task進程需要通過TaskInProgress管理,通過TaskRunner對象來運行。TaskRunner會自動裝載任務JAR文件並設置好環境變量後,啟動一個獨立的子進程來執行Task,即MapTask或ReduceTask,但它們不一定在同一個TaskTracker上運行。
7、MapTask和ReduceTask
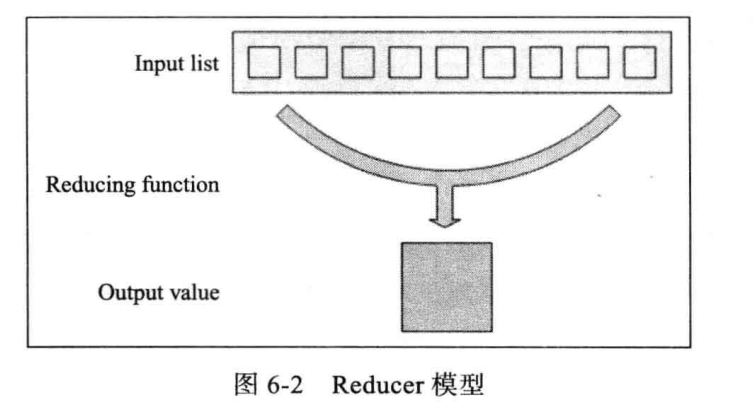
一個完整的Job會自動一次執行Mapper、Combiner(在JonConf指定Combiner時執行)和Reducer。其中,Mapper和Combiner是由MapTask調用執行的,Reducer是由ReduceTask調用執行,Combiner實際上也是Reducer接口類實現的。Mapper會根據Job JAR中定義的輸入數據集按<k1,v1>對讀入,處理完成生成臨時的<k2,v2>對,如果定義了Combiner,MapTask會在Mapper完成調用,該Combiner將相同Key的值做一定的合並處理,以減少輸出結果集。MapTask的任務完成即交給ReduceTask進程調用Reducer處理,生成最終結果<k3,v3>對。下面來看無Combiner的簡單處理:
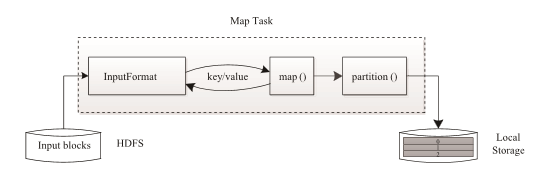
Map Task 執行過程如下圖所示。由該圖可知,Map Task 先將對應的split (MapReduce處理單元)叠代解析成一 個個 key/value 對,依次調用用戶自定義的map() 函數進行處理,最終將臨時結果存放到本地磁盤上,其中臨時數據被分成若幹個partition(分片),每個partition 將被一個Reduce Task處理。
Reduce Task 執行過程如下圖所示。該過程分為三個階段:
①從遠程節點上讀取Map Task 中間結果(稱為“Shuffle階段”);
②按照key對key/value 對進行排序(稱為“Sort階段”);
③依次讀取 <key, value list>,調用用戶自定義的 reduce() 函數處理,並將最終結果存到HDFS上(稱為“Reduce 階段”)。

(註:本文參考:Hadoop應用開發技術詳解)
MapReduce框架Hadoop應用(一)