
Hadoop基礎學習
一、Apache Hadoop 歷史發展
Apache Hadoop 的雛形開始於2002年的 Apache 的 Nutch。Nutch 是一個開源 Java 實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具,包括全文搜索和 Web 爬蟲。
隨後在 2003 年 Google 發表了一篇技術學術論文關於 Google 文件系統(GFS)。GFS 也就是 Google File System,是 Google 公司為了存儲海量搜索數據而設計的專用文件系統。
2004年 Nutch 創始人 Doug Cutting(同時也是 Apache Lucene 的創始人) 基於 Google 的 GFS 論文實現了分布式文件存儲系統名為 NDFS。
2004年 Google 又發表了一篇技術學術論文,向全世界介紹了 MapReduce。2005年 Doug Cutting 又基於 MapReduce,在 Nutch 搜索引擎實現了該功能。
2006年,Yahoo! 雇用了 Doug Cutting,Doug Cutting 將 NDFS 和MapReduce 升級命名為 Hadoop。Yahoo! 開建了一個獨立的團隊給 Goug Cutting 專門研究發展 Hadoop。
2008年1月,Hadoop 成為了 Apache 頂級項目。之後 Hadoop 被成功的應用在了其他公司,其中包括 Last.fm、Facebook、《紐約時報》等。
2008年2月,Yahoo! 宣布其搜索引擎產品部署在一個擁有1萬個內核的 Hadoop 集群上。
2008年4月,Hadoop 打破世界記錄,稱為最快排序1TB數據的系統。
二、分布式與集群區別簡介
分布式:一個業務分拆多個子業務,部署在不同的服務器上
集群:同一個業務,部署在多個服務器上
集群是個物理形態,分布式是個工作方式
分布式是分任務並發處理;集群是同一個任務一起處理。
舉個例子:
小飯店原來只有一個廚師,切菜洗菜備料炒菜全幹。後來客人多了,廚房一個廚師忙不過來,又請了個廚師,兩個廚師都能炒一樣的菜,這兩個廚師的關系是集群。為了讓廚師專心炒菜,把菜做到極致,又請了個配菜師負責切菜,備菜,備料,廚師和配菜師的關系是分布式,一個配菜師也忙不過來了,又請了個配菜師,兩個配菜師關系是集群
三、Hadoop家族產品圖
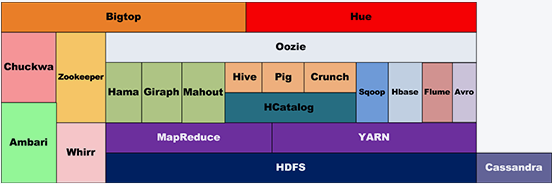
四、Hadoop基本介紹與了解
Hadoop 的框架最核心的設計就是:HDFS 和 MapReduce。HDFS 為海量的數據提供了存儲,而 MapReduce 則為海量的數據提供了計算。
目的是支持從單一服務器到上千臺機器的擴展,充分利用了每臺機器所提供本地計算和存儲,而不是依靠硬件來提供高可用性。
Hadoop三種安裝模式:單機模式,偽分布式,真正分布式
-
單機模式standalone
單機模式是Hadoop的默認模式。當首次解壓Hadoop的源碼包時,Hadoop無法了解硬件安裝環境,便保守地選擇了最小配置。在這種默認模式下所有3個XML文件均為空。當配置文件為空時,Hadoop會完全運行在本地。因為不需要與其他節點交互,單機模式就不使用HDFS,也不加載任何Hadoop的守護進程。該模式主要用於開發調試MapReduce程序的應用邏輯。 -
偽分布模式安裝
tar xzvf hadoop-0.20.2.tar.gz
Hadoop的配置文件:
conf/hadoop-env.sh 配置JAVA_HOME
core-site.xml 配置HDFS節點名稱和地址
hdfs-site.xml 配置HDFS存儲目錄,復制數量
mapred-site.xml 配置mapreduce的jobtracker地址
配置ssh,生成密匙,使到ssh可以免密碼連接
cd /root
ssh -keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys覆蓋公鑰,就能免密碼連接
啟動Hadoop bin/start-all.sh
停止Hadoop bin/stop-all.sh -
完全分布式模式
完全分布式模式就是所要介紹的重點內容了,點擊下一篇隨筆:http://www.cnblogs.com/jichui/p/7137804.html
Hadoop基礎學習