
Hadoop家族學習路線圖
Hadoop家族學習路線圖
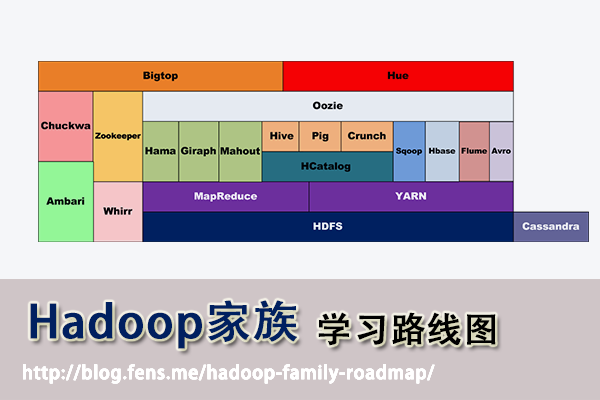
Hadoop家族系列文章,主要介紹Hadoop家族產品,常用的項目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的項目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
從2011年開始,中國進入大數據風起雲湧的時代,以Hadoop為代表的家族軟件,占據了大數據處理的廣闊地盤。開源界及廠商,所有數據軟件,無一不向Hadoop靠攏。Hadoop也從小眾的高富帥領域,變成了大數據開發的標準。在Hadoop原有技術基礎之上,出現了Hadoop家族產品,通過“大數據”概念不斷創新,推出科技進步。
作為IT界的開發人員,我們也要跟上節奏,抓住機遇,跟著Hadoop一起雄起!
關於作者:
- 張丹(Conan), 程序員Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: [email protected]
轉載請註明出處:
http://blog.fens.me/hadoop-family-roadmap/
前言
使用Hadoop已經有一段時間了,從開始的迷茫,到各種的嘗試,到現在組合應用….慢慢地涉及到數據處理的事情,已經離不開hadoop了。Hadoop在大數據領域的成功,更引發了它本身的加速發展。現在Hadoop家族產品,已經達到20個了之多。
有必要對自己的知識做一個整理了,把產品和技術都串起來。不僅能加深印象,更可以對以後的技術方向,技術選型做好基礎準備。
本文為“Hadoop家族”開篇,Hadoop家族學習路線圖
目錄
- Hadoop家族產品
- Hadoop家族學習路線圖
1. Hadoop家族產品
截止到2013年,根據cloudera的統計,Hadoop家族產品已經達到20個!
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
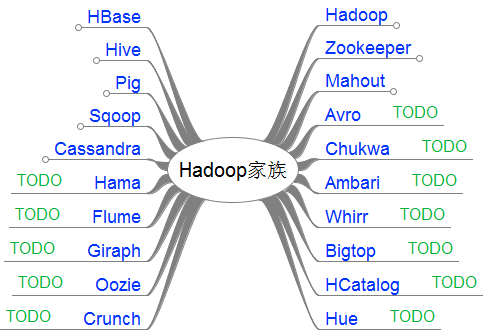
接下來,我把這20個產品,分成了2類。
- 第一類,是我已經掌握的
- 第二類,是TODO準備繼續學習的
一句話產品介紹:
- Apache Hadoop: 是Apache開源組織的一個分布式計算開源框架,提供了一個分布式文件系統子項目(HDFS)和支持MapReduce分布式計算的軟件架構。
- Apache Hive: 是基於Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
- Apache Pig: 是一個基於Hadoop的大規模數據分析工具,它提供的SQL-LIKE語言叫Pig Latin,該語言的編譯器會把類SQL的數據分析請求轉換為一系列經過優化處理的MapReduce運算。
- Apache HBase: 是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲集群。
- Apache Sqoop: 是一個用來將Hadoop和關系型數據庫中的數據相互轉移的工具,可以將一個關系型數據庫(MySQL ,Oracle ,Postgres等)中的數據導進到Hadoop的HDFS中,也可以將HDFS的數據導進到關系型數據庫中。
- Apache Zookeeper: 是一個為分布式應用所設計的分布的、開源的協調服務,它主要是用來解決分布式應用中經常遇到的一些數據管理問題,簡化分布式應用協調及其管理的難度,提供高性能的分布式服務
- Apache Mahout:是基於Hadoop的機器學習和數據挖掘的一個分布式框架。Mahout用MapReduce實現了部分數據挖掘算法,解決了並行挖掘的問題。
- Apache Cassandra:是一套開源分布式NoSQL數據庫系統。它最初由Facebook開發,用於儲存簡單格式數據,集Google BigTable的數據模型與Amazon Dynamo的完全分布式的架構於一身
- Apache Avro: 是一個數據序列化系統,設計用於支持數據密集型,大批量數據交換的應用。Avro是新的數據序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制
- Apache Ambari: 是一種基於Web的工具,支持Hadoop集群的供應、管理和監控。
- Apache Chukwa: 是一個開源的用於監控大型分布式系統的數據收集系統,它可以將各種各樣類型的數據收集成適合 Hadoop 處理的文件保存在 HDFS 中供 Hadoop 進行各種 MapReduce 操作。
- Apache Hama: 是一個基於HDFS的BSP(Bulk Synchronous Parallel)並行計算框架, Hama可用於包括圖、矩陣和網絡算法在內的大規模、大數據計算。
- Apache Flume: 是一個分布的、可靠的、高可用的海量日誌聚合的系統,可用於日誌數據收集,日誌數據處理,日誌數據傳輸。
- Apache Giraph: 是一個可伸縮的分布式叠代圖處理系統, 基於Hadoop平臺,靈感來自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
- Apache Oozie: 是一個工作流引擎服務器, 用於管理和協調運行在Hadoop平臺上(HDFS、Pig和MapReduce)的任務。
- Apache Crunch: 是基於Google的FlumeJava庫編寫的Java庫,用於創建MapReduce程序。與Hive,Pig類似,Crunch提供了用於實現如連接數據、執行聚合和排序記錄等常見任務的模式庫
- Apache Whirr: 是一套運行於雲服務的類庫(包括Hadoop),可提供高度的互補性。Whirr學支持Amazon EC2和Rackspace的服務。
- Apache Bigtop: 是一個對Hadoop及其周邊生態進行打包,分發和測試的工具。
- Apache HCatalog: 是基於Hadoop的數據表和存儲管理,實現中央的元數據和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供關系視圖。
- Cloudera Hue: 是一個基於WEB的監控和管理系統,實現對HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
2. Hadoop家族學習路線圖
下面我將分別介紹各個產品的安裝和使用,以我經驗總結我的學習路線。
Hadoop
- Hadoop學習路線圖
- Yarn學習路線圖
- 用Maven構建Hadoop項目
- Hadoop歷史版本安裝
- Hadoop編程調用HDFS
- 海量Web日誌分析 用Hadoop提取KPI統計指標
- 用Hadoop構建電影推薦系統
- 創建Hadoop母體虛擬機
- 克隆虛擬機增加Hadoop節點
- R語言為Hadoop註入統計血脈
- RHadoop實踐系列之一 Hadoop環境搭建
- 用MapReduce實現矩陣乘法
- PageRank算法並行實現
- PeopleRank從社交網絡中發現個體價值
Hive
- Hive學習路線圖
- Hive安裝及使用攻略
- Hive導入10G數據的測試
- R利劍NoSQL系列文章 之 Hive
- 用RHive從歷史數據中提取逆回購信息
Pig
- Pig學習路線圖
Zookeeper
- Zookeeper學習路線圖
- ZooKeeper偽分步式集群安裝及使用
- ZooKeeper實現分布式隊列Queue
- ZooKeeper實現分布式FIFO隊列
- 基於Zookeeper的分步式隊列系統集成案例
HBase
- HBase學習路線圖
- 在Ubuntu中安裝HBase
- RHadoop實踐系列之四 rhbase安裝與使用
Mahout
- Mahout學習路線圖
- 用R解析Mahout用戶推薦協同過濾算法(UserCF)
- RHadoop實踐系列之三 R實現MapReduce的協同過濾算法
- 用Maven構建Mahout項目
- Mahout推薦算法API詳解
- 從源代碼剖析Mahout推薦引擎
- Mahout分步式程序開發 基於物品的協同過濾ItemCF
- Mahout分步式程序開發 聚類Kmeans
- 用Mahout構建職位推薦引擎
- Mahout構建圖書推薦系統
Sqoop
- Sqoop學習路線圖
Cassandra
- Cassandra學習路線圖
- Cassandra單集群實驗2個節點
- R利劍NoSQL系列文章 之 Cassandra
跟上創新的腳步,不斷堅持:(TODO列表,不定期更新)
Avro, Ambari, Chukwa, Hama, Flume, Giraph, Oozie, Crunch, Whirr, Bigtop, HCatalog, Hue
歡迎大家留言,提出寶貴建議!
轉載請註明出處:
http://blog.fens.me/hadoop-family-roadmap/
Hadoop家族學習路線圖