
B+tree索引
- B+Tree索引
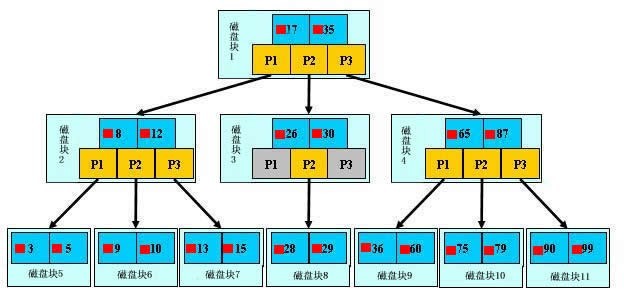
- 如上圖,淺藍色的塊我們稱之為一個磁盤塊,可以看到每個磁盤塊包含幾個數據項(深藍色所示)和指針(黃色所示),如磁盤塊1包含數據項17和35,包含指針P1、P2、P3,P1表示小於17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大於35的磁盤塊。真實的數據存在於葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99, 非葉子節點只不存儲真實的數據,只存儲指引搜索方向的數據項,如17、35並不真實存在於數據表中。
- B+索引在InnoDB和MyISAM中數據分布對比
CREATE TABLE layout_test ( col1 int
NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) );-
假設主鍵的值位於1---10,000之間,且按隨機順序插入,然後用OPTIMIZE TABLE進行優化。col2隨機賦予1---100之間的值,所以會存在許多重復的值。
(1) MyISAM的數據布局
其布局十分簡單,MyISAM按照插入的順序在磁盤上存儲數據,如下:
註:左邊為行號(row number),從0開始。因為元組的大小固定,所以MyISAM可以很容易的從表的開始位置找到某一字節的位置。
據些建立的primary key的索引結構大致如下:
註:MyISAM不支持聚簇索引,索引中每一個葉子節點僅僅包含行號(row number),且葉子節點按照col1的順序存儲。
-
- B+Tree索引
來看看col2的索引結構:

實際上,在MyISAM中,primary key和其它索引沒有什麽區別。Primary key僅僅只是一個叫做PRIMARY的唯一,非空的索引而已。
(2) InnoDB的數據布局
InnoDB按聚簇索引的形式存儲數據,所以它的數據布局有著很大的不同。它存儲表的結構大致如下:

註:聚簇索引中的每個葉子節點包含primary key的值,事務ID和回滾指針(rollback pointer)——用於事務和MVCC,和余下的列(如col2)。
相對於MyISAM,二級索引與聚簇索引有很大的不同。InnoDB的二級索引的葉子包含primary key的值,而不是行指針(row pointers),這減小了移動數據或者數據頁面分裂時維護二級索引的開銷,因為InnoDB不需要更新索引的行指針。其結構 大致如下:

(3)總結:
-主鍵索引/非主鍵索引
葉子節點上均帶有行號,通過行號進行索引
?Innodb-主鍵索引(聚簇索引) 葉子節點上帶有數據
-非主鍵索引(第二索引) 葉子節點上帶有主鍵id
B+tree索引